什么是Flume
Flume是一个高可用,高可靠,分布式的海量日志采集、聚合和传输的系统,能够有效的收集、聚合、移动大量的日志数据。
其实通俗一点来说就是Flume是一个很靠谱,很方便、很强的日志采集工具。他是目前大数据领域数据采集最常用的一个框架
为什么它这么香呢?主要是因为使用Flume采集数据不需要写一行代码,注意是一行代码都不需要,只需要在配置文件中随便写几行配置Flume就会死心塌地的给你干活了,是不是很香?
看这个图,这个属于Flume的一个非常典型的应用场景,使用Flume采集数据,最终存储到HDFS上
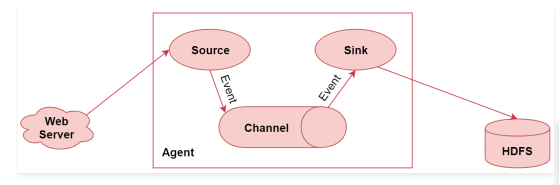
左边的web server表示是一个web项目,web项目会产生日志数据,通过中间的Agent把日志数据采集到HDFS中。其中这个Agent就是我们使用Flume启动的一个代理,它是一个持续传输数据的服务,数据在Agent内部的这些组件之间传输的基本单位是Event
Agent是由Source、Channel、Sink这三大组件组成的,这就是Flume中的三大核心组件,
- source是数据源,负责读取数据
- channel是临时存储数据的,source会把读取到的数据临时存储到channel中
- sink是负责从channel中读取数据的,最终将数据写出去,写到指定的目的地中
Flume的特性
- 它有一个简单、灵活的基于流的数据流结构,这个其实就是刚才说的Agent内部有三大组件,数据通过这三大组件流动的
- 具有负载均衡机制和故障转移机制,这个后面我们会详细分析
- 一个简单可扩展的数据模型(Source、Channel、Sink),这几个组件是可灵活组合的
Flume高级应用场景
一份数据输出到多个目的地中
可以将采集到的一份数据输出到多个目的地中,不同目的地的数据对应不同的业务场景
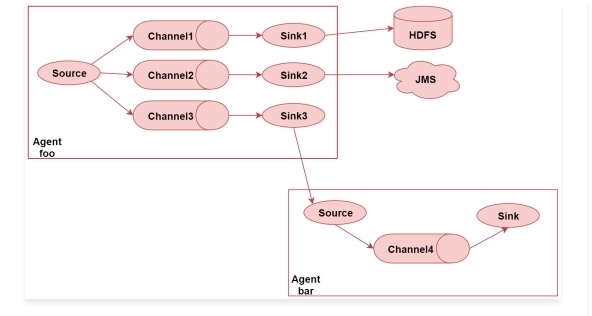
这个图里面一共有两个Agent,表示我们启动了2个Flume的代理,或者可以理解为了启动了2个flume的进程。
首先看左边这个agent,给他起个名字叫 foo
这里面有一个source,source后面接了3个channel,表示source读取到的数据会重复发送给每个channel,每个channel中的数据都是一样的
针对每个channel都接了一个sink,这三个sink负责读取对应channel中的数据,并且把数据输出到不同的目的地,
sink1负责把数据写到hdfs中
sink2负责把数据写到一个Java消息服务数据队列中
sink3负责把数据写给另一个Agent
注意了,Flume中多个Agent之间是可以连通的,只需要让前面Agent的sink组件把数据写到下一个Agent的source组件中即可。
多个Agent采集到的数据统一汇聚到一个Agent
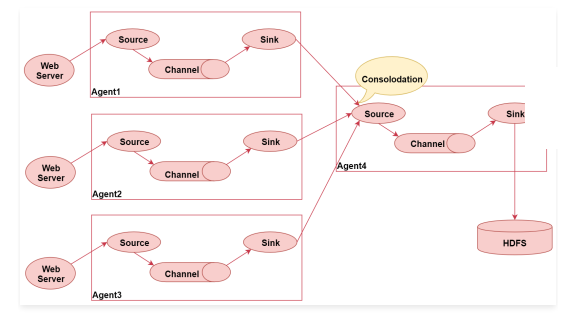
这个图里面一共启动了四个agent,左边的三个agent都是负责采集对应web服务器中的日志数据,数据采集过来之后统一发送给agent4,最后agent4进行统一汇总,最终写入hdfs。
这种架构的好处是后期如果要修改最终数据的输出目的地,只需要修改agent4中的sink即可,不需要修改agent1、2、3。
但是这种架构也有弊端,
- 如果有很多个agent同时向agent4写数据,那么agent4会出现性能瓶颈,导致数据处理过慢
- 这种架构还存在单点故障问题,如果agent4挂了,那么所有的数据都断了。
不过这些问题可以通过flume中的负载均衡和故障转移机制解决,后面我们会详细分析
Flume的三大核心组件
- Source:数据源
- Channel:临时存储数据的管道
- Sink:目的地
Source
数据源:通过source组件可以指定让Flume读取哪里的数据,然后将数据传递给后面的channel
