softmax回归的简洁实现
通过深度学习框架的高级API能够使实现softmax回归模型更方便地实现
继续使用Fashion-MNIST数据集,并保持批量大小为256。
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
初始化模型参数
softmax回归的输出层是一个全连接层。
为了实现我们的模型, 我们只需在Sequential中添加一个带有10个输出的全连接层。 同样,在这里Sequential并不是必要的, 但它是实现深度模型的基础。 我们仍然以均值0和标准差0.01随机初始化权重。
# PyTorch不会隐式地调整输入的形状。因此,
# 我们在线性层前定义了展平层(flatten),来调整网络输入的形状
###nn.Flatten():展平层
###nn.Linear():全连接层 有784(28x28)个输入特征,输出10个类别
##定义网络模型
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 10))
###初始化全连接层权重
def init_weights(m):
###若这个模块是全连接层,
if type(m) == nn.Linear:
###将全连接层的权重元素随机初始化为均值为0,方差为0.01的正态分布
nn.init.normal_(m.weight, std=0.01)
###网络层调用init_weights函数
net.apply(init_weights);
softmax实现
计算了模型的输出,然后将此输出送入交叉熵损失
###定义交叉熵损失函数
loss = nn.CrossEntropyLoss(reduction='none')
###nn.CrossEntropyLoss() 是 PyTorch 中的一个损失函数,用于多分类问题。它结合了 nn.LogSoftmax() 和 nn.NLLLoss() 两个函数,可以用于解决分类问题。
##在 nn.CrossEntropyLoss() 中,输入张量 y_pred 表示模型的预测值,即真实标签。
##reduction 参数指定了损失函数的处理方式,可以设置为"none"(默认)则表示不进行任何处理,即不考虑损失函数的值
###用于多分类问题的重要损失函数,可以用于评估模型的预测结果与真实标签之间的差异,并用于优化模型的参数。
优化算法
###使用学习率为0.1的小批量随机梯度下降作为优化算法。
trainer = torch.optim.SGD(net.parameters(), lr=0.1)
训练
###训练次数
num_epochs = 10
###开始训练
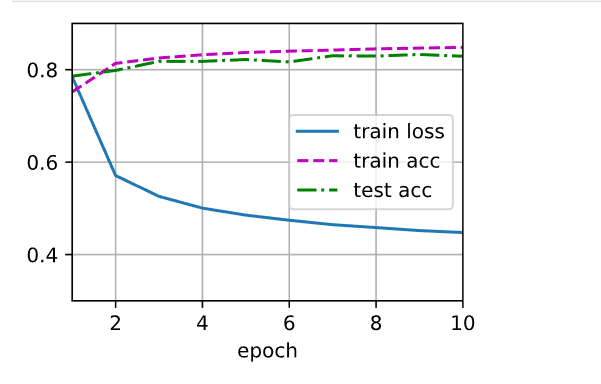
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)