| 这个项目属于哪个课程 | 2023数据采集与融合技术 (福州大学 - 福州大学计算机与大数据学院) |
|---|---|
| 组名、项目简介 | 组名:你在跟我作队 项目需求:(1)音视频转文字准确性 (2)实时性 (3)多语种支持 (4)扩展性 项目目标:①搭建轻量级网站平台提供交互。②利用大模型及第三方库解析音视频及图片。③性能测试及优化 项目开展技术路线:(1)HTML/CSS/JavaScript前端编写(2)Python flask请求处理、URL路由、模板渲染,快速搭建轻量级交互式web。(3)Whisper大模型解析视频,多语言语音识别、翻译。pytesseract库及Tesseract识别引擎提取图片文字。 |
| 团队成员学号 | 组长:陈星宇 102102135 组员: 冯展 052101102 王剑瑜 102102113 吴钦堋 052106102 李嘉骏 102102122 戴坤松 032004111 |
| 这个项目的目标 | (1)搭建轻量级网站平台。(2)输入视频网址,利用大模型解析视频,将音视频转文字,概括视频主要内容,同时获取评论,提炼观看者对视频内容看法。输入图片网址,提取图片上文字。(3)将上述处理结果通过搭建的web网页进行交互式输入输出。(4)性能测试与优化,提高转文字准确性,实时性,多语种,可扩展性和灵活性 |
| 其他参考文献 | 《语音识别技术的研究与发展》 《基于深度学习的语音识别研究》 《Whisper: A Self-supervised Speech Pre-training Method》 《Large-scale Weakly Supervised Pre-training for Speech Recognition》 《Improving the Robustness of Whisper with Domain-Adaptive Training》 |
项目整体简述
-
致力于构建一个简洁且灵活的Web应用,用于收集待处理的视频和图片的URL。通过利用相关的第三方库和高级模型技术,对这些视频和图片进行深度解析,实现音视频转文本,音视频内容的精炼,以及观众情绪的判断。