Flume内置支持读取很多种数据源,基于文件、基于目录、基于TCP\UDP端口、基于HTTP、Kafka的等等、当然了,如果这里面没有你喜欢的,也是支持自定义的
常用的几个:
- Exec Source:实现文件监控,可以实时监控文件中的新增内容,类似于linux中的tail -f 效果。
- NetCat TCP/UDP Source: 采集指定端口(tcp、udp)的数据,可以读取流经端口的每一行数据
- Spooling Directory Source:采集文件夹里新增的文件
- Kafka Source:从Kafka消息队列中采集数据
注意了,前面我们分析的这几个source组件,其中execsource 和 kafkasource在实际工作中是最常见的,可以满足大部分的数据采集需求。
在这需要注意 tail -F 和 tail -f 的区别
- tail -F 等同于–follow=name --retry,根据文件名进行追踪,并保持重试,即该文件被删除或改名后,如果再次创建相同的文件名,会继续追踪
- tail -f 等同于–follow=descriptor,根据文件描述符进行追踪,当文件改名或被删除,追踪停止。在实际工作中我们的日志数据一般都会通过log4j记录,log4j产生的日志文件名称是固定的,每天定时给文件重命名
假设默认log4j会向access.log文件中写日志,每当凌晨0点的时候,log4j都会对文件进行重命名,在access后面添加昨天的日期,然后再创建新的access.log记录当天的新增日志数据。这个时候如果想要一直监控access.log文件中的新增日志数据的话,就需要使用tail -F
channel
接受Source发出的数据,可以把channel理解为一个临时存储数据的管道。Channel的类型有很多:内存、文件,内存+文件、JDBC等
- Memory Channel:使用内存作为数据的存储
优点是效率高,因为就不涉及磁盘IO
缺点有两个
1:可能会丢数据,如果Flume的agent挂了,那么channel中的数据就丢失了。
2:内存是有限的,会存在内存不够用的情况 - File Channel:使用文件来作为数据的存储
优点是数据不会丢失
缺点是效率相对内存来说会有点慢,但是这个慢并没有我们想象中的那么慢,所以这个也是比较常用的一种channel。 - Spillable Memory Channel:使用内存和文件作为数据存储,即先把数据存到内存中,如果内存中数据达到阈值再flush到文件中
优点:解决了内存不够用的问题。
缺点:还是存在数据丢失的风险
sink
从Channel中读取数据并存储到指定目的地。Sink的表现形式有很多:打印到控制台、HDFS、Kafka等,
注意:Channel中的数据直到进入目的地才会被删除,当Sink写入目的地失败后,可以自动重写,不会造成数据丢失,这块是有一个事务保证的。
常用的sink组件有:
- Logger Sink:将数据作为日志处理,可以选择打印到控制台或者写到文件中,这个主要在测试的时候使用
- HDFS Sink:将数据传输到HDFS中,这个是比较常见的,主要针对离线计算的场景
- Kafka Sink:将数据发送到kafka消息队列中,这个也是比较常见的,主要针对实时计算场景,数据不落盘,实时传输,最后使用实时计算框架直接处理。
Flume安装部署
下载
Flume是java开发,所以需要依赖jdk环境。下载地址,这里我们使用1.9.0版本。
修改配置文件
在flume的conf目录下,修改flume-env.sh.template的名字,去掉后缀template。
mv flume-env.sh.template flume-env.sh
这个时候我们不需要启动任何进程,只有在配置好采集任务之后才需要启动Flume。
Flume的Hello World!
