综合设计——多源异构数据采集与融合应用综合实践
| 这个项目属于哪个课程 | 2023数据采集与融合技术 |
|---|---|
| 组名、项目简介 | 组名:Double 20000、项目需求:设计出一个交互友好的多源异构数据的采集与融合的小应用 、项目目标:通过在网页中上传文本、图片、视频或音频分析其中的情感 、项目开展技术路线:前端3件套、Python、fastapi |
| 团队成员学号 | 042101414、052101230、102102104、102102105、102102108、102102111、102102157、102102158 |
| 这个项目目标 | 通过在网页中上传文本、图片、视频或音频分析其中的情感 |
| 其他参考文献 | [1]李慧,庞经纬.基于文图音融合的多模态网民情感识别研究[J/OL].数据分析与知识发现:1-17[2023-12-13].http://kns.cnki.net/kcms/detail/10.1478.g2.20231011.1557.012.html. |
项目整体介绍:
项目名称:多模态情感分析系统
项目背景:在当前的数字化时代,情感分析在各种应用中变得越来越重要,如客户服务、市场分析和社交媒体监控。多模态情感分析能够提供比单一模态更丰富、更准确的情感识别和分析。
项目目标:开发一个多模态情感分析系统,能够处理和分析文本、图片、音频和视频数据,从而提供综合的情感分析结果。
技术路线:
-
前端开发:
-
使用HTML、CSS和JavaScript进行界面设计,实现用户与系统的交互。
-
集成文件上传功能,支持文本、图片、音频和视频文件。
-
-
后端开发:
-
使用Python进行后端逻辑的编写。
-
利用FastAPI框架处理前端请求和数据传输。
-
-
数据处理与分析:
-
文本分析:最开始自己训练模型但是后来因为文心一言的准确率更高,因此采用文心一言的接口进行文本情感分析。
(音频、视频、图片找不到接口,因此自己训练模型)
-
音频分析
- 使用RAVDESS数据集进行训练。
- 对上传的音频文件进行特征提取和情感识别。
-
图片分析:
- 使用VGG模型进行图像处理。
- 利用CK+和FER数据集进行情感分类。
-
视频分析(找不到可以训练视频的模型,最后只能通过提取音频进行分析)
- 提取视频中的音频部分。
- 对提取的音频进行分析,使用同音频分析的方法。
-
-
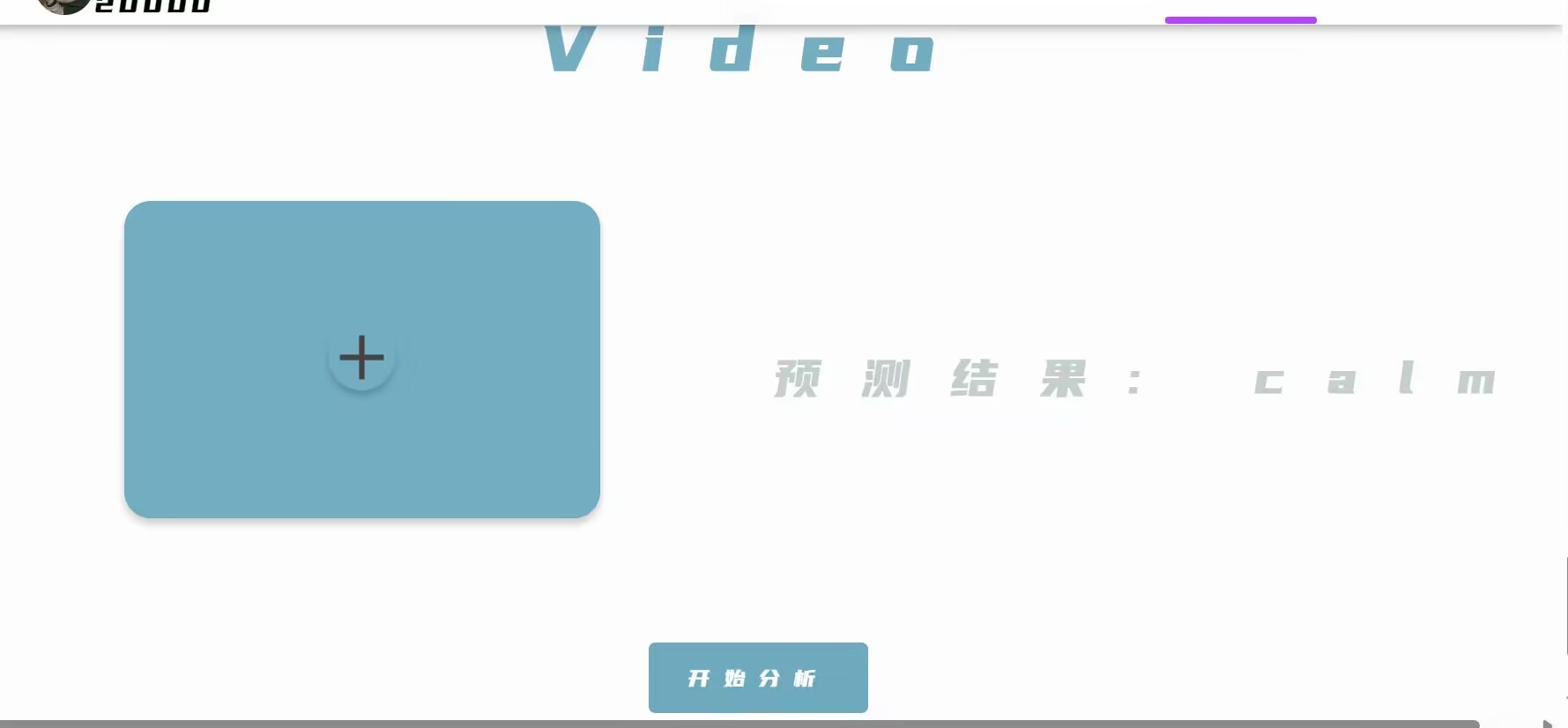
结果输出与展示:将分析结果通过前端界面展示。
最终效果:
通过在本地上传文件进行分析并且得到结果
-
自己的分工
- 本次大作业中,我负责后端的接口撰写和部署,以及音频和文本算法的训练与部署。
- 下面是2个算法的训练过程,取最好的一次参数文件作为预测模型的参数。
这是音频的训练过程
import librosa
import soundfile
import os,glob,pickle
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import accuracy_score
import joblib
def extract_feature(file_name, mfcc, chroma, mel):
with soundfile.SoundFile(file_name) as sound_file:
X = sound_file.read(dtype="float32")
result = np.array([])
sample_rate = sound_file.samplerate
if mfcc:
mfccs = np.mean(librosa.feature.mfcc(y=X, sr=sample_rate, n_mfcc=40).T, axis=0)
result = np.vstack((result, mfccs)) if result.size else mfccs
if chroma:
stft = np.abs(librosa.stft(X))
chroma = np.mean(librosa.feature.chroma_stft(S=stft, sr=sample_rate).T, axis=0)
if chroma.size < mfccs.size: # 调整chroma的维度
chroma = np.pad(chroma, (0, mfccs.size - chroma.size))
else:
chroma = chroma[:mfccs.size]
result = np.vstack((result, chroma)) if result.size else chroma
if mel:
