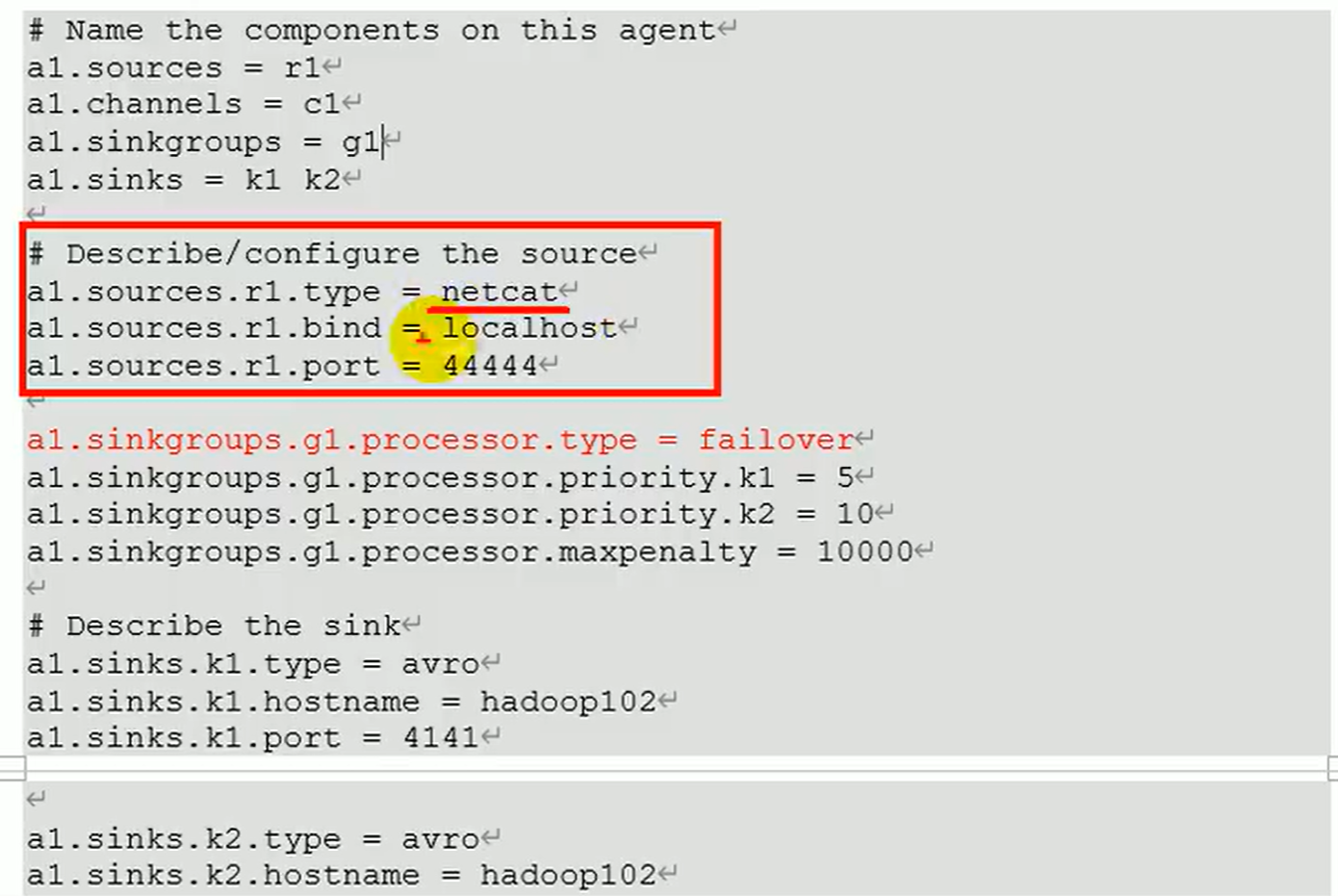
- avro通信
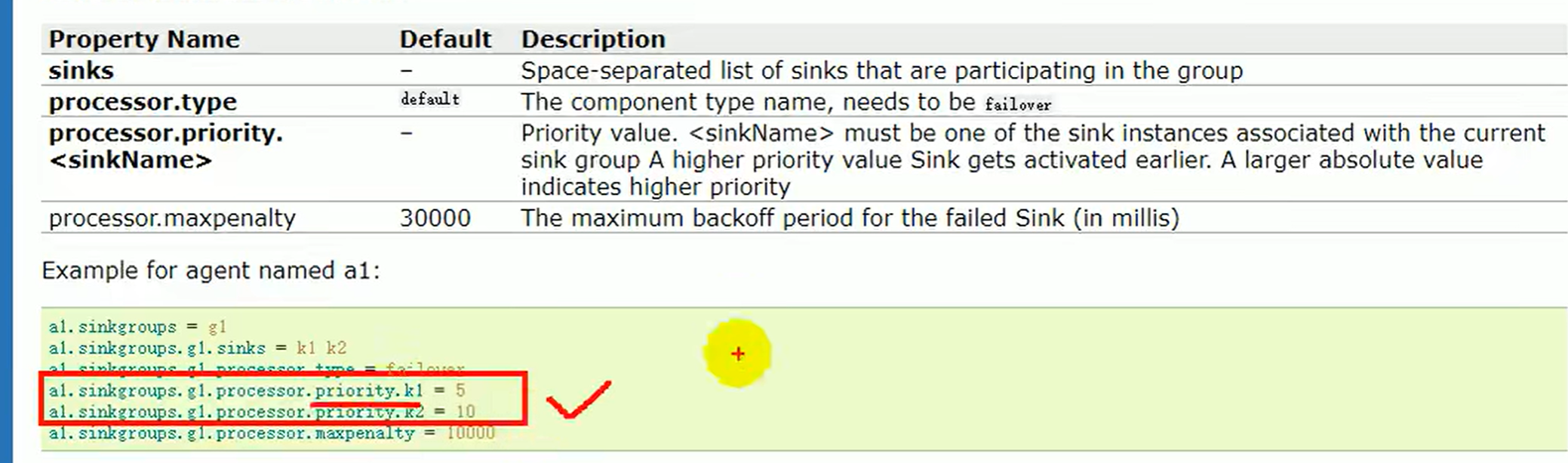
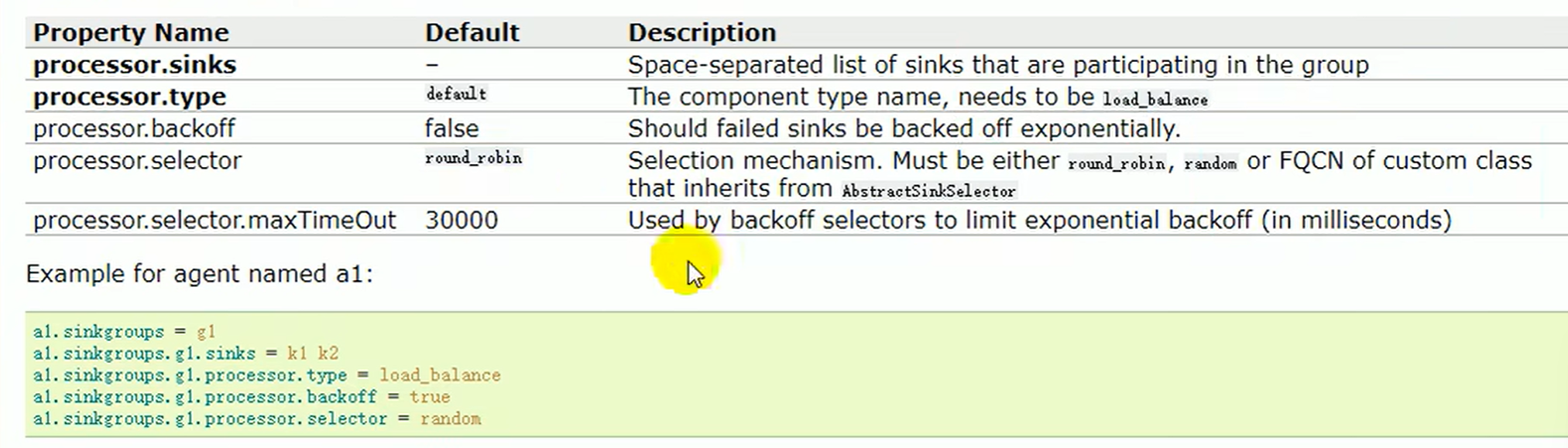
- 负载均衡和故障转移 首先就要求有sink组 group1 K! K2
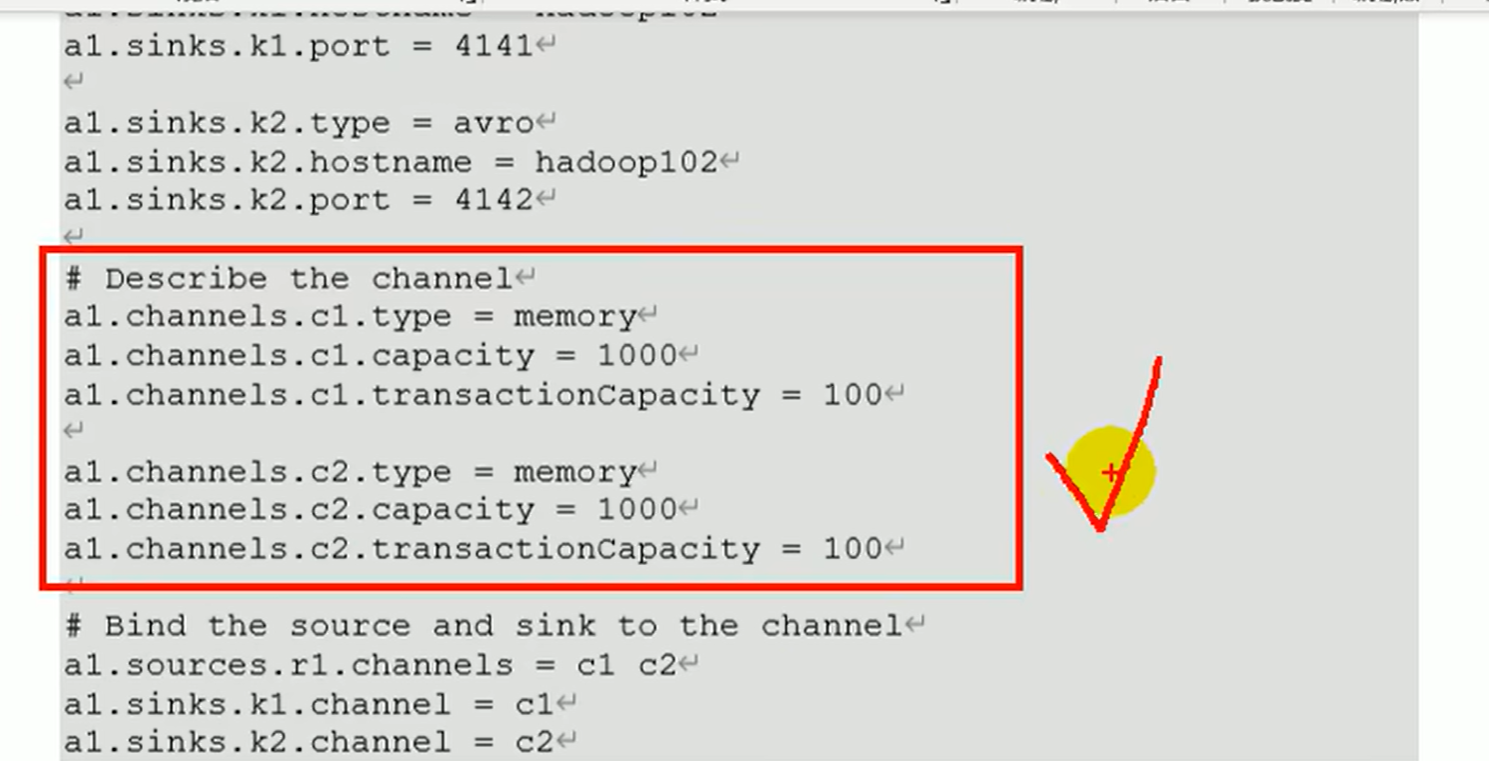
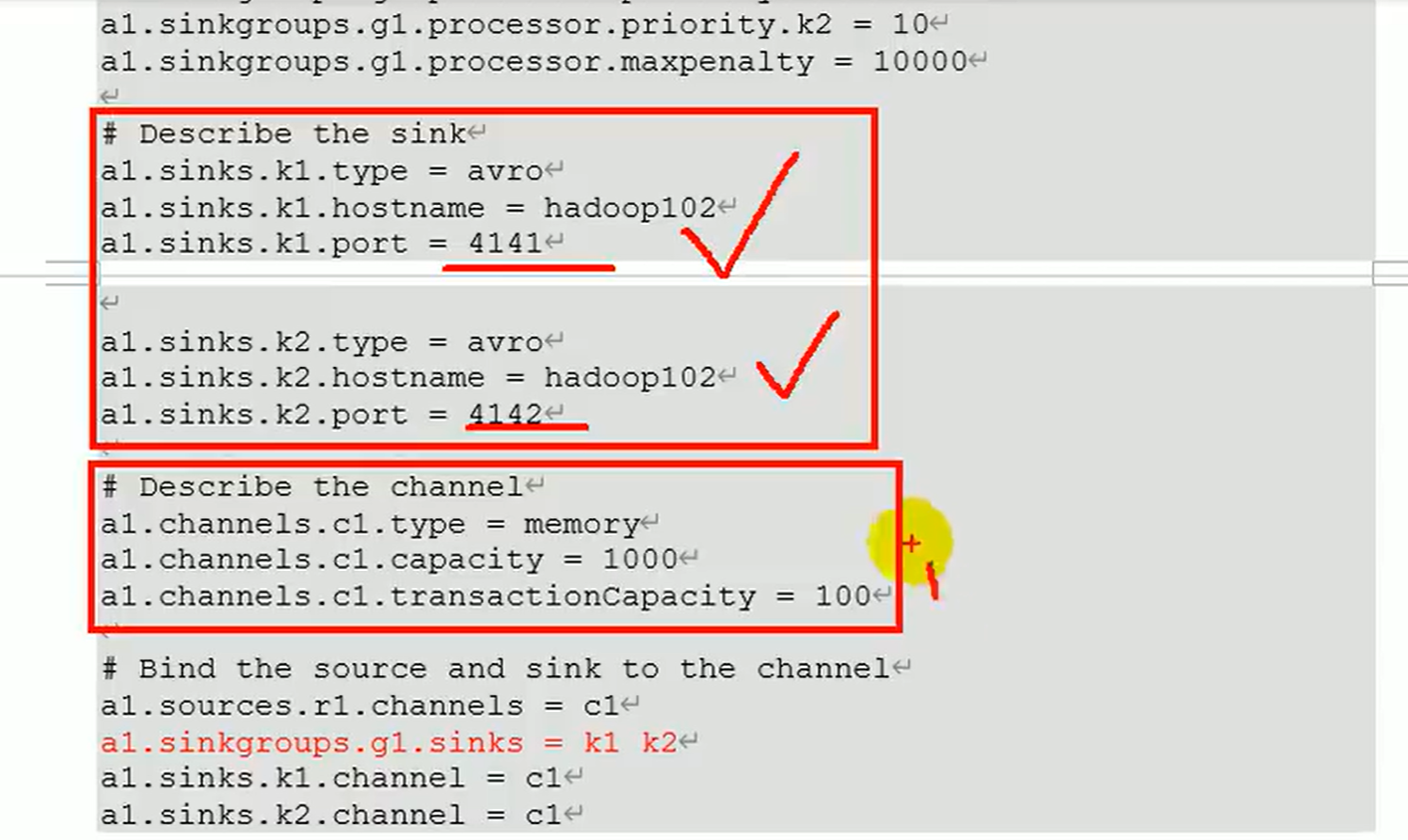
- 配置
