AnoShift: A Distribution Shift Benchmark for Unsupervised Anomaly Detection
主要贡献点:
- 用t-SNE,Optimal Transport Dataset Distance 分析了网络流量中用于无监督异常检测任务的大型常用数据集(Kyoto-2006+),并证明其受到分布偏移的影响。
- 我们提出了基于时间顺序的基准测试,重点是根据测试数据与训练集的时间距离来拆分数据,引入了三种测试split:IID、NEAR、FAR(图1)。该基准旨在更好地估计模型的性能,更接近真实世界的表现。
- 我们证明了充分认识到分布偏移可能会比经典的IID训练方法带来表现更好的异常检测模型。当面临分布偏移时,一种基本的蒸馏技术平均可以将性能提升高达3%。
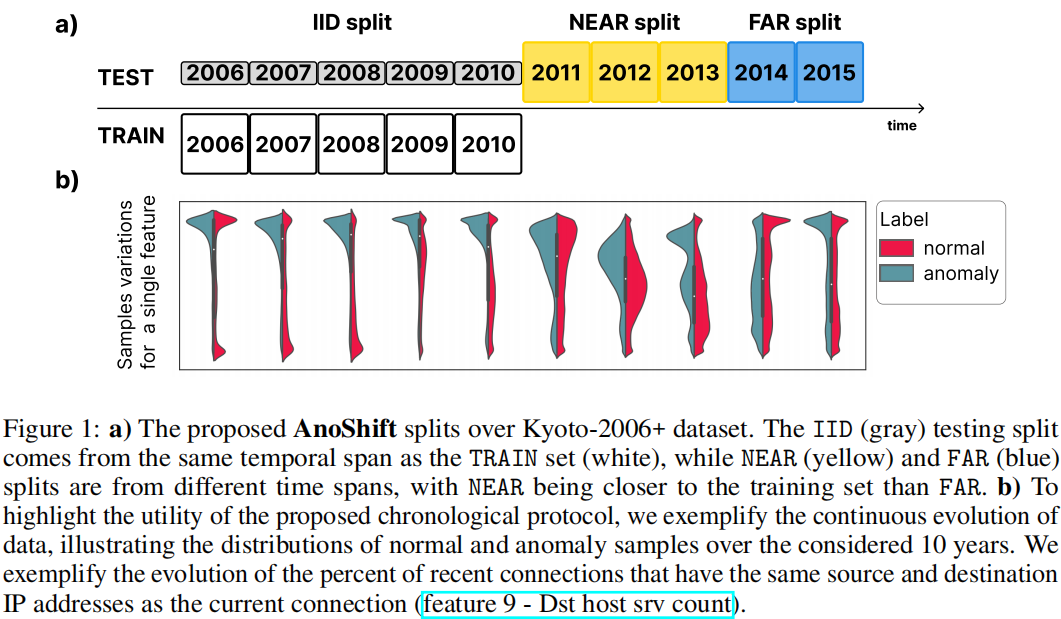
Chronological protocol
考虑到数据的时间戳,我们建议构建一个训练split(TRAIN)以及三个不同的测试split(IID、NEAR 和 FAR),包含多年的数据(图1a)。
- TRAIN 和 IID split都来自第一个时间段,IID 测试应突显在训练和测试之间没有分布偏移时的预期性能。
