我们已经介绍了几种用于自然语言理解的词嵌入模型。在预训练之后,输出可以被认为是一个矩阵,其中每一行都是一个表示预定义词表中词的向量。事实上,这些词嵌入模型都是与上下文无关的。让我们先来说明这个性质。
从上下文无关到上下文敏感

ELMo(Embeddings from Language Models)是一种利用预训练的语言模型来增强下游自然语言处理任务性能的方法。下面是对上述引文中提到的关键概念的简要解释:
-
ELMo为每个输入序列中的单词分配一个表示:ELMo使用预训练的双向长短期记忆网络(bi-directional LSTM)来学习每个单词在上下文中的表示,而不是简单地使用静态的词嵌入。
-
ELMo将中间层表示组合为输出表示:ELMo利用从预训练的双向LSTM中获取的所有中间层表示,将它们组合起来以获得单词的最终表示。
-
将ELMo的表示作为附加特征添加到下游任务的现有监督模型中:ELMo的表示作为附加的特征被添加到下游任务的现有监督模型中,例如与原始词元表示(如GloVe)连接起来。
-
冻结了预训练的双向LSTM模型中的所有权重:在添加ELMo表示后,预训练的双向LSTM模型的权重会被冻结,不再进行微调。
-
利用不同任务的不同最佳模型,ELMo改进了多种自然语言处理任务的技术水平:ELMo的表示可以结合现有的监督模型,从而提高多种自然语言处理任务的性能,如情感分析、自然语言推断、语义角色标注、共指消解、命名实体识别和问答等。
总的来说,ELMo的核心思想是通过结合上下文信息和预训练语言模型的表示,来丰富单词的表征,从而提高各种自然语言处理任务的性能。这种方法已经在多个任务中取得了显著的改进,成为自然语言处理领域的重要技术之一。
从特定于任务到不可知任务
尽管ELMo显著改进了各种自然语言处理任务的解决方案,但每个解决方案仍然依赖于一个特定于任务的架构。然而,为每一个自然语言处理任务设计一个特定的架构实际上并不是一件容易的事。GPT(Generative Pre Training,生成式预训练)模型为上下文的敏感表示设计了通用的任务无关模型 (Radford et al., 2018)。GPT建立在Transformer解码器的基础上,预训练了一个用于表示文本序列的语言模型。当将GPT应用于下游任务时,语言模型的输出将被送到一个附加的线性输出层,以预测任务的标签。与ELMo冻结预训练模型的参数不同,GPT在下游任务的监督学习过程中对预训练Transformer解码器中的所有参数进行微调。GPT在自然语言推断、问答、句子相似性和分类等12项任务上进行了评估,并在对模型架构进行最小更改的情况下改善了其中9项任务的最新水平。
然而,由于语言模型的自回归特性,GPT只能向前看(从左到右)。在“i went to the bank to deposit cash”(我去银行存现金)和“i went to the bank to sit down”(我去河岸边坐下)的上下文中,由于“bank”对其左边的上下文敏感,GPT将返回“bank”的相同表示,尽管它有不同的含义。