- 负载均衡策略 退避backoff

sink是来拉取的,你拉娶不到接下来一段时间就不让你拉去了,可能是真的没有数据,也可可能是挂掉了
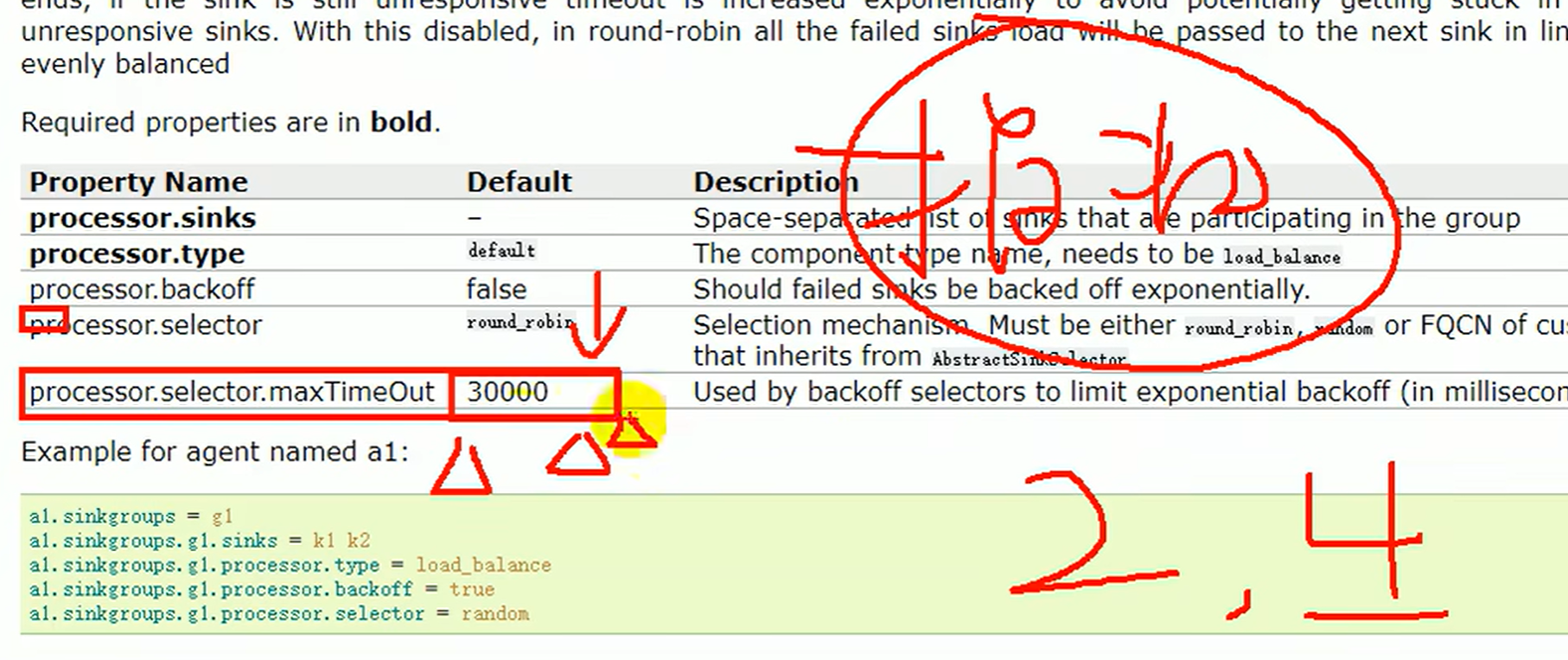
最大退避时长 一晚上没数据 指数增长 两个月都用不到这个sink了,明明人家是好的
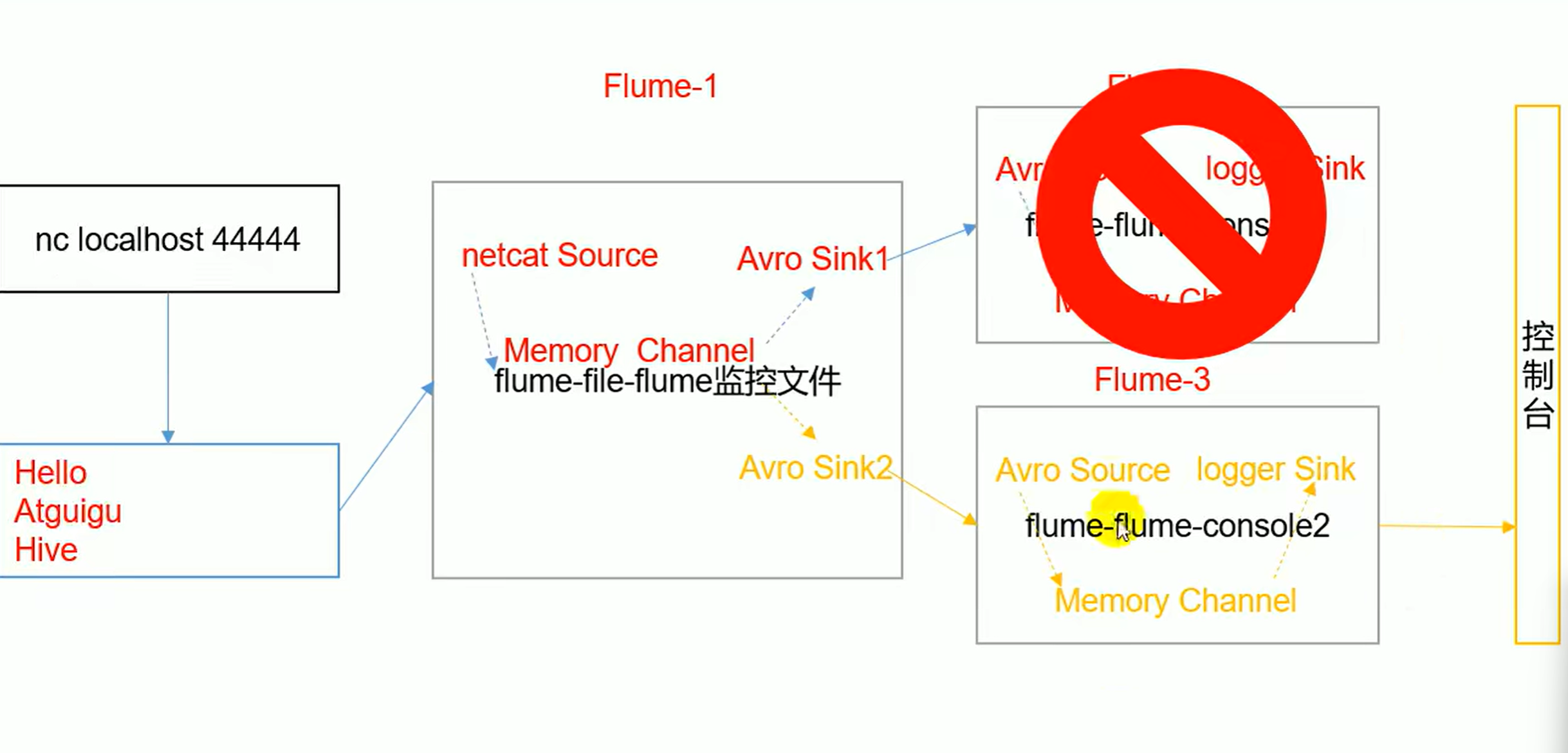
- 为什么轮询不能平均分 本质上是因为不是channel推数据而是sink在拉数据 是sink在轮询,sink轮到自己时发现有数据,拉了,到了另一个发现没有