- NEAR 和 FAR split分别来自不同的时间段,NEAR 更接近训练数据,而 FAR 则更远。我们期望标准模型在NEAR上比FAR表现出更好的性能
据我们所知,AnoShift是第一个为研究异常检测的无监督学习模型的泛化能力提供合适方案的。
Kyoto-2006+
通过设计,与其他异常检测数据集相比,这种类型的数据集具有较大的异常百分比(Kyoto-2006+异常为89.5%)
AnoShift benchmark
为保持网络流量数据的自然分布偏移,我们每年采样固定数量的正常样本(#月数×25k 用于 TRAIN、NEAR 和 FAR,#月数×2.5k 用于 IID)。异常样本的数量受到控制,以保持正常样本与异常样本在原始每年数据子集中的比例。我们在图2中说明了这个过程。
在图1b中,我们展示了在考虑的10年中数据特征的持续演变,对比了一个特征(feature 9 - Dst host srv count)的分布。大多数特征都表现出类似的行为。TRAIN 和 IID 样本采集自 [2006 - 2010],而 NEAR 和 FAR split则包括 [2011 - 2013] 和 [2014 - 2015] 间隔。该方案在图1和图2中有所说明。
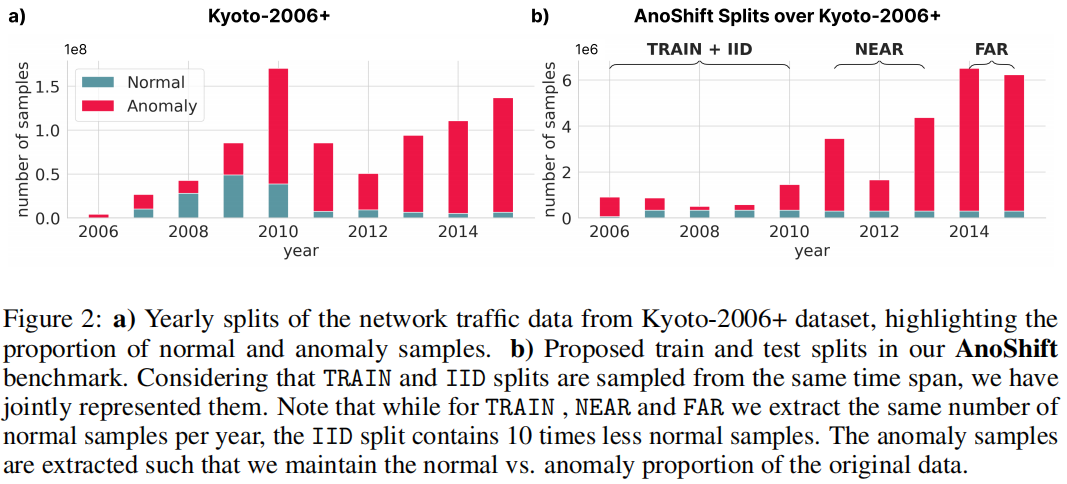