BERT:把两个最好的结合起来
如我们所见,ELMo对上下文进行双向编码,但使用特定于任务的架构;而GPT是任务无关的,但是从左到右编码上下文。BERT(来自Transformers的双向编码器表示)结合了这两个方面的优点。它对上下文进行双向编码,并且对于大多数的自然语言处理任务 (Devlin et al., 2018)只需要最少的架构改变。通过使用预训练的Transformer编码器,BERT能够基于其双向上下文表示任何词元。在下游任务的监督学习过程中,BERT在两个方面与GPT相似。首先,BERT表示将被输入到一个添加的输出层中,根据任务的性质对模型架构进行最小的更改,例如预测每个词元与预测整个序列。其次,对预训练Transformer编码器的所有参数进行微调,而额外的输出层将从头开始训练。 图14.8.1 描述了ELMo、GPT和BERT之间的差异。
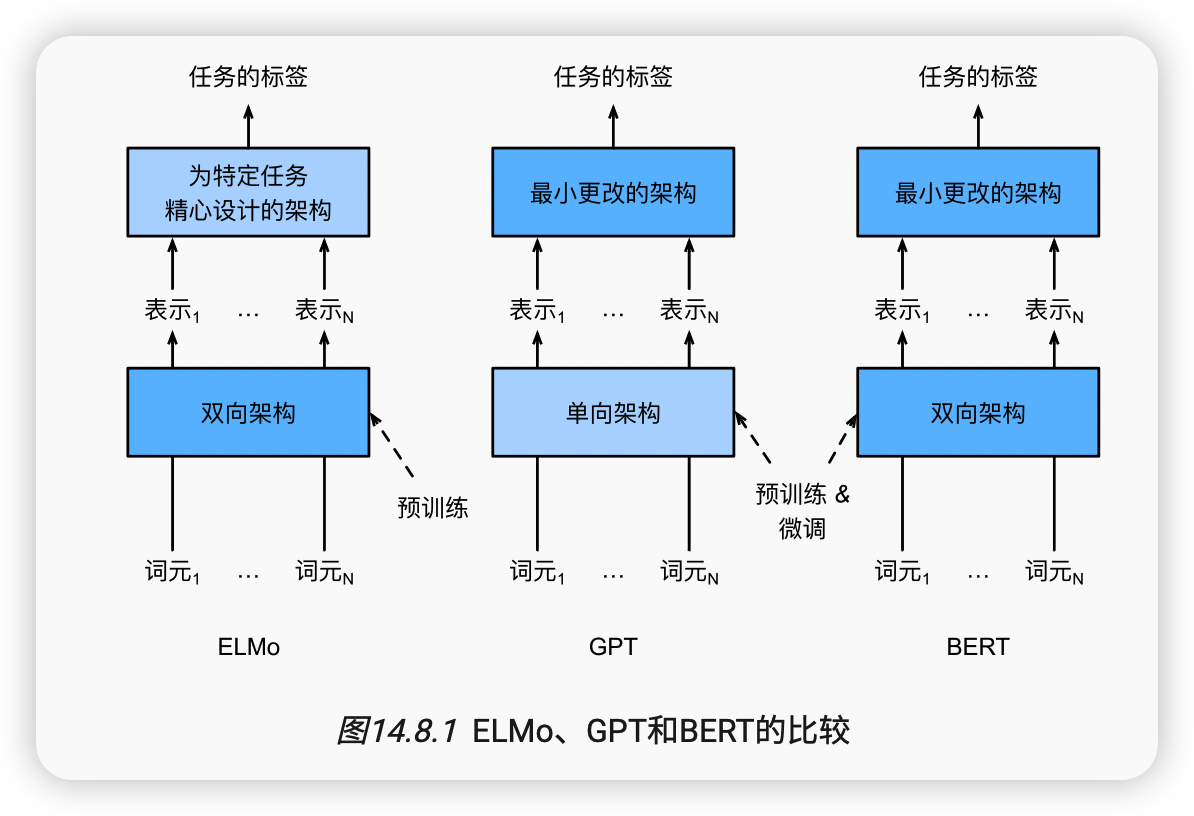
BERT进一步改进了11种自然语言处理任务的技术水平,这些任务分为以下几个大类:(1)单一文本分类(如情感分析)、(2)文本对分类(如自然语言推断)、(3)问答、(4)文本标记(如命名实体识别)。从上下文敏感的ELMo到任务不可知的GPT和BERT,它们都是在2018年提出的。概念上简单但经验上强大的自然语言深度表示预训练已经彻底改变了各种自然语言处理任务的解决方案。
输入表示

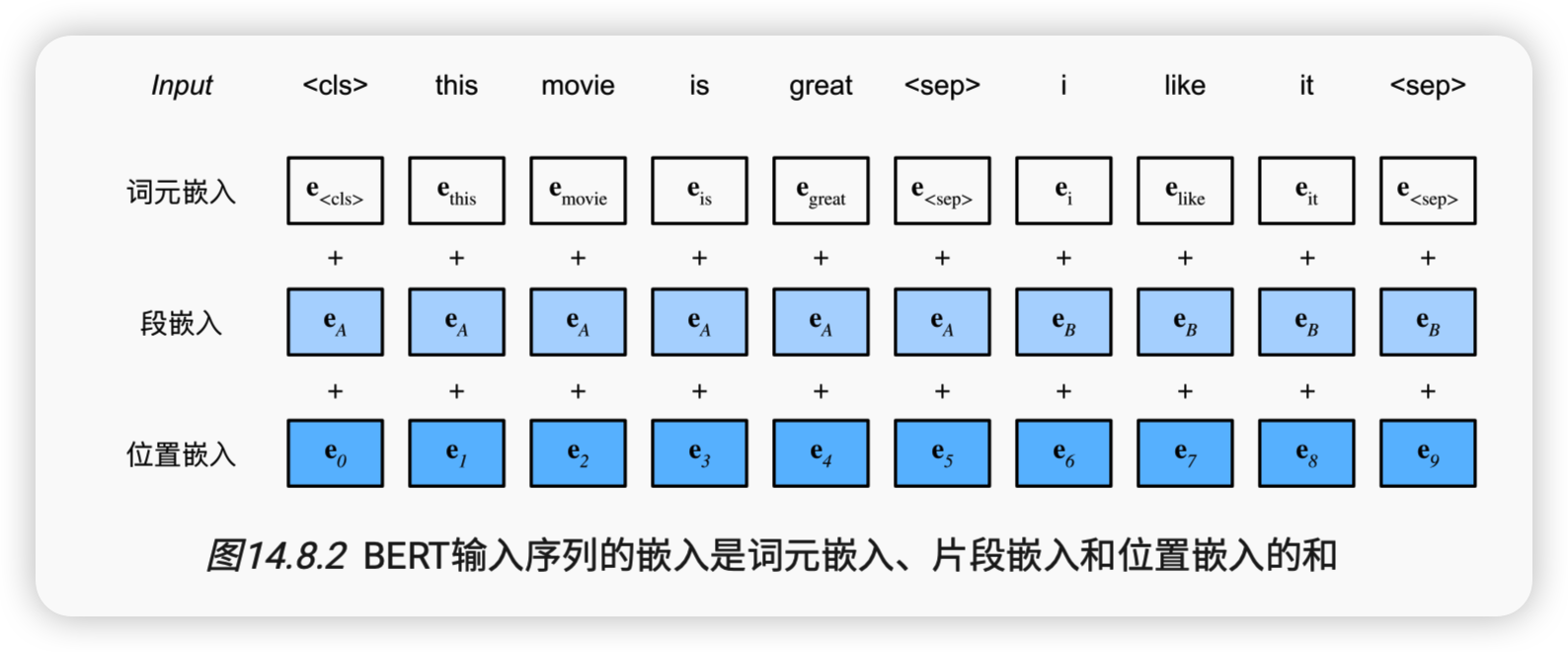
BERT选择Transformer编码器作为其双向架构。在Transformer编码器中常见是,位置嵌入被加入到输入序列的每个位置。然而,与原始的Transformer编码器不同,BERT使用可学习的位置嵌入。总之, 图14.8.2表明BERT输入序列的嵌入是词元嵌入、片段嵌入和位置嵌入的和。
预训练任务
BERTEncoder的前向推断给出了输入文本的每个词元和插入的特殊标记“<cls>”及“<seq>”的BERT表示。接下来,我们将使用这些表示来计算预训练BERT的损失函数。预训练包括以下两个任务:掩蔽语言模型和下一句预测。
掩蔽语言模型
?什么是掩蔽语言模型
-
语言模型使用左侧的上下文预测词元:传统的语言模型通常使用左侧的上下文单词来预测当前词元,也就是根据前面的单词来预测当前单词。
-
BERT随机掩蔽词元并使用双向上下文进行自监督学习:BERT采用了一种不同于传统语言模型的训练方式。在训练过程中,BERT会随机地掩盖输入序列中的一部分词元,然后利用双向上下文中的其他词元来预测这些被掩盖的词元,这样的任务被称为掩蔽语言模型。
-