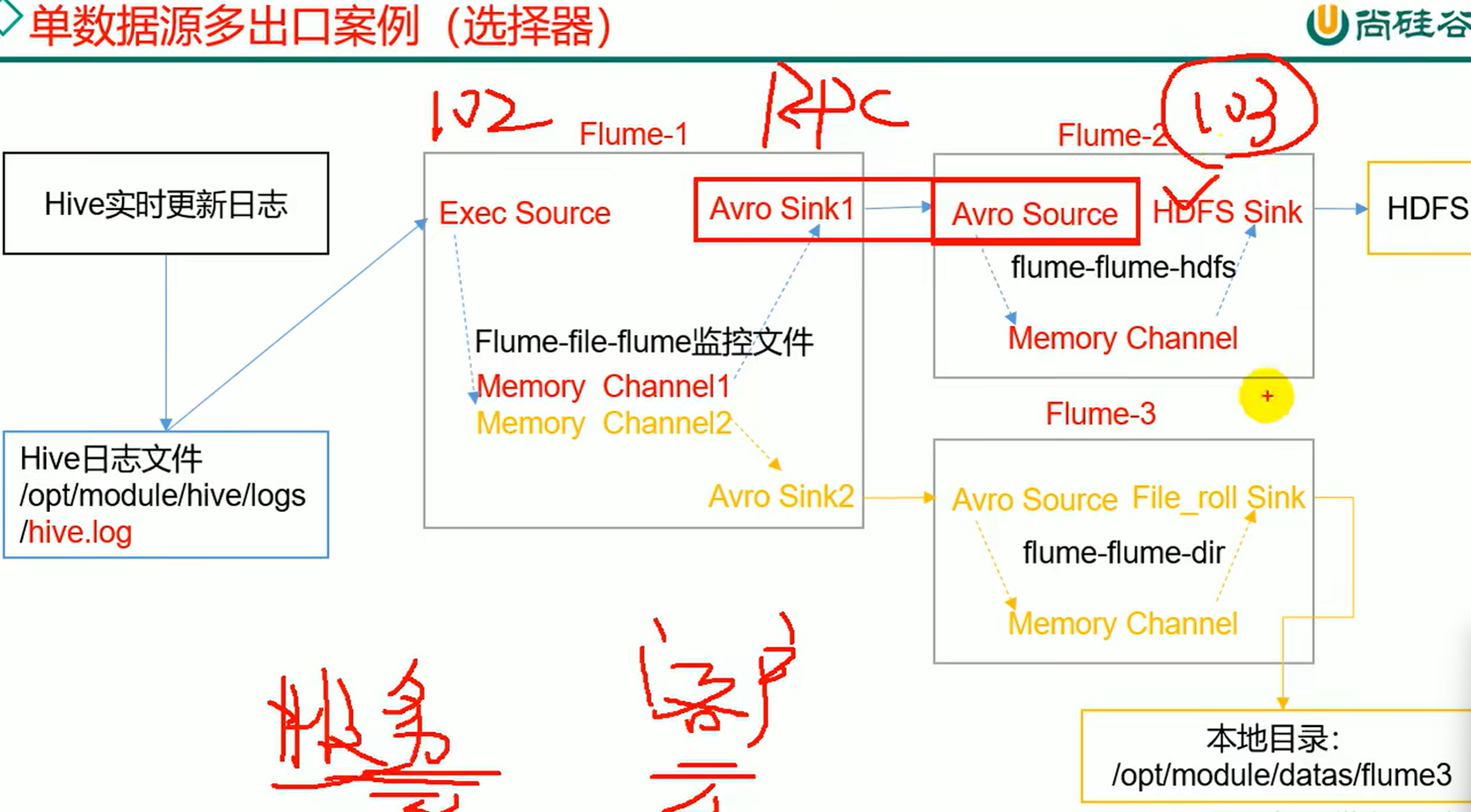
- 拦截器 添加头信息
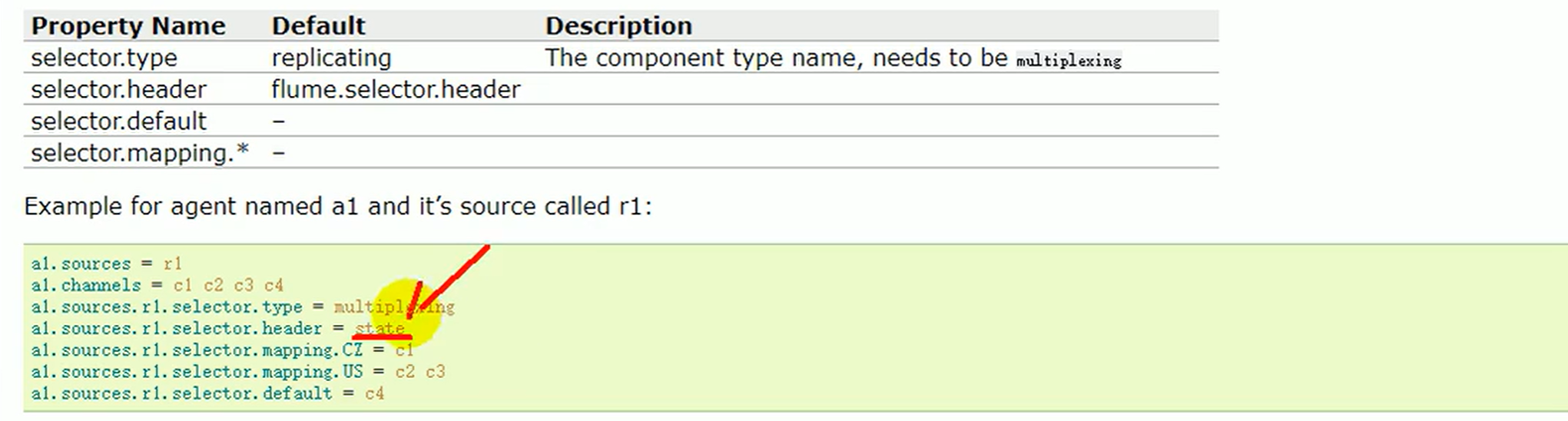
根据日志类型不同放入不同的channel,再放到不同的sink 头信息是一个hashmap header指的就是里面的key
- 如何在springboot中配置拦截器

这是如何处理单个事件,一定要有,然后就在批处理中调用就可以了

链接器链,哪个在前头就先经过哪个 拦截器引用类型是全类名