配置Flume agent的主要流程是这样的
- 给每个组件起名字
- 配置每个组件的相关参数
- 把它们联通起来
编写example.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
注意了,这个配置文件中的a1表示是agent的名称,还有就是port指定的端口必须是未被使用的,可以先查询一下当前机器使用了哪些端口,端口的可用范围是1-65535,如果懒得去查的话,就尽量使用偏大一些的端口,这样被占用的概率就非常低了
bind参数后面指定的ip是四个0,这个当前机器的通用ip,因为一台机器可以有多个ip,例如:
内网ip、外网ip,如果通过bind参数指定某一个ip的话,表示就只监听通过这个ip发送过来的数据了,这样会有局限性,所以可以指定0.0.0.0,表示不限制。
Agent配置好了以后就可以启动了,下面来看一下启动Agent的命令
bin/flume-ng agent --name a1 --conf conf --conf-file conf/example.conf -Dflume.root.logger=INFO,console
bin/flume-ng agent -n a1 -c conf -f example.conf -Dflume.root.logger=INFO,console
指定agent,表示启动一个Flume的agent代理
--name:指定agent的名字 简写-n
--conf:指定flume配置文件的根目录 简写-c
--conf-file:指定Agent对应的配置文件(包含source、channel、sink配置的文件) 简写-f
-D:动态添加一些参数,在这里是指定了flume的日志输出级别和输出位置,INFO表示日志级别
注意了,由于配置文件里面指定了agent的名称为a1,所以在–name后面也需要指定a1,还有就是通过–conf-file指定配置文件的时候需要指定conf目录下的example.conf配置文件。
启动成功之后,这个窗口会被一直占用,因为Agent服务一直在运行,现在属于一个前台进程
使用telnet连接(不能使用windows下的telnet,不能输入信息),如果没有这个命令,使用yum安装
telnet localhost 44444
nohup bin/flume-ng agent --name a1 --conf conf --conf-file conf/example.conf &
后台执行
案例:采集文件内容上传至HDFS
需求:采集目录中已有的文件内容,存储到HDFS
分析:source是要基于目录的,channel建议使用file,可以保证不丢数据,sink使用hdfs
下面要做的就是配置Agent了,可以把example.conf拿过来修改一下,新的文件名为file-to-hdfs.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /root/test_flume/source/studentDir
# Use a channel which buffers events in memory
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /root/test_flume/channel/checkpoint/student
a1.channels.c1.dataDirs = /root/test_flume/channel/data/studentDir/d
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://bigdata01:9000/flume/studentDir
a1.sinks.k1.hdfs.filePrefix = stu
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
首先是source
基于目录的source,前面说过,Spooling Directory Source可以实现目录监控。
接下来是channel
channel在这里使用基于文件的,可以保证数据的安全性。主要配置checkpointDir和dataDir,因为这两个目录默认会在用户家目录下生成,建议修改到其他地方
checkpointDir是存放检查点目录
data是存放数据的目录
最后是sink
因为要向hdfs中输出数据,所以可以使用hdfssink
- hdfs.path是必填项,指定hdfs上的存储目录
- filePrefix参数,这个是一个文件前缀,会在hdfs上生成的文件前面加上这个前缀,这个属于可选项,有需求的话可以加上
- 默认情况下writeFormat的值是Writable,建议改为Text,看后面的解释,如果后期想使用hive或者impala操作这份数据的话,必须在生成数据之前设置为Text,Text表示是普通文本数据