mel = np.mean(librosa.feature.melspectrogram(y=X, sr=sample_rate).T, axis=0)
if mel.size < mfccs.size: # 调整mel的维度
mel = np.pad(mel, (0, mfccs.size - mel.size))
else:
mel = mel[:mfccs.size]
result = np.vstack((result, mel)) if result.size else mel
return result
# 建立数字到情感的映射字典
emotions ={
"01":"neutral",
"02":"calm",
"03":"happy",
"04":"sad",
"05":"angry",
"06":"fearful",
"07":"disgust",
"08":"surprised",
}
observed_emotions = ["neutral",'calm','happy','sad','angry',"fearful"]
def load_data(test_size=0.2):
x,y=[],[]
for file in glob.glob("D:\study\大三上课程资料\数据采集与融合\Audio_Song_Actors_01-24\*\*.wav"):
file_name = os.path.basename(file)
emotion = emotions[file_name.split("-")[2]]
if emotion not in observed_emotions:
continue
feature = extract_feature(file, mfcc=True, chroma=True, mel=True)
x.append(feature)
y.append(emotion)
return train_test_split(np.array(x), y, test_size=test_size, random_state=9)
x_train, x_test, y_train, y_test = load_data(0.25)
print(x_train.shape, len(y_train))
print(f"feature:{x_train.shape[1]}")
model = MLPClassifier(alpha=0.02,
batch_size=256,
activation='relu',
solver='adam',
epsilon=1e-08,
hidden_layer_sizes=(300,),
learning_rate='adaptive',
max_iter=300)
train_model = model.fit(x_train,y_train)
y_pred = model.predict(x_test)
accracy = accuracy_score(y_true=y_test,y_pred=y_pred)
print("Accuracy:{:.2f}%".format(accracy*100))
- 下面是利用fastapi进行后端接口的开发代码
import numpy as np
from fastapi import FastAPI, UploadFile, File
import joblib
import librosa
import soundfile
import os
import shutil
from models import VGG
from PIL import Image
import torch
from torchvision import transforms
from moviepy.editor import *
app = FastAPI()
model_audio = joblib.load('SRE/SEP.h5')
@app.post("/text", tags=["这是文本情感分析测试接口"])
async def text(text_word: str):
import erniebot
erniebot.api_type = 'aistudio'
erniebot.access_token = '1494077bf8be8c621b617186bed49f507ba25829'
text_word = text_word
response = erniebot.ChatCompletion.create(
model='ernie-bot-turbo',
messages=[{
'role': 'user',