- 静态内部类是帮我们构建对象的,不是拦截器直接用,而是帮我们统一构造出来 第二个函数是读取配置文件


- 静态内部类java静态内部类


- 将这个jar包打包放到 flume服务器的lib底下 反射的方式帮我们构建
- 自定义source MySQL 回退source

步长 一般不用因为也可以在process封装成event之后再休息一会 source接收不到数据
- 如何写自定义source 参考官方文档实现一个抽象类 和两个接口 接口里面肯定有简单的实现方法
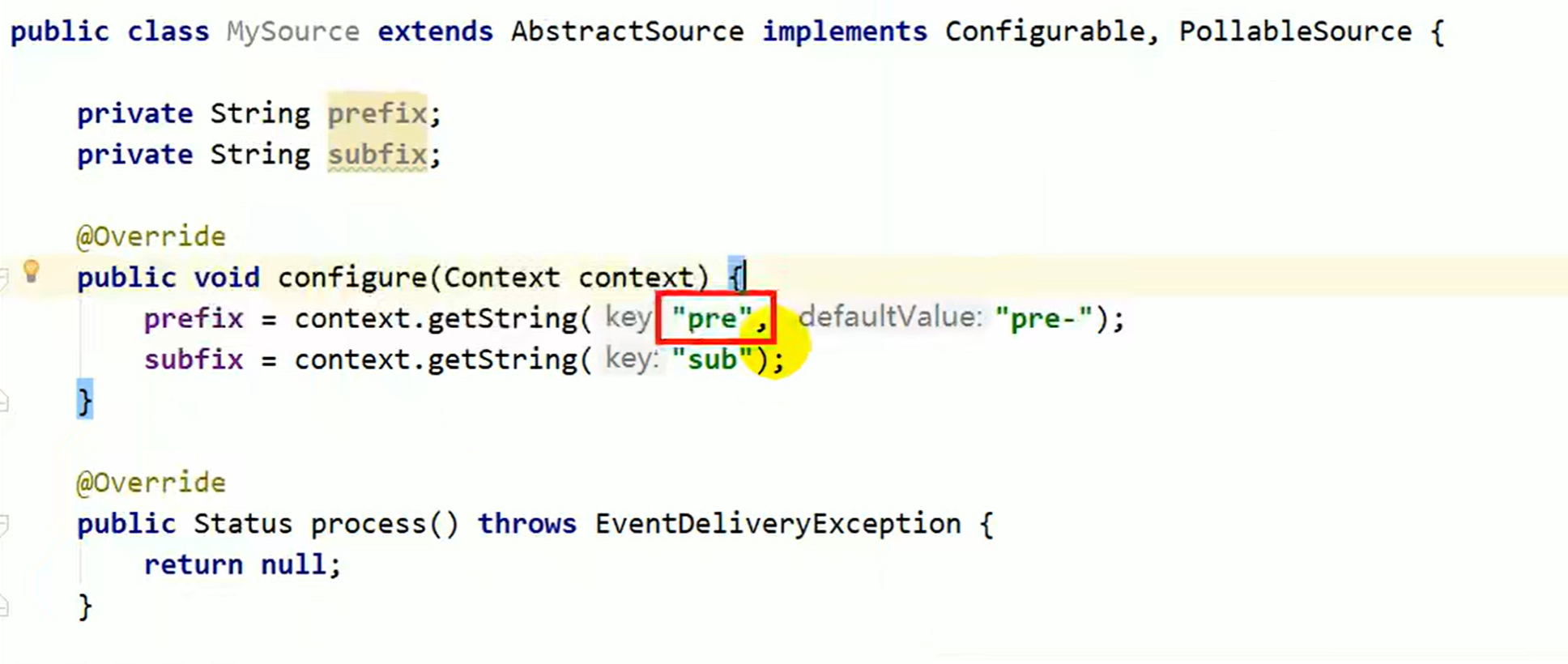