- fileType默认是SequenceFile,还支持DataStream 和 CompressedStream ,DataStream 不会对输出数据进行压缩,CompressedStream 会对输出数据进行压缩,在这里我们先不使用压缩格式的,所以选择DataStream
- hdfs.rollInterval默认值是30,单位是秒,表示hdfs多长时间切分一个文件,因为这个采集程序是一直运行的,只要有新数据,就会被采集到hdfs上面,hdfs默认30秒钟切分出来一个文件,如果设置为0表示不按时间切文件
- hdfs.rollSize默认是1024,单位是字节,最终hdfs上切出来的文件大小都是1024字节,如果设置为0表示不按大小切文件
- hdfs.rollCount默认设置为10,表示每隔10条数据切出来一个文件,如果设置为0表示不按数据条数切文件
hdfs.rollInterval、hdfs.rollSize和hdfs.rollCount这三个参数,如果都设置的有值,哪个条件先满足就按照哪个条件都会执行。在实际工作中一般会根据时间或者文件大小来切分文件,我们之前在工作中是设置的时间和文件大小相结合,时间设置的是一小时,文件大小设置的128M,这两个哪个满足执行哪个。
初始化数据
在启动agent之前,先初始化一下测试数据。创建/root/test_flume/source/studentDir目录,然后在里面添加一个文件,class1.dat,class1.dat中存储的是学生信息,学生姓名、年龄、性别
jack 18 male
jessic 20 female
tom 17 male
启动agent
bin/flume-ng agent --name a1 --conf conf --conf-file conf/file-to-hdfs.conf -Dflume.root.logger=INFO,console
遇到问题
java.lang.NoClassDefFoundError: org/apache/hadoop/io/SequenceFile$CompressionTyp e
at org.apache.flume.sink.hdfs.HDFSEventSink.configure(HDFSEventSink.java :246)
at org.apache.flume.conf.Configurables.configure(Configurables.java:41)
at org.apache.flume.node.AbstractConfigurationProvider.loadSinks(Abstrac tConfigurationProvider.java:453)
at org.apache.flume.node.AbstractConfigurationProvider.getConfiguration( AbstractConfigurationProvider.java:106)
at org.apache.flume.node.PollingPropertiesFileConfigurationProvider$File WatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:145)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:51 1)
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask. access$301(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask. run(ScheduledThreadPoolExecutor.java:294)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor. java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor .java:617)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.io.SequenceFile$C ompressionType
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:331)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 12 more
修改环境变量,配置HADOOP_HOME,修改~/.bash_profile
HADOOP_HOME=/root/test_hadoop/hadoop3.2
PATH=$JAVA_HOME/bin:$PATH:$HOME/bin:$HADOOP_HOME/bin