Experimental setup
Metrics for anomaly detection
为了分析各种模型在我们提出的基准测试上的表现,我们使用了Kyoto-2006数据集提供的标签(正常和异常)。由于我们处理的是不平衡的数据集,我们研究了ROC-AUC指标,并且还评估了PR-AUC指标,分别针对正常样本和异常样本(请注意,对于随机分类器,特定类别的PR-AUC接近于该特定类别中数据的比例)。我们将IID、NEAR和FAR的表现报告为它们各自年度split上表现的算术平均值。
Distribution shift analysis
Inherent non-stationarity
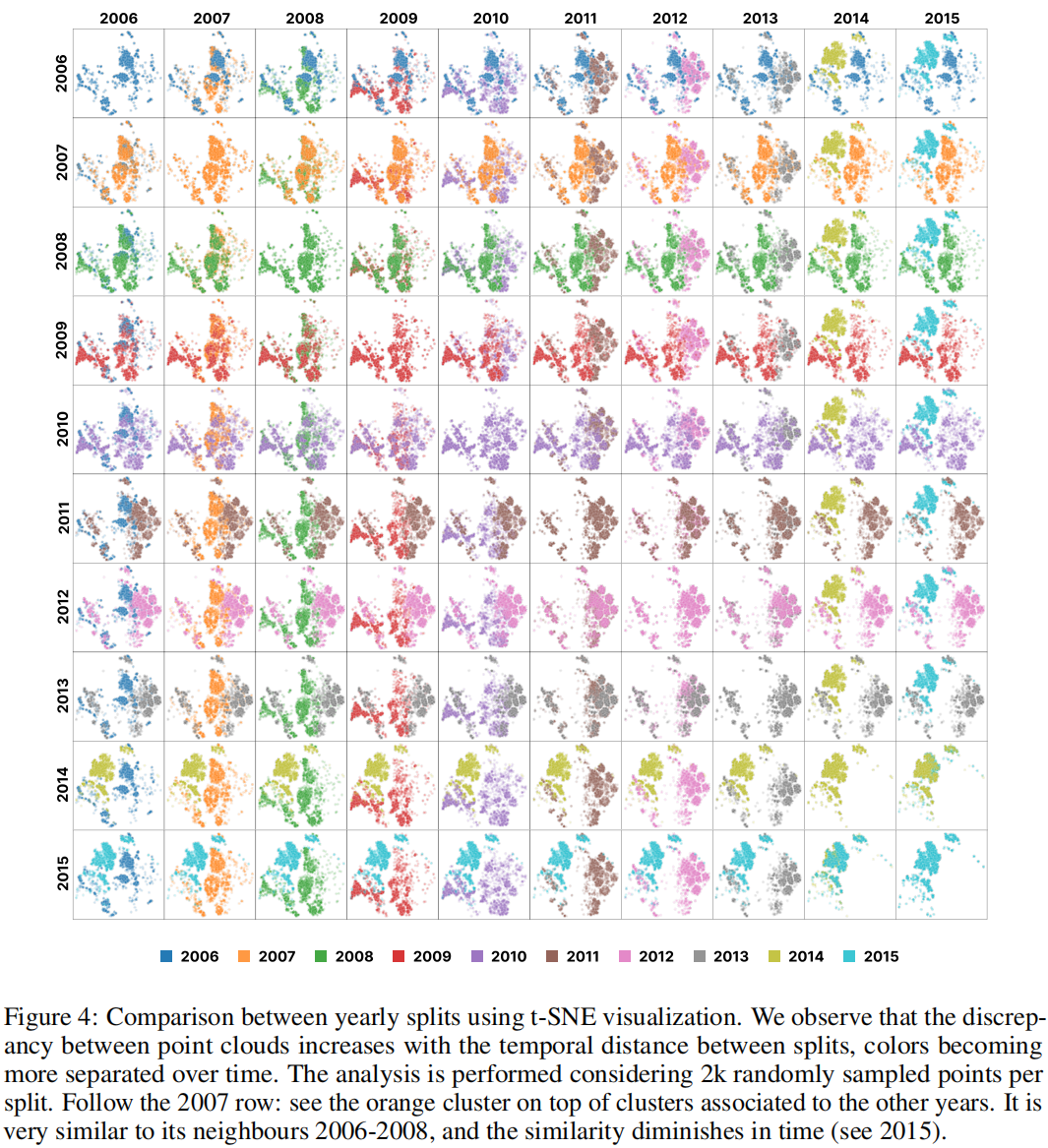
Visualization of the data shifts
使用t-SNE来说明高维数据结构。如图4所示,我们介绍了不同年份数据分布的对比,整个图可以被解释为一个相似性矩阵,每个单元格(i, j)表示第 i 年与第 j 年之间点云的相似性。
我们观察到,随着它们对应年份之间的时间间隔增加,点云会相互移开。这证实了我们的直觉,即分析的网络流量数据在时间上持续变化,并强调了需要一个像 AnoShift 这样的基准测试,以有效地测试模型在这种固有的非平稳自然数据下的鲁棒性。