放默认的前后缀,一会是有前缀的写法,一个是没后缀

自定义事件发出去 setheader 没有头信息,由此可见有些head是默认实现的 setbody
- 拦截器的处理流程是事件经过之后返回一个null值,之后就被直接返回不经过后续
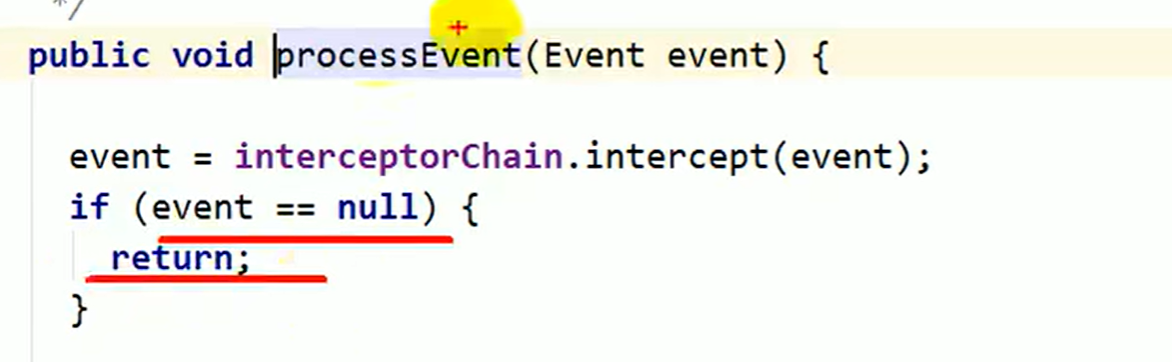
- 后续处理
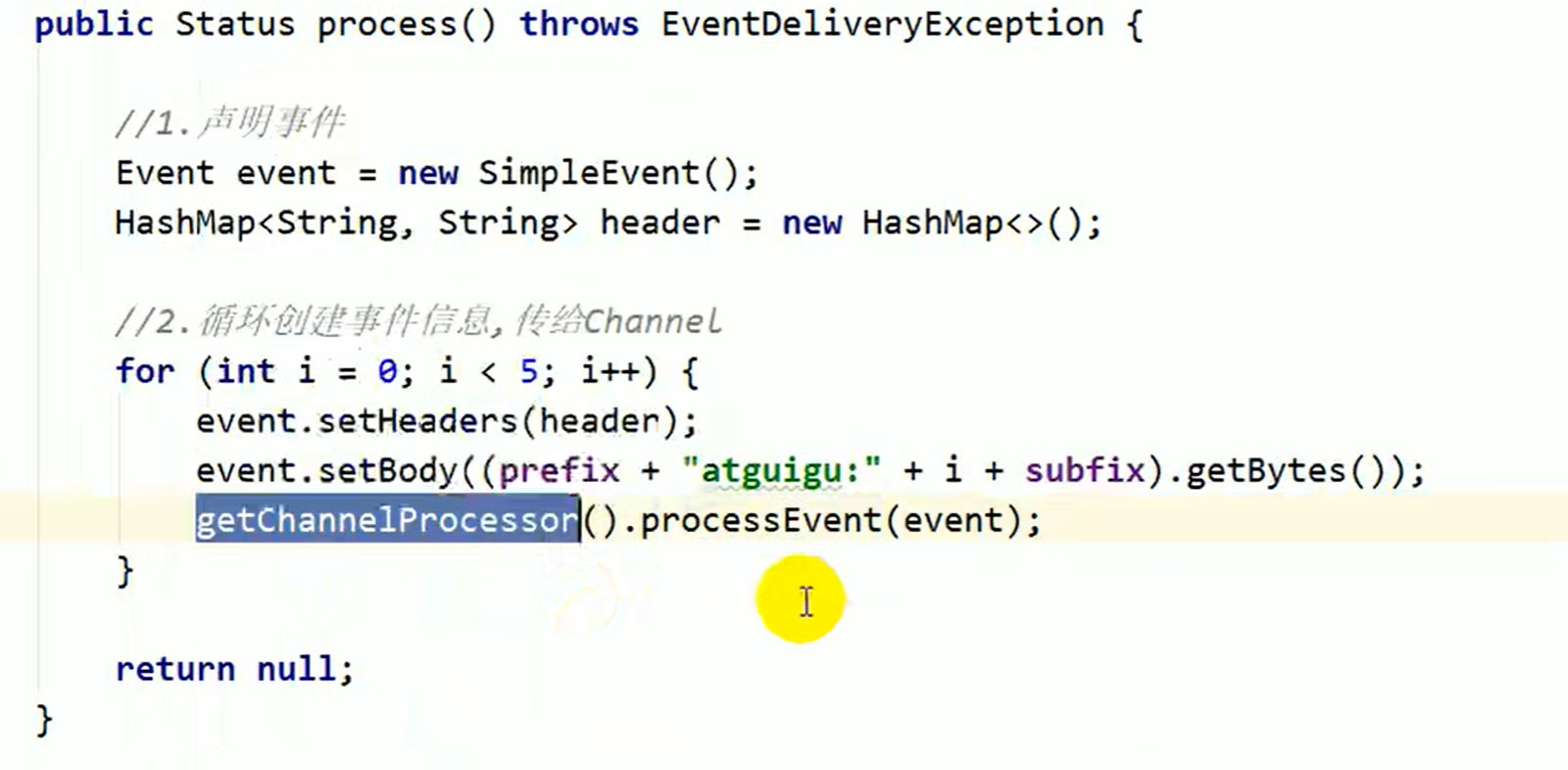
发送完之后就进入处理流程
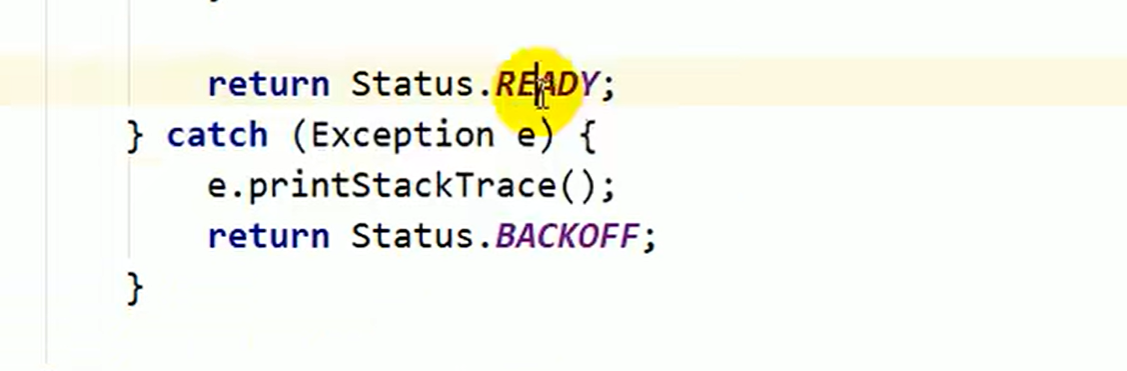
返回的是stas 枚举类型 用点就可以 包裹
- 打包 可以不删因为名字一样会覆盖 注意是整个包而不是单个文件
- 配置的是里面的key,而不是属性名 注意类型是全类名
- namenode的联邦机制 因为namenode只能部署到一台机器上,而内存有限 但一般用不上
- 提交事物整个处理

trace致命的最高级别 debug是最低级别 如果抓取不到就回滚 退避
- flume回滚机制 putlist回滚 直接清空!非常简单,rollback接口实现了一个dorookback方法,所以会丢数据!
