一、数据分区概念
对分布式计算引擎来说,数据分区的主要作用是将现环节的数据进行切分,交给下游位于不同物理节点上的Task计算。
二、Flink数据分区接口体系
1、顶层接口ChannelSelector
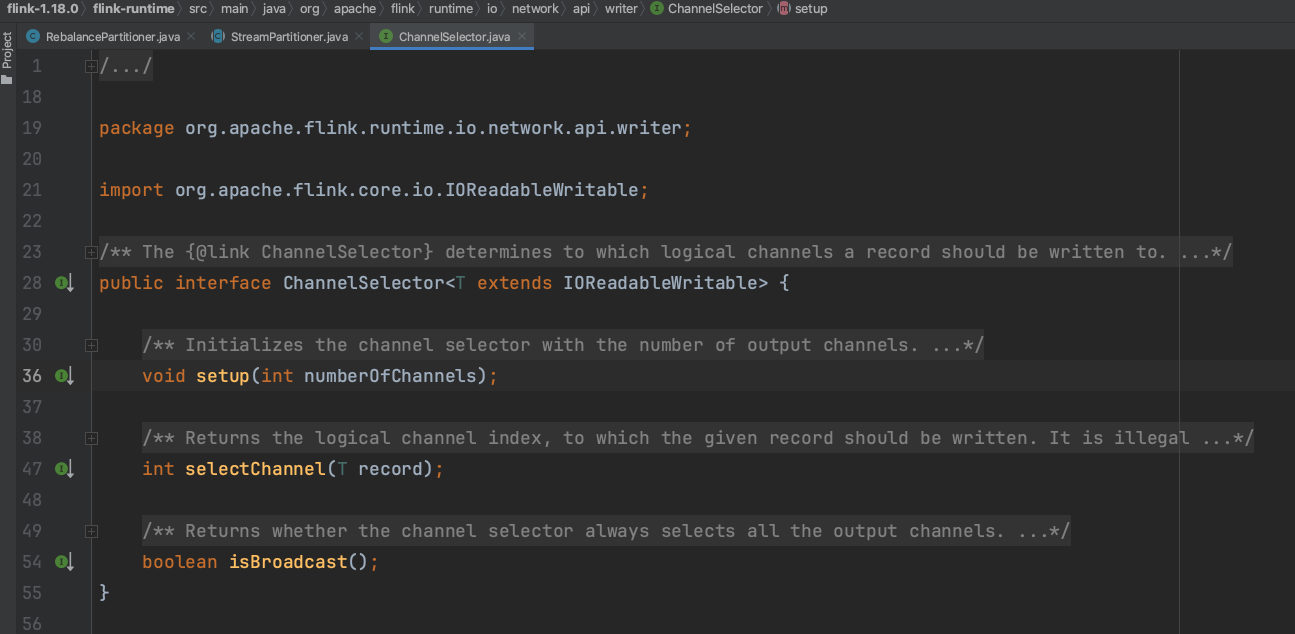
(1).setup()方法设置下游算子的通道数量。从该接口中可以看到,算子里的每一个分区器都知道下游通道数量。
(2).selectChannel()方法设置每条数据所属的下游具体通道。
(3).isBroadcast()方法判断是否向下游广播。
2、Flink数据分区抽象类实现StreamPartitioner
抽象类StreamPartitioner包含一个关键成员变量numberOfChannels,在具体数据分区实现类初始化时,需要设置成员变量numberOfChannels的值,代表下游通道数量。
3、Flink数据分区实现类
BroadcastPartitioner:将每条数据广播给下游所有分区。调用方法dataStream.broadcast();
CustomPartitionerWrapper:Flink应用人员自定义分区选择逻辑。调用方法dataStream.partitionCustom(partitioner,${key});