双向编码上下文以表示每个词元:通过使用双向上下文来预测掩蔽的词元,BERT可以捕捉每个词元周围丰富的双向信息,从而生成更加全面和丰富的表示。
在这个预训练任务中,将随机选择15%的词元作为预测的掩蔽词元。要预测一个掩蔽词元而不使用标签作弊,一个简单的方法是总是用一个特殊的“<mask>”替换输入序列中的词元。然而,人造特殊词元“<mask>”不会出现在微调中。为了避免预训练和微调之间的这种不匹配,如果为预测而屏蔽词元(例如,在“this movie is great”中选择掩蔽和预测“great”),则在输入中将其替换为:
-
80%时间为特殊的“<mask>“词元(例如,“this movie is great”变为“this movie is<mask>”;
-
10%时间为随机词元(例如,“this movie is great”变为“this movie is drink”);
-
10%时间内为不变的标签词元(例如,“this movie is great”变为“this movie is great”)。
请注意,在15%的时间中,有10%的时间插入了随机词元。这种偶然的噪声鼓励BERT在其双向上下文编码中不那么偏向于掩蔽词元(尤其是当标签词元保持不变时)。
下一句预测
尽管掩蔽语言建模能够编码双向上下文来表示单词,但它不能显式地建模文本对之间的逻辑关系。为了帮助理解两个文本序列之间的关系,BERT在预训练中考虑了一个二元分类任务——下一句预测。在为预训练生成句子对时,有一半的时间它们确实是标签为“真”的连续句子;在另一半的时间里,第二个句子是从语料库中随机抽取的,标记为“假”。
下面的NextSentencePred类使用单隐藏层的多层感知机来预测第二个句子是否是BERT输入序列中第一个句子的下一个句子。由于Transformer编码器中的自注意力,特殊词元“<cls>”的BERT表示已经对输入的两个句子进行了编码。因此,多层感知机分类器的输出层(self.output)以X作为输入,其中X是多层感知机隐藏层的输出,而MLP隐藏层的输入是编码后的“<cls>”词元。
总结
-
word2vec和GloVe等词嵌入模型与上下文无关。它们将相同的预训练向量赋给同一个词,而不考虑词的上下文(如果有的话)。它们很难处理好自然语言中的一词多义或复杂语义。
-
对于上下文敏感的词表示,如ELMo和GPT,词的表示依赖于它们的上下文。
-
ELMo对上下文进行双向编码,但使用特定于任务的架构(然而,为每个自然语言处理任务设计一个特定的体系架构实际上并不容易);而GPT是任务无关的,但是从左到右编码上下文。
-
BERT结合了这两个方面的优点:它对上下文进行双向编码,并且需要对大量自然语言处理任务进行最小的架构更改。
-
BERT输入序列的嵌入是词元嵌入、片段嵌入和位置嵌入的和。
-
预训练包括两个任务:掩蔽语言模型和下一句预测。前者能够编码双向上下文来表示单词,而后者则显式地建模文本对之间的逻辑关系。