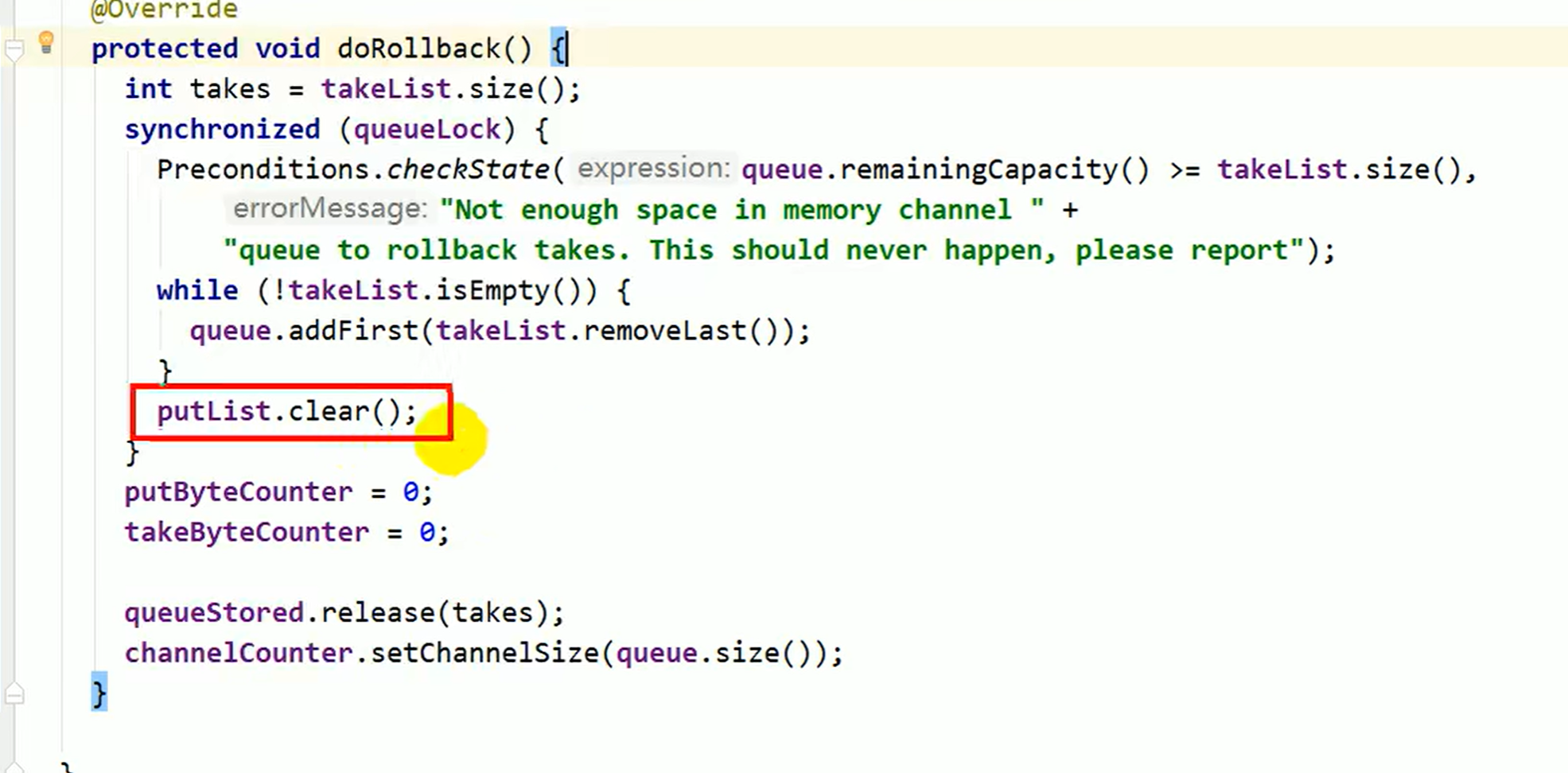
- 注意是MEMorychannel的回滚机制

相当于一个队列 把尾部重新放到头部 所谓的回滚就是把takelust里的东西放回到原原来的channel
- HDFS 这个回滚有可能造成重复!因为已经写成功了,但是因为通信问题,没有及时告知,又回滚重发,channel感知不到!