同时,从图片中提取文本,为后续的数据分析和处理提供便利。最后,通过Web应用将处理结果反馈给用户,帮助他们更有效地理解和利用这些视频和图片资源。
-
完成程度:已成功实现视频抓取和评论提取的爬虫任务,并构建了一个简洁的Web应用。该应用能够以高精度提取视频的文案,并实现对视频核心内容的文字提取。此外,它还能进行简单的舆论解读。
主要参与工作
- 1.构建 Flask 服务器并实现前后端数据交互
- 2.执行数据采集任务,包括视频抓取和评论提取等
- 3.进行数据预处理,包括音频提取、视频转换,及对于提取文字的调试等操作
- 4.执行数据挖掘任务,主要包括调试所使用的 API 调用
主要遇到的问题
- 1.对于Flask 服务器搭建时,由于分工问题对于html文件的接口不熟悉,数据交互有一定困难
- 2.爬虫需要避开需要cookie的页面来遏制定时更新cookie的问题
- 3.对于whiper的模型选择受到了限制,其small以上的模型对于显存要求相对较高(>10GB)设备难以支持
代码展示
- 数据提取以及数据预处理
视频提取
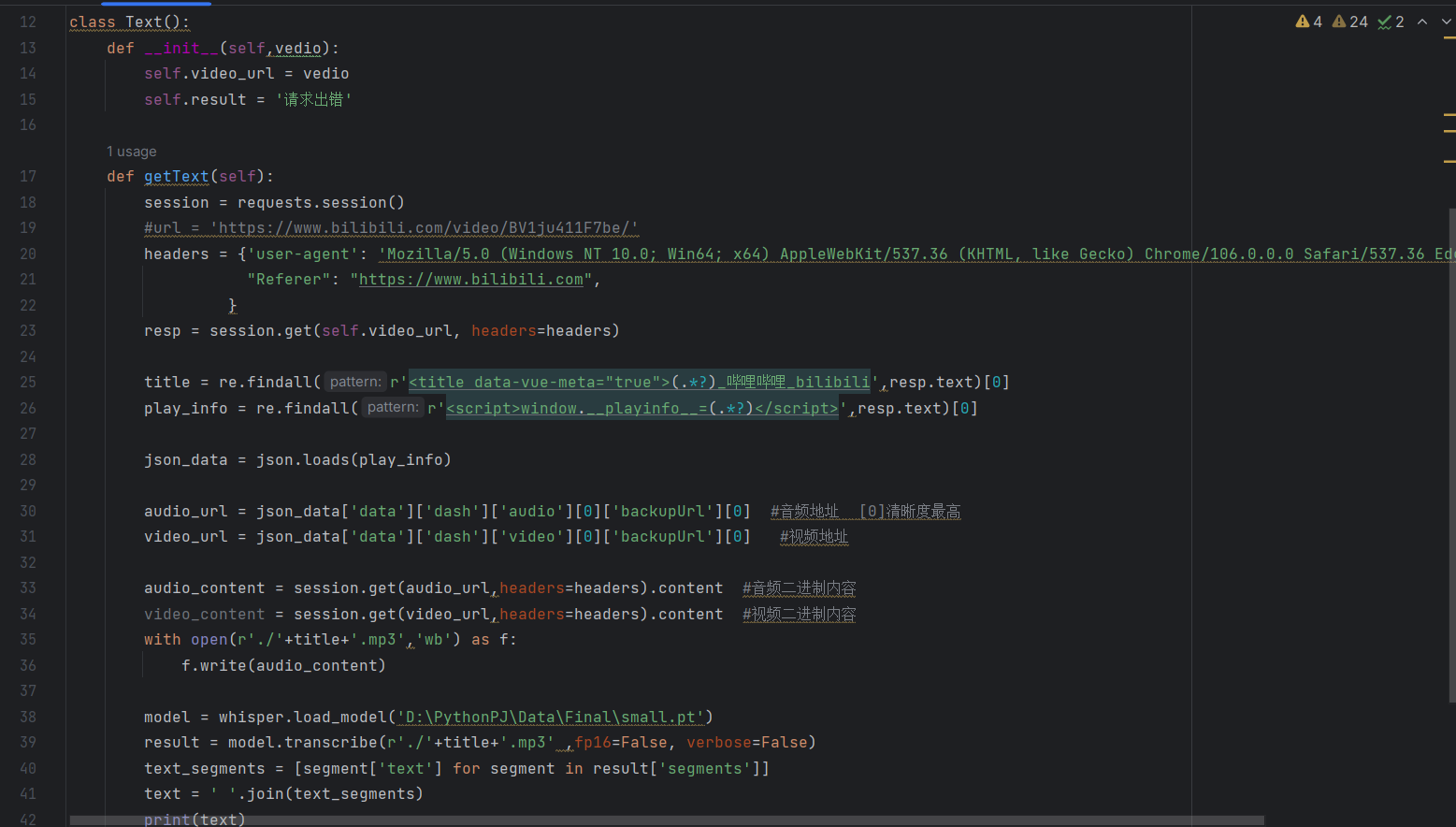
评论提取
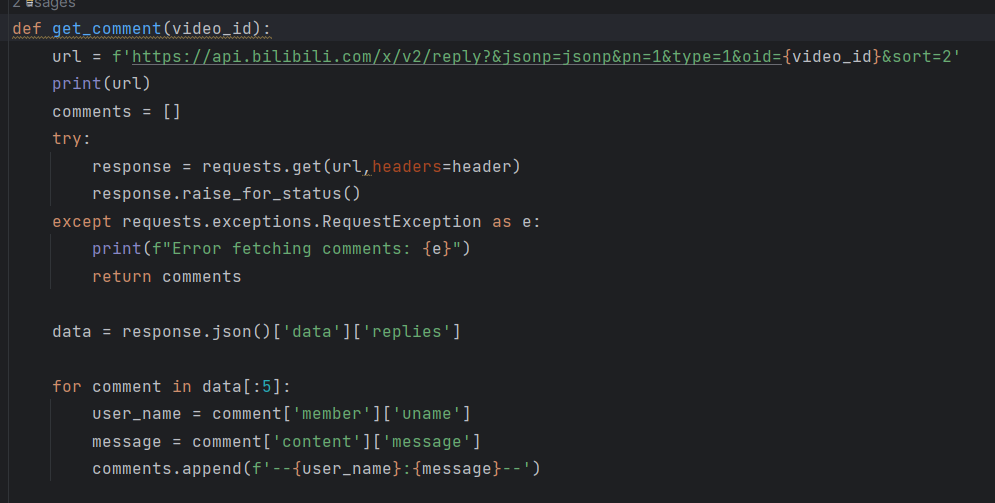
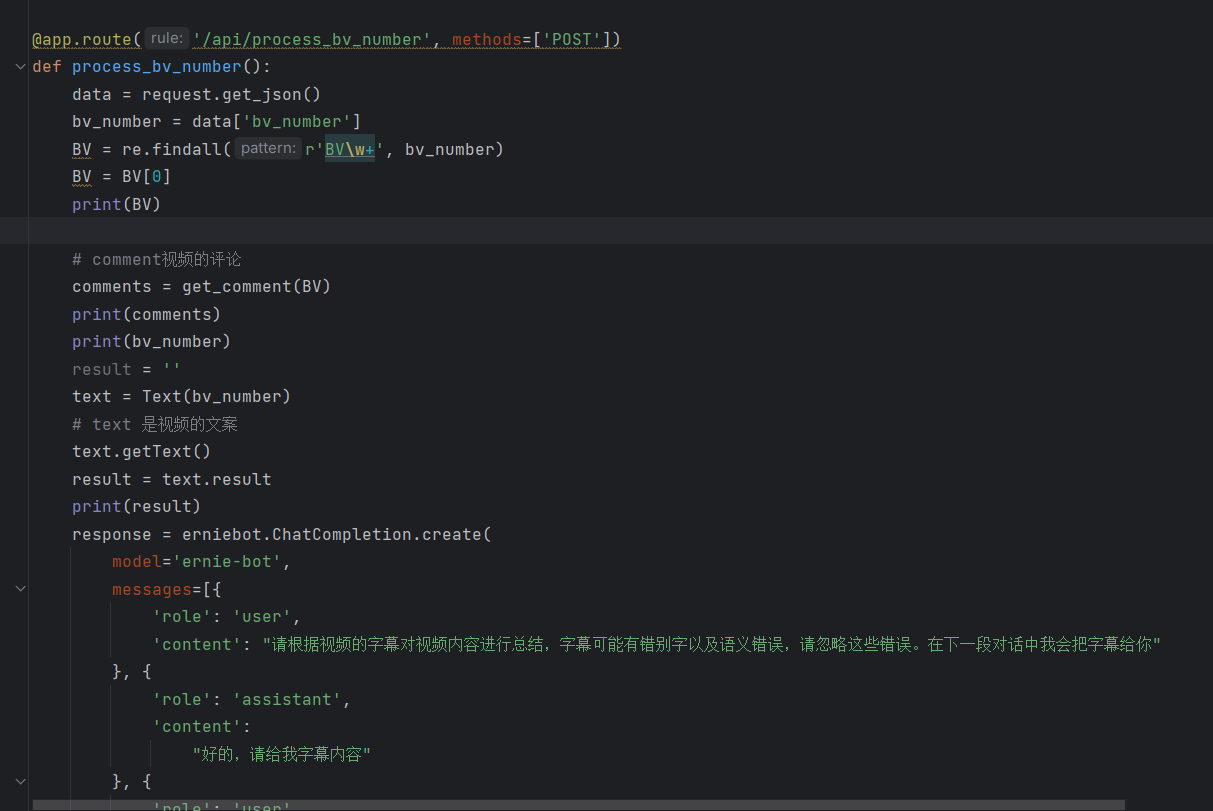
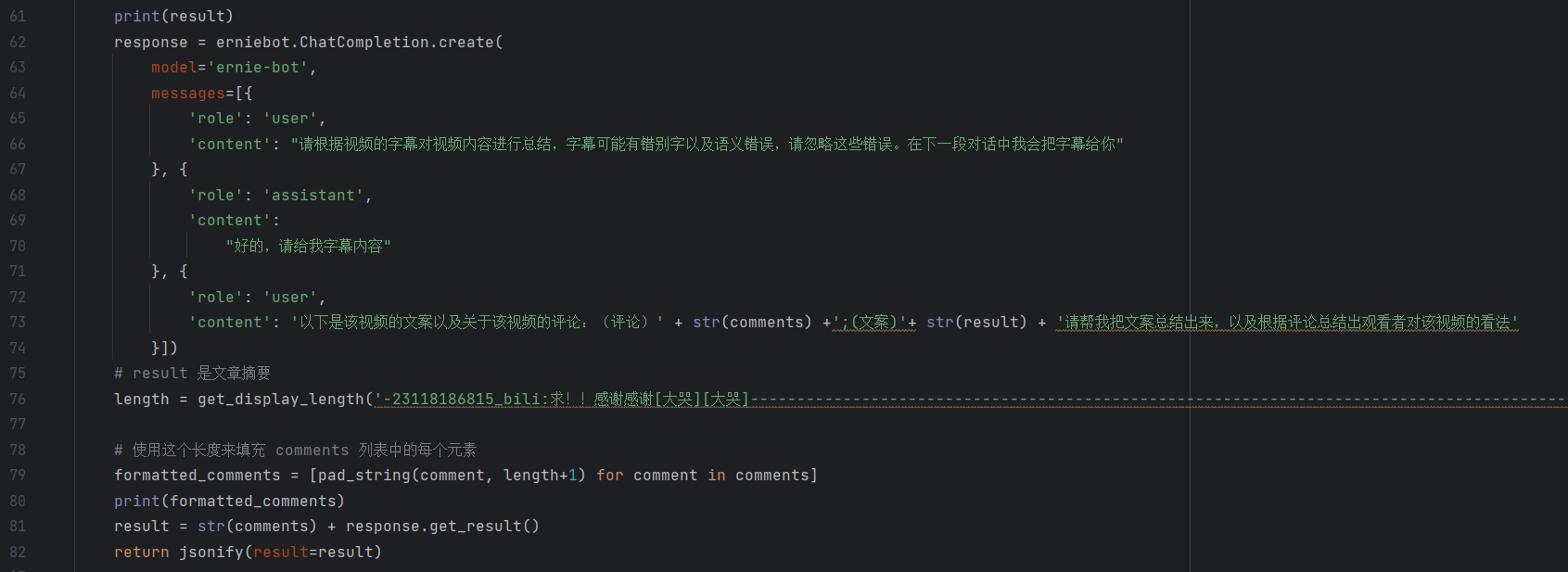
Flask交互的数据处理
实践总结及心得体会
完成了 Flask 端的交互工作,并对前后端交互有了更深入的理解。对于多模态的理解也有所加深,认识到多模态不仅仅是对不同数据类型的分析,更应该实现从不同模态的输入到相同功能的输出。尽管在本次任务中,这一目标并未完全实现,但这为未来的学习提供了方向。个人对于大模型的调用和参数调整也有了更深的理解。就目前而言,各种开源大模型的功能都非常强大,在算力有限的情况下,我认为学习如何调整参数,来使模型更适应任务需求,将是一项更有意义的事情。