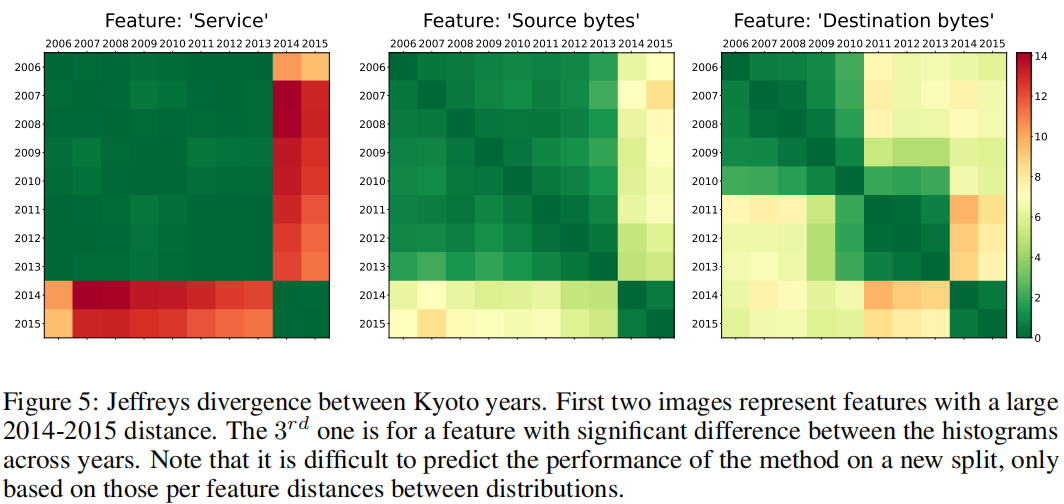
Per-feature shift
我们提取了每个特征每年的归一化直方图,并计算了这些直方图之间的Jeffreys散度。Jeffreys散度是Kullback-Leibler散度的一种常用对称化方法:\(KL(p, q) + KL(q, p)\),其既对称又非负。我们强调,这种分析只能说明简单的情况,从单个特征变化的角度研究分布的变化。
在图5中,我们说明了两个特征的Jeffreys散度,我们发现它们在2014-2015年之间有很大的距离,但第三个特征在其他年份的距离图中也具有显著的高值。
General shift
OTDD依赖于最优传输,这是一种计算概率分布之间距离的几何方法,用于比较数据集。
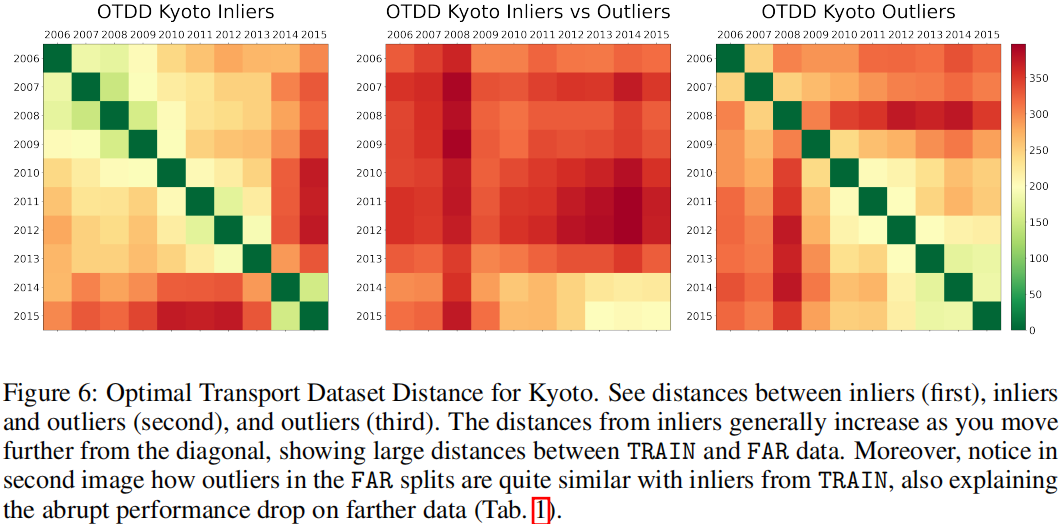
分析显示了 split 随着时间的推移而彼此远离(见图6)。与基于每个特征的方法相比,这种方法给我们一个基于所有特征的单一距离,使我们能够更好地直观地了解 split。
在第一幅图像上,我们观察到 Inliers 在OTDD值上的距离与时间距离直接相关。