source .bash_profile
重新启动agent
查看结果
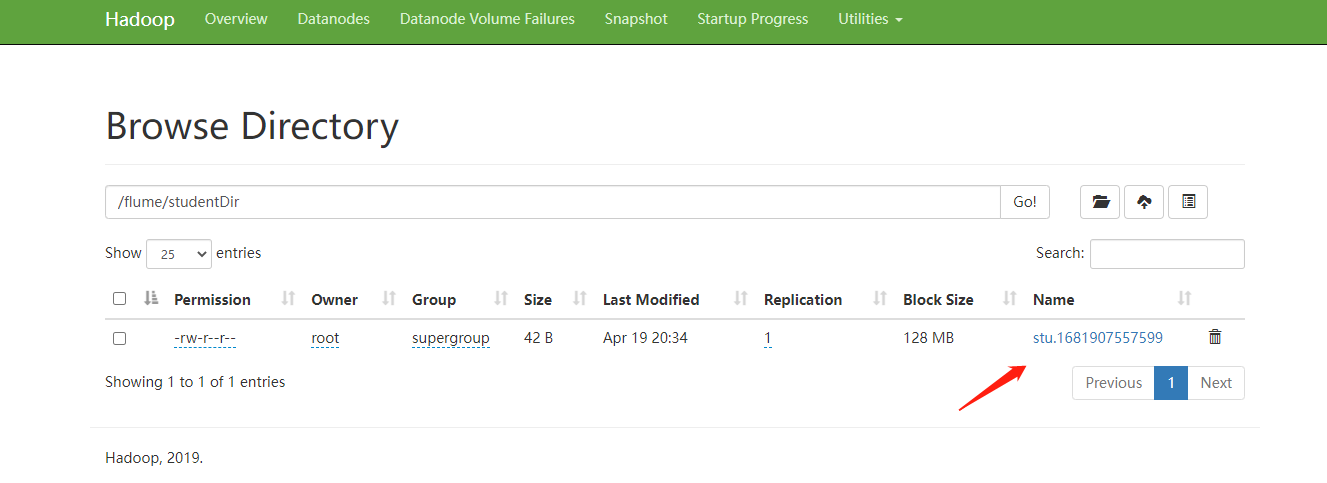
到hdfs上验证结果。
此时发现文件已经生成了,只不过默认情况下现在的文件是 .tmp 结尾的,表示它在被使用,因为Flume只要采集到数据就会向里面写,这个后缀默认是由 hdfs.inUseSuffix 参数来控制的。
文件名上还拼接了一个当前时间戳,这个是默认文件名的格式,当达到文件切割时机的时候会给文件改名字,去掉.tmp
这个文件现在也是可以查看的,里面的内容其实就是class1.dat文件中的内容。
所以此时Flume就会监控linux中的/data/log/studentDir目录,当发现里面有新文件的时候就会把数据采集过来。
那Flume怎么知道哪些文件是新文件呢?它会不会重复读取同一个文件的数据呢?
不会的,我们到/data/log/studentDir目录看一下你就知道了
此时class1.dat这个文件已经被加了一个后缀 .COMPLETED ,表示这个文件已经被读取过了,所以Flume在
读取的时候会忽略后缀为 .COMPLETED 的文件。
现在我们想看一下Flume最终生成的文件是什么样子的,难道要根据配置等待1个小时或者弄一个128M的文件过来吗,
其实也没必要,我们可以暴力操作一下。停止Agent就可以看到了,当Agent停止的时候就会去掉 .tmp 标志了
那我再重启Agent之后,会不会再给加上.tmp呢,不会了,每次停止之前都会把所有的文件解除占用状态,下次启动的时候如果有新数据,则会产生新的文件,这其实就模拟了一下自动切文件之后的效果。
案例:采集网站日志上传至HDFS
这个案例需要多态服务器,资源不足,暂时没有实践。
需求
- 将A和B两台机器实时产生的日志数据汇总到机器C中
- 通过机器C将数据统一上传至HDFS的指定目录中
注意:HDFS中的目录是按天生成的,每天一个目录
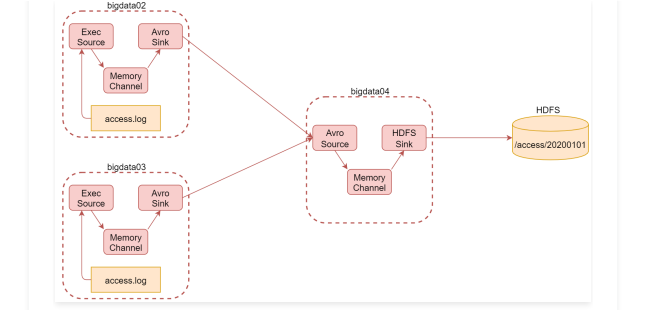
根据刚才的需求分析可知,我们一共需要三台机器
这里使用bigdata02和bigdata03采集当前机器上产生的实时日志数据,统一汇总到bigdata04机器上。
其中bigdata02和bigdata03中的source使用基于file的source,ExecSource,因为要实时读取文件中的新增数据
channel在这里我们使用基于内存的channel,因为这里是采集网站的访问日志,就算丢一两条数据对整体结果影响也不大,我们只希望采集到的数据可以快读进入hdfs中,所以就选择了基于内存的channel。
由于bigdata02和bigdata03的数据需要快速发送到bigdata04中,为了快速发送我们可以通过网络直接传输,sink建议使avrosink,avro是一种数据序列化系统,经过它序列化的数据传输起来效率更高,并且它对应的还有一个avrosource,avrosink的数据可以直接发送给avrosource,所以他们可以无缝衔接。
这样bigdata04的source就确定了 使用avrosource、channel还是基于内存的channel,sink就使用hdfssink,因为是要向hdfs中写数据的。这里面的组件,只有execsource、avrosource、avrosink我们还没有使用过,其他的组件都使用过了。
最终需要在每台机器上启动一个agent,启动的时候需要注意先后顺序,先启动bigdata04上面的,再启动bigdata02和bigdata03上面的。
配置bigdata02上的Agent
创建文件 file-to-avro-bigdata02.conf
# agent的名称是a1
# 指定source组件、channel组件和Sink组件的名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# 配置source组件
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /root/test_flume/source/log/access.log
# 配置channel组件
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 配置sink组件
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = 0.0.0.0
a1.sinks.k1.port = 45454
# 把组件连接起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
这里面的配置没有特殊配置,直接参考官网文档就可以搞定
配置bigdata03上的Agent