'content': text_word + "这句话是什么情感,不需要解析,只要在以下的选项中回答我,开心,平淡,悲伤,只返回如下格式:XX"
}])
return response.get_result()
@app.post("/audio", tags=["这是音频情感分析测试接口"])
async def audio(audio_file: UploadFile = File(...)):
with soundfile.SoundFile(audio_file.file) as sound_file:
X = sound_file.read(dtype="float32")
sample_rate = sound_file.samplerate
# 提取音频特征
mfccs = librosa.feature.mfcc(y=X, sr=sample_rate, n_mfcc=40)
chroma_stft = librosa.feature.chroma_stft(y=X, sr=sample_rate)
mel_spect = librosa.feature.melspectrogram(y=X, sr=sample_rate)
# 假设我们只取每种特征的前N个特征的均值
N = 60 # 根据模型训练情况调整这个值
mfccs_mean = np.mean(mfccs[:N, :], axis=1)
chroma_stft_mean = np.mean(chroma_stft[:N, :], axis=1)
mel_spect_mean = np.mean(mel_spect[:N, :], axis=1)
# 检查特征维度
print(
f"mfccs_shape: {mfccs_mean.shape}, chroma_shape: {chroma_stft_mean.shape}, mel_shape: {mel_spect_mean.shape}")
# 组合特征
result = np.hstack((mfccs_mean, chroma_stft_mean, mel_spect_mean))
# 将结果数组变形为2D,适合模型预测使用
result = result.reshape(1, -1)
# 预测情感
y_pred = model_audio.predict(result)
# 清理保存的临时音频文件
# os.remove(input_file_path)
# os.remove(output_file_path)
# 返回预测结果
return {"prediction": y_pred[0]}
@app.post("/predict-emotion", tags=["这是图片情感分析测试接口"])
async def predict_emotion(file: UploadFile = File(...)):
os.makedirs('file', exist_ok=True)
file_name, file_extension = os.path.splitext(file.filename)
# 构建文件保存路径
file_path = f'file/{file.filename}{file_extension}'
# 使用异步方式保存上传的文件
with open(file_path, "wb") as buffer:
shutil.copyfileobj(file.file, buffer) # 使用shutil模块来保存上传的文件
model = VGG('VGG19')
checkpoint = torch.load(r'CK+_VGG19\1\Best_Test_model.pth')
model.eval()
# 图像预处理
image_path = file_path
image = Image.open(image_path).convert('RGB') # 转换为 RGB
transform = transforms.Compose([
transforms.Resize((44, 44)),
transforms.ToTensor(),
])
input_tensor = transform(image)
input_tensor = input_tensor.unsqueeze(0)
# 推断
with torch.no_grad():
output = model(input_tensor)
# 获取预测结果
_, predicted = torch.max(output.data, 1)
# 类别标签
classes = ['生气', '厌恶', '害怕', '开心', '伤心', '惊讶', '蔑视']
# 打印预测结果
return {"预测类别:": classes[predicted.item()]}