在第三幅图像上,outliers在前几年的split中非常不同的。(原文:As for the outliers (third image), it is noticeable that they are quite different between the splits of the first years.)(不太明白)
在第二幅图像上,我们注意到,inliers和outliers之间的距离显示,FAR年份的outliers与TRAIN年份的Inliers相似,我们在表1中证实了这一观察结果,在表1中所有模型都在性能上出现了骤降(低于随机水平)。
(原文:We notice that the distances between inliers and outliers (in the middle) show that FAR years’ outliers are similar to TRAIN years’ inliers, an observation that we empirically confirm in Tab. 1, where all models suffer from a steep descent in performance (bellow random).)(不太明白)
BERT for anomalies
我们使用了一个简化的BERT架构,没有进行预训练,大约有340,000个可训练参数。我们将BERT模型训练为一个掩码语言模型(MLM),使用一个数据收集器随机屏蔽输入序列的一部分(比例为p),损失函数为 模型预测的掩码位置的值与原始标记之间的交叉熵损失函数。我们通过在序列中随机屏蔽一部分(比例为p)的标记,并对分类层给出的掩码位置上正确标记的概率取平均值,来得到一个序列异常分数。在评估时,我们对10次屏蔽采样的分数进行平均。。在我们的实验中,我们使用了p = 15%。
Impact on IID models
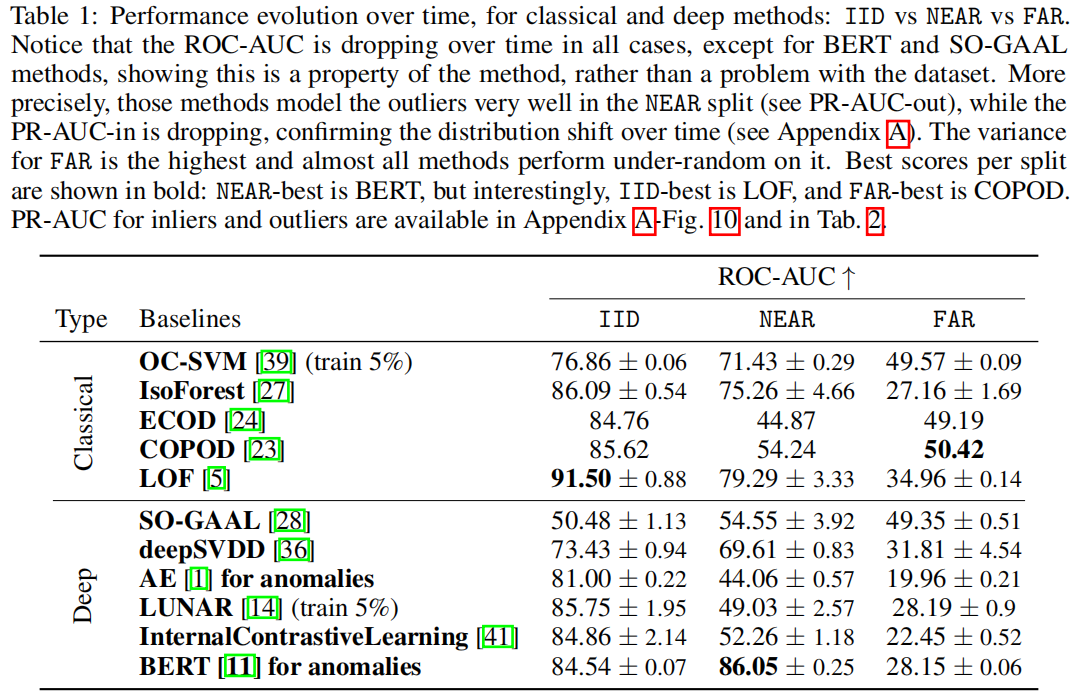
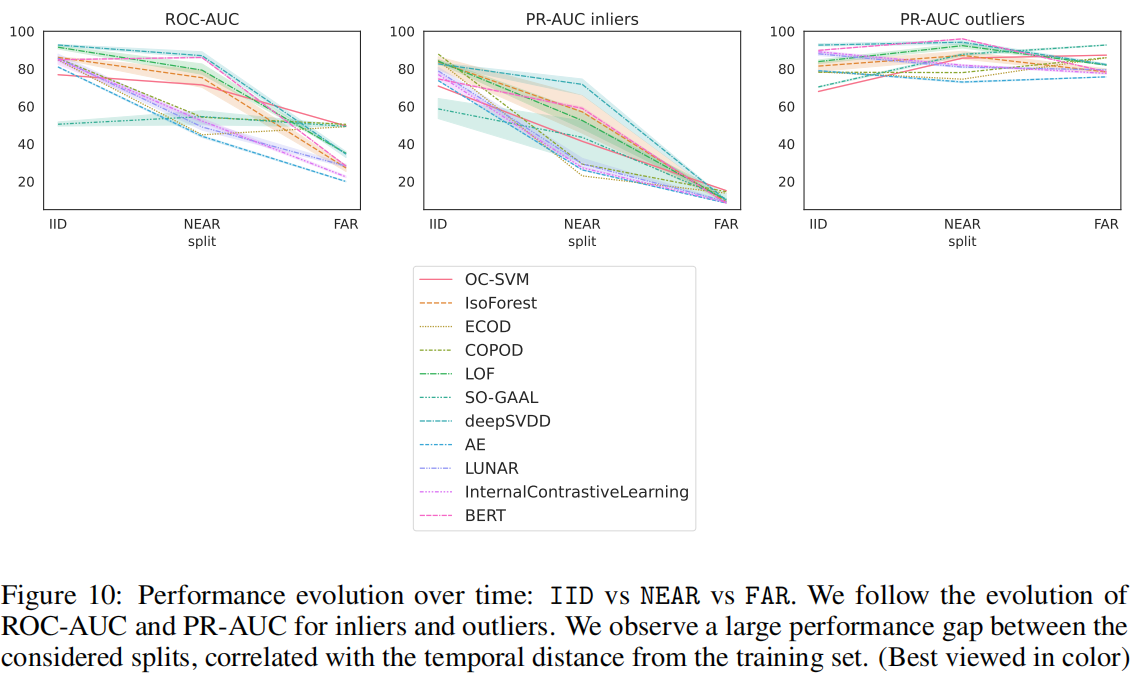
对于所有模型,除了ECOD,我们观察到NEAR和FAR split之间的性能下降,突出表明这些异常检测模型无法应对分布分布偏移。在ECOD的中,NEAR和FAR的性能都低于随机水平,使它们的相对顺序变得无关紧要。IID评估是最流行的方法,但事实证明它会产生高性能的错觉,因为一旦我们考虑来自不同时间段的测试集,性能就会迅速下降。
我们观察到Inliers的PR-AUC快速退化,表明正常数据分布是连续变化的,离群值检测可能不可靠。
Performance on FAR
在所有测试的基准模型中,我们注意到2014年和2015年的inliers检测性能显著下降.