# agent的名称是a1
# 指定source组件、channel组件和Sink组件的名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# 配置source组件
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /root/test_flume/source/log/access.log
# 配置channel组件
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 配置sink组件
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = 0.0.0.0
a1.sinks.k1.port = 45454
# 把组件连接起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
配置bigdata04上的Agent
在指定Agent中sink配置的时候注意,我们的需求是需要按天在hdfs中创建目录,并把当天的数据上传到当天的日期目录中,这也就意味着hdfssink中的path不能写死,需要使用变量,动态获取时间,查看官方文档可知,在hdfs的目录中需要使用%Y%m%d
在这还有一点需要注意的,因为我们这里需要抽取时间,这个时间其实是需要从数据里面抽取,咱们前面说过数据的基本单位是Event,Event是一个对象,后面我们会详细分析,在这里大家先知道它里面包含的既有我们采集到的原始的数据,还有一个header属性,这个header属性是一个key-value结构的,我们现在抽取时间就需要到event的header中抽取,但是默认情况下event的header中是没有日期的,强行抽取是会报错的,会提示抽取不到,返回空指针异常。
那如何向header中添加日期呢? 其实官方文档中也说了,可以使用hdfs.useLocalTimeStamp或者时间拦截器,时间拦截器我们后面会讲,暂时最简单直接的方式就是使用hdfs.useLocalTimeStamp,这个属性的值默认为false,需要改为true。
# agent的名称是a1
# 指定source组件、channel组件和Sink组件的名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# 配置source组件
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 45454
# 配置channel组件
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 配置sink组件
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://bigdata04:9000/access/%Y%m%d
a1.sinks.k1.hdfs.filePrefix = access
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# 把组件连接起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
初始化数据
在开始启动之前需要先在bigdata02和bigdata03中生成测试数据,为了模拟真实情况,在这里我们就开发一个脚本,定时向文件中写数据,generateAccessLog.sh
#!/bin/bash
# 循环向文件中生成数据
while [ "1" = "1" ]
do
# 获取当前时间戳
curr_time=`date +%s`
# 获取当前主机名
name=`hostname`
echo ${name}_${curr_time} >> /root/test_flume/source/log/access.log
# 暂停1秒
sleep 1
done
启动agent
接下来开始启动相关的服务进程,首先启动bigdata04上的agent服务,接下来启动bigdata02上的agent服务和shell脚本,最后启动bigdata03上的agent服务和shell脚本
验证结果
查看hdfs上的结果数据,在bigdata01上查看
注意:启动之后稍等一会就可以看到数据了,我们观察数据的变化,会发现hdfs中数据增长的不是很快,它会每隔一段时间添加一批数据,实时性好像没那么高?
这是因为avrosink中有一个配置batch-size,它的默认值是100,也就是每次发送100条数据,如果数据不够100条,则不发送。具体这个值设置多少合适,要看你source数据源大致每秒产生多少数据,以及你希望的延迟要达到什么程度,如果这个值设置太小的话,会造成sink频繁向外面写数据,这样也会影响性能。
最终,依次停止bigdata02、bigdata03中的服务,最后停止bigdata04中的服务