@app.post("/video", tags=["这是视频情感分析测试接口"])
async def video(file: UploadFile = File(...)):
try:
os.makedirs('video', exist_ok=True)
file_name, file_extension = os.path.splitext(file.filename)
# 构建文件保存路径
input_file_path = f'video/{file_name}{file_extension}'
output_file_path = f'video/{file_name}.wav'
# 使用异步方式保存上传的文件
with open(input_file_path, "wb") as buffer:
shutil.copyfileobj(file.file, buffer) # 使用 shutil 模块来保存上传的文件
# 将视频转换为音频文件
video = VideoFileClip(input_file_path)
video.audio.write_audiofile(output_file_path)
# 从音频文件提取特征
with soundfile.SoundFile(output_file_path) as sound_file:
X = sound_file.read(dtype="float32")
sample_rate = sound_file.samplerate
# 提取音频特征
mfccs = librosa.feature.mfcc(y=X, sr=sample_rate, n_mfcc=40)
chroma_stft = librosa.feature.chroma_stft(y=X, sr=sample_rate)
mel_spect = librosa.feature.melspectrogram(y=X, sr=sample_rate)
# 假设我们只取每种特征的前N个特征的均值
N = 60 # 根据模型训练情况调整这个值
mfccs_mean = np.mean(mfccs[:N, :], axis=1)
chroma_stft_mean = np.mean(chroma_stft[:N, :], axis=1)
mel_spect_mean = np.mean(mel_spect[:N, :], axis=1)
# 检查特征维度
print(
f"mfccs_shape: {mfccs_mean.shape}, chroma_shape: {chroma_stft_mean.shape}, mel_shape: {mel_spect_mean.shape}")
# 组合特征
result = np.hstack((mfccs_mean, chroma_stft_mean, mel_spect_mean))
# 将结果数组变形为2D,适合模型预测使用
result = result.reshape(1, -1)
# 预测情感
y_pred = model_audio.predict(result)
# 清理保存的临时音频文件
# os.remove(input_file_path)
# os.remove(output_file_path)
# 返回预测结果
return {"prediction": y_pred[0]}
except Exception as e:
# 清理可能产生的任何临时文件
# if os.path.exists(input_file_path):
# os.remove(input_file_path)
# if os.path.exists(output_file_path):
# os.remove(output_file_path)
# 如果发生异常,返回错误信息
return {"error": str(e)}
if __name__ == "__main__":
import uvicorn
#
# uvicorn.run("main:app", host="0.0.0.0", port=8000, reload=True,
# ssl_keyfile="chenziyang.top.key",ssl_certfile="chenziyang.top.pem")
uvicorn.run("main:app", host="0.0.0.0", port=8000, reload=True)
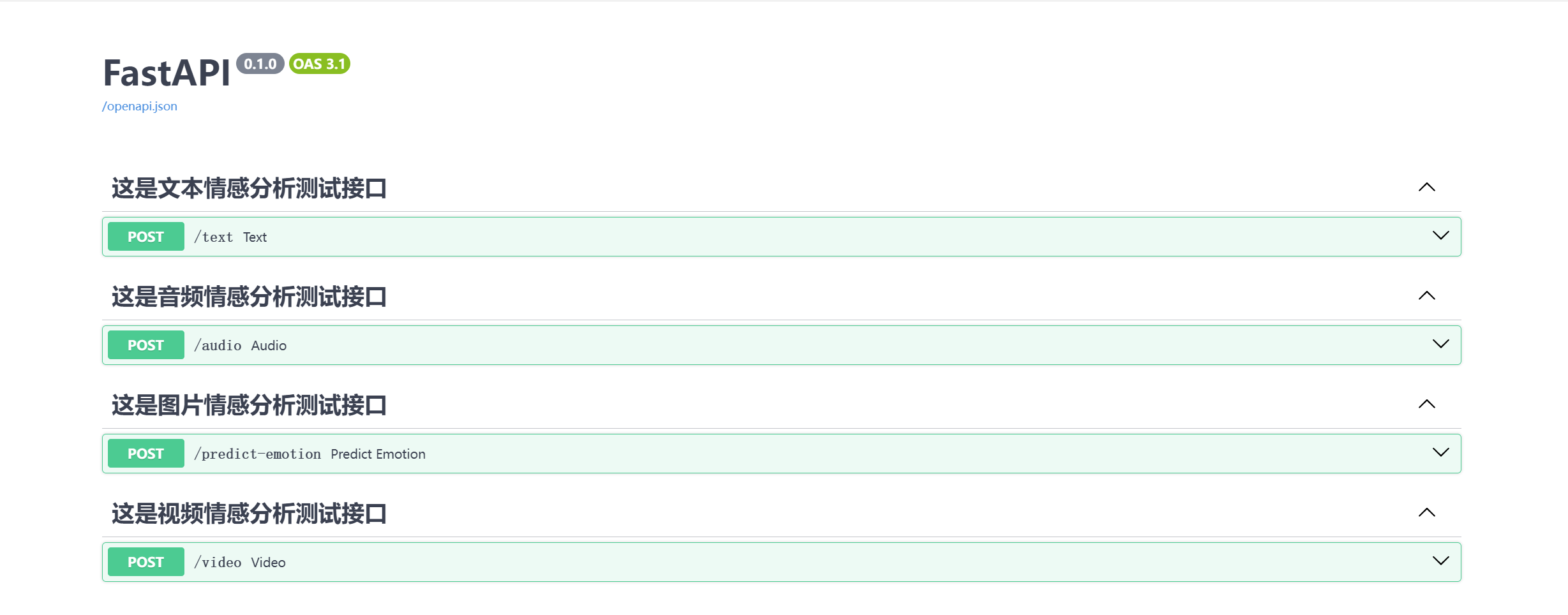
- 上述代码是后端项目结合算法的完整代码。并对前端同学提供了接口文档,这样利于前后端的通信。
- 码云代码文件夹