- 只是有可能会丢失数据,还有一种可能不会

文件行数 POS JSON写入 necat就不行
- 回滚都是一个队列
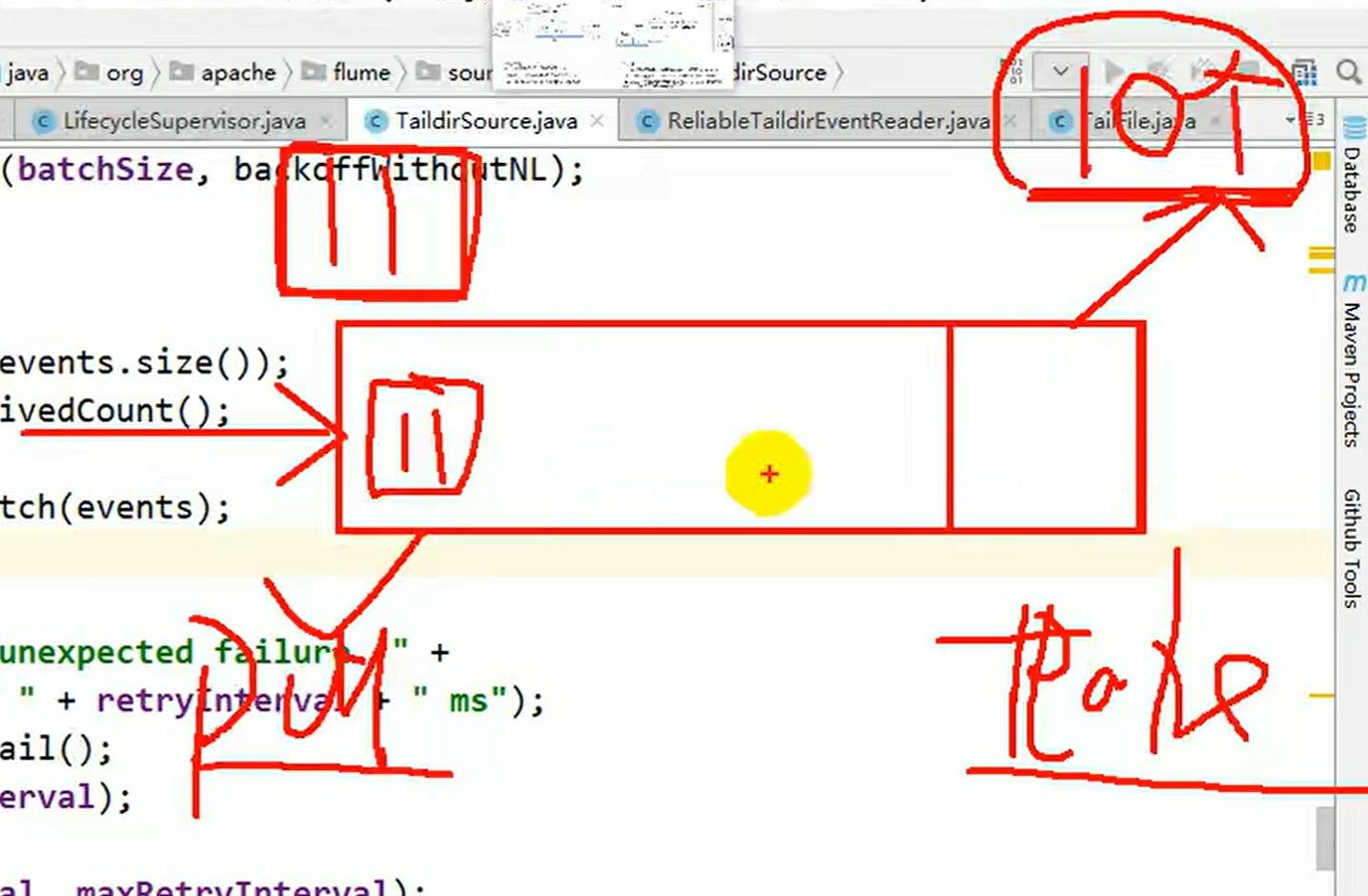
万一没空间了怎么办?放不回来,,会预留 ,优先take 你想想也是这样,源数据一直在那,你可以一直取!
- 整个流程
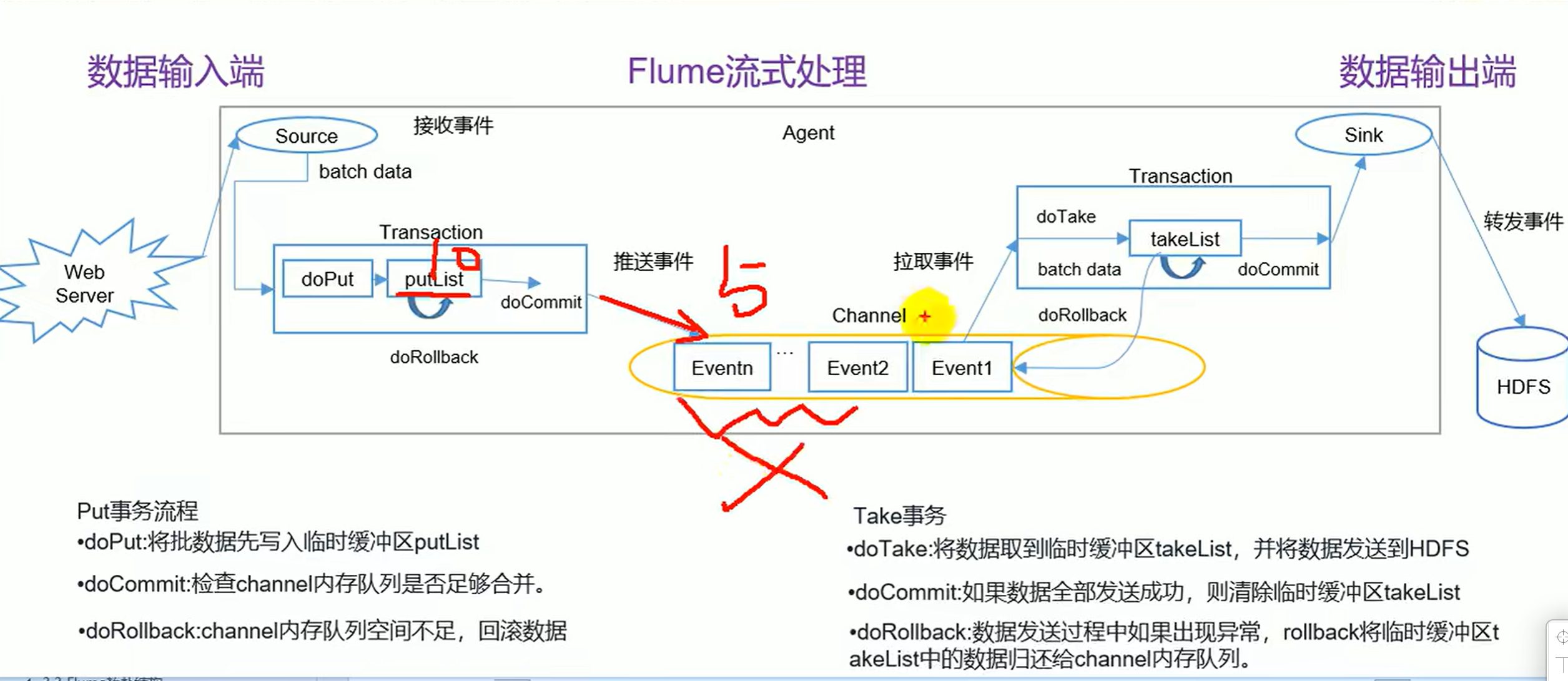
如何优化 回滚时设置为一样,空间搞大一点也不用害怕数据重复,因为在它的流程中是可以感知的 跟source类型又有关系,要是可以记录位置信息就好了。
- 事务 要么一起成功,要么一起失败!
flume面试2
发布时间 2023-10-16 17:09:47作者: SunShine789