ForwardPartitioner:在同一个OperatorChain中上下游算子之间数据转发,实际上是数据是直接传递给下游的。调用方法dataStream.forward();
GlobalPartitioner:只会将数据输出到下游算子的第一个实例。调用方法dataStream.global();
KeyGroupStreamPartitioner:应用在KeyedStream上,后续随笔会着重解析key的分发过程。
RebalancePartitioner:轮询分配每条数据。调用方法dataStream.rebalance();
RescalePartitioner:先平均分配下游分区范围,再轮询分配每条数据。调用方法dataStream.rescale();
ShufflePartitioner:随机分配每条数据。调用方法dataStream.shuffle();
三、举例数据分区实现解析
1、CustomPartitionerWrapper解析:
(1).DataStream类下调用partitionCustom()方法,需要传入Partitioner和KeySelector实例入参。

(2).Partitioner接口只需要自定义实现partition()方法,即根据KeySelector得到的key,计算出来一个自定义通道位置。
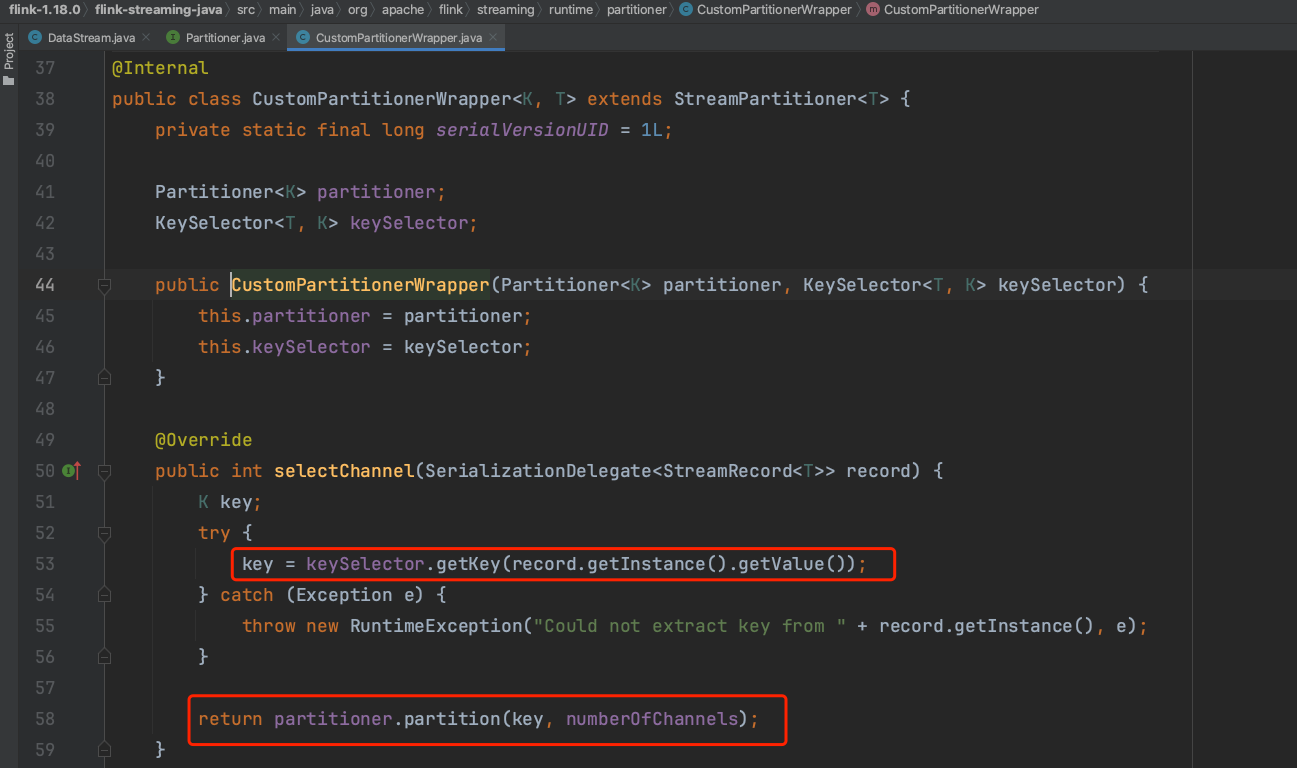
(3).下图可知setConnectionType()方法根据用户自定义分区类实例生成一个PartitionTransformation虚拟转换。虚拟Transformation参考《Flink源码解析(三)——DataStream和Transformation解析》。

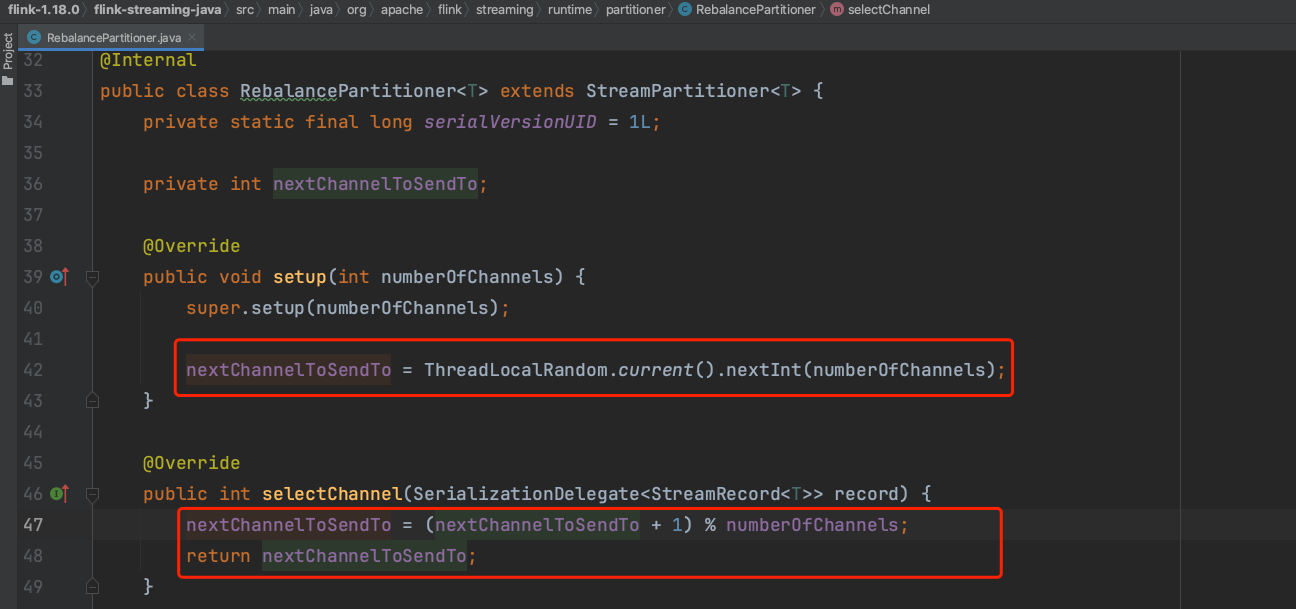
2、RebalancePartitioner解析:
(1).下图可知RebalancePartitioner事先随机初始化一个下游通道位置,每来一条数据,目标通道位置+1事先轮询的过程。
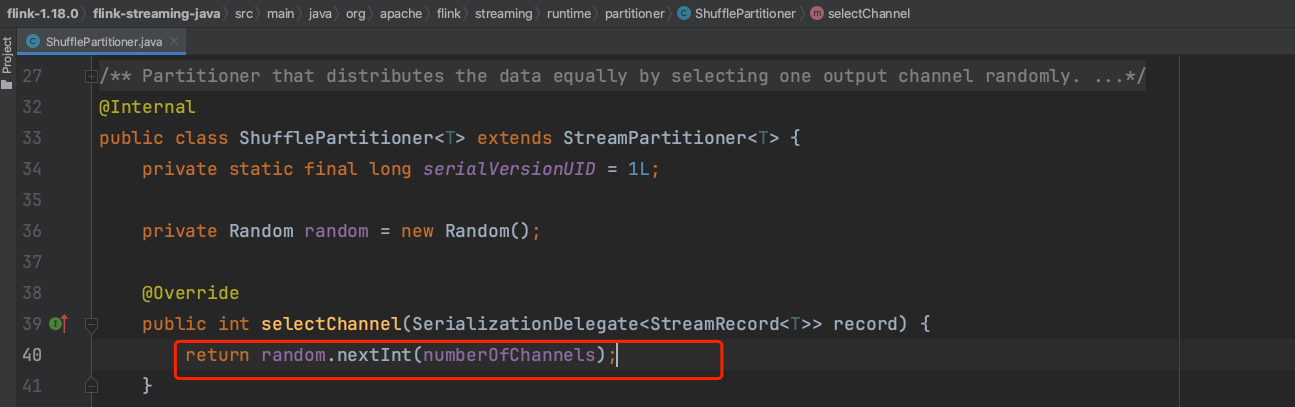
3、ShufflePartitioner解析:
(1).下图可知ShufflePartitioner对每条数据随机生成一个0~numberOfChannels范围内的整数作为该数据的下游通道位置。