我们观察到2014年和2015年的两个特征( service type和 the number of bytes sent by the source IP)在Jeffreys散度上与其他年份存在较大的差距(见图5)。
从图6的OTDD分析中可以看出:第一,FAR的 Inliers 与 TRAIN的 Inliers 距离很大;其次,FAR的outliers与 TRAIN 的Inliers非常接近(好吧我还是没看出来)
Monthly evaluation
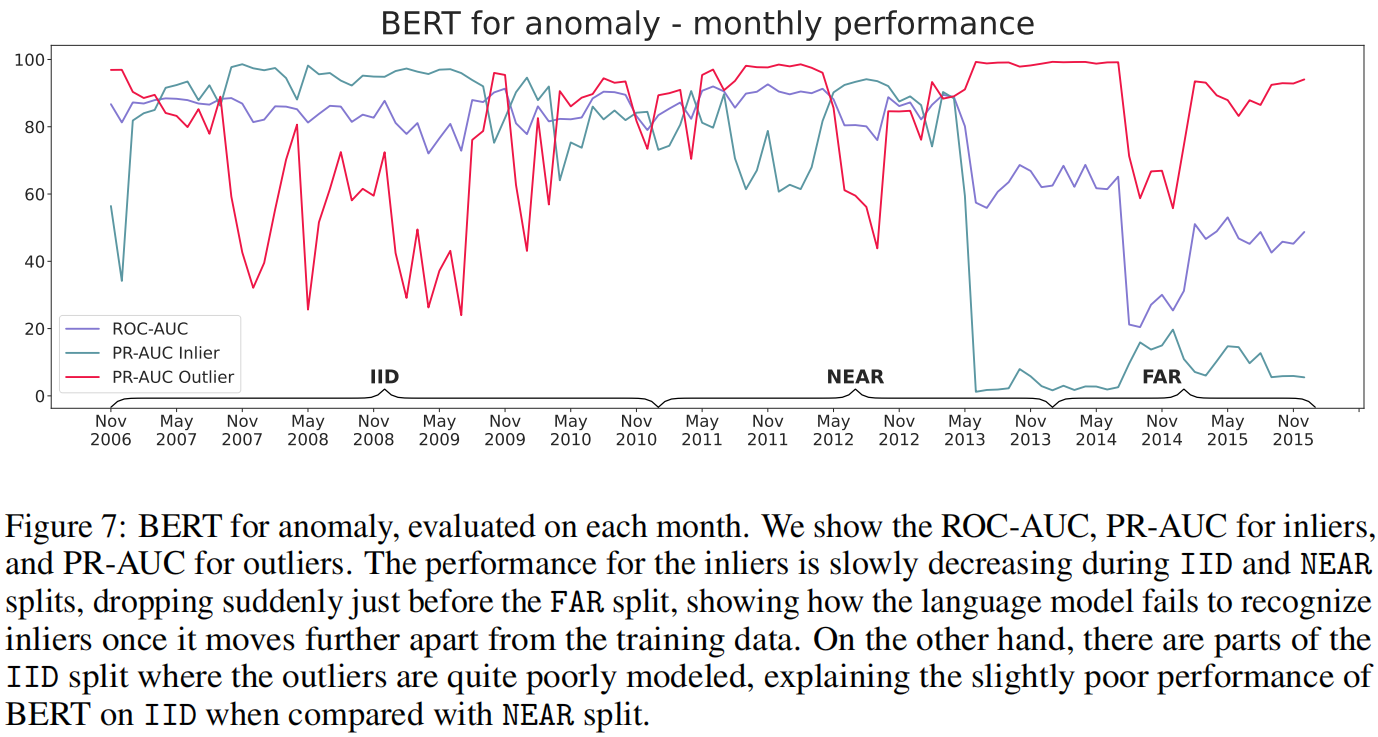
在图7中,我们更详细地观察了BERT在月份粒度上的性能,并将性能分解为inliers和outliers。
首先,注意到inliers的性能随着时间逐渐下降,在更远的月份出现了突然下降。这与我们通过Jeffreys和OTDD实验,得到的TRAIN年份和FAR之间的inliers差异一致。
其次,我们观察到在IID年份,我们的语言模型对异常的建模相当不理想,导致与NEAR相比,IID性能略低。
Addressing the shifted data
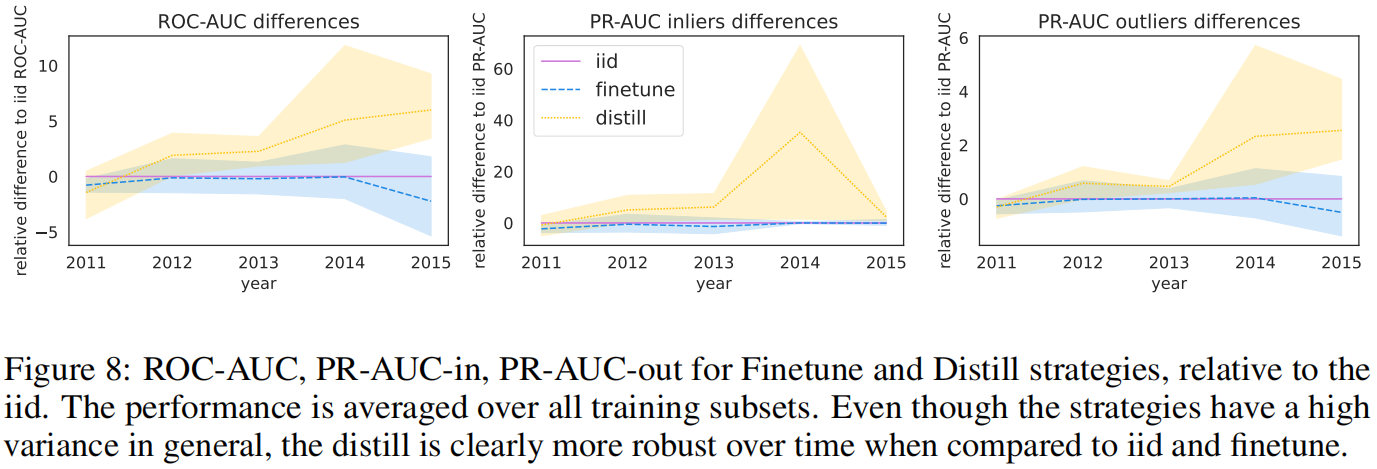
我们比较了BERT模型在三种训练模式下的性能:iid、微调和知识蒸馏,从每年的子集中各选择了300,000条数据。我们使用2006-2010年作为训练数据,并将2011-2015年作为单独的split进行评估。
最终蒸馏模型在每个测试split上均取得了最佳性能(见图8),在ROC-AUC上平均超过iid和微调方法3%以上。值得注意的是,蒸馏的效果随着时间的推移逐渐显现,iid方法在前两次训练splits迭代中的性能优于蒸馏方法。在所有阶段,蒸馏方法在FAR数据上获得了最佳性能,在对抗数据分布偏移方面提供了更强大的训练选择。
Discussions
MLM as anomaly detector
尽管BERT模型在参数数量和复杂性方面远远超过其他传统基准模型,但它在更远的数据上的泛化性能却极低。在我们的情况下,异常性能是基于在样本中预测多个屏蔽特征时的困惑分数。因此,如果特征之间没有相关性,MLM模型可能无法学习到有用的信息,可能会导致学习一些特定的训练集偏差,无法在时间上较远的数据上进行泛化(例如,与其他基准模型相比,在FAR上得分较低)。尽管我们没有对此进行详细调查,但我们认为这是未来工作的一个有趣方向。
MLM with the training vocabulary
在现实世界的设置中,我们预期在训练期间从未见过的标记的比例会随着时间距离的增加而增加。由于在更远的时间点上,预测UNK标记(未知标记)比预测正确的单词更容易,评估分数可能会因将未见过的特征映射到UNK标记而人为地膨胀。与其他传统方法相比,除了需要离散词汇表的要求外,这是基于词汇表的方法的另一个局限性。虽然我们没有对这些影响进行详细调查,但它可能构成未来工作的一个有趣方向。
Other considered datasets
寻找两个对于分布偏移基准测试至关重要的特征:它在足够长的时间跨度内分布,以便自然发生分布偏移,而不是人为注入,同时表现出突然的变化,并且尚未被完全解决(现有方法在其上并不报告完美的分数)。只有Kyoto-2016是一个合适的数据集,它在足够长的时间跨度内展示了自然的分布偏移。