一.数据的加载:
(x, y), (x_test, y_test) = datasets.fashion_mnist.load_data()
print(x.shape, y.shape)

二.数据的处理
def preprocess(x, y):
x = tf.cast(x, dtype=tf.float32) / 255. #归一化
y = tf.cast(y, dtype=tf.int32)
return x,y
batchsz = 128
db = tf.data.Dataset.from_tensor_slices((x,y)) # 变成tensor类型
db = db.map(preprocess).shuffle(10000).batch(batchsz) # 打散加分成一个batch
db_test = tf.data.Dataset.from_tensor_slices((x_test,y_test)) #测试集也一样,便于后面的检验
db_test = db_test.map(preprocess).batch(batchsz)
db_iter = iter(db)
sample = next(db_iter)
print('batch:', sample[0].shape, sample[1].shape)
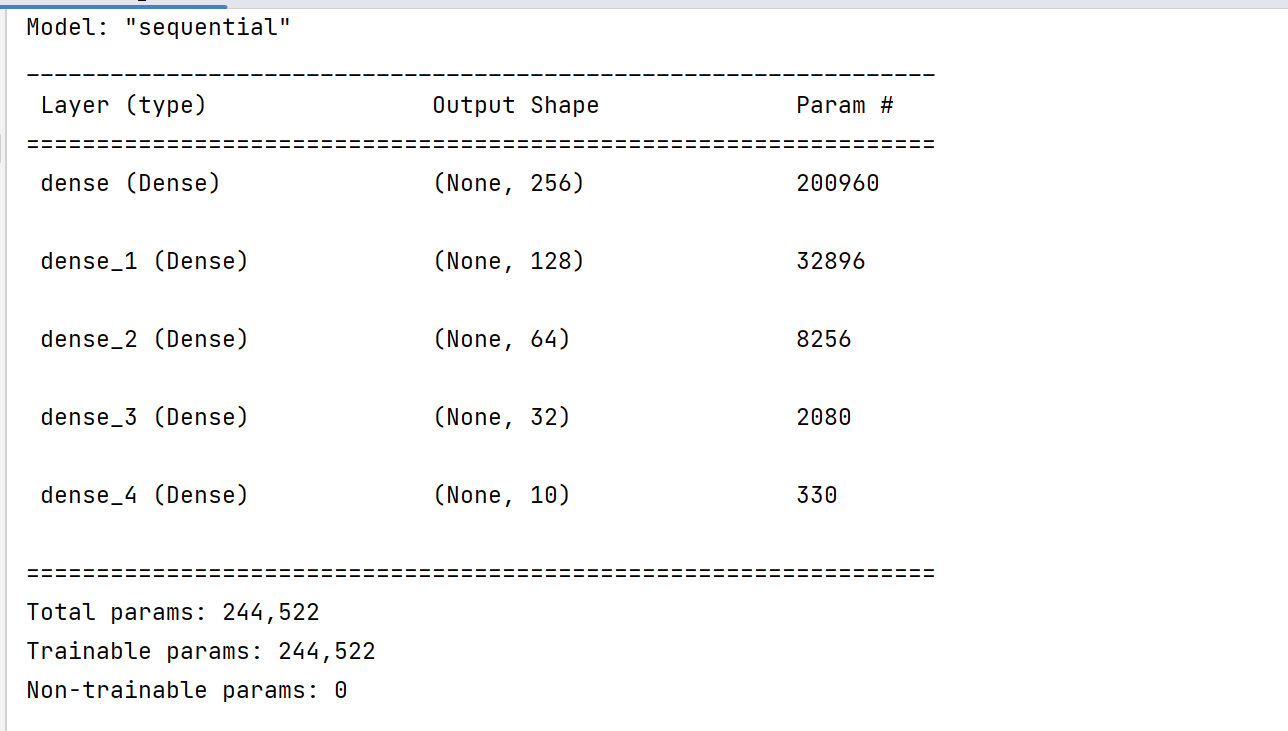
三.定义5层神经网络
model = Sequential([
layers.Dense(256, activation=tf.nn.relu), # [b, 784] => [b, 256]
layers.Dense(128, activation=tf.nn.relu), # [b, 256] => [b, 128]
layers.Dense(64, activation=tf.nn.relu), # [b, 128] => [b, 64]
layers.Dense(32, activation=tf.nn.relu), # [b, 64] => [b, 32]
layers.Dense(10) # [b, 32] => [b, 10], 330 = 32*10 + 10
])
model.build(input_shape=[None, 28*28]) # 测试,查看其结构
model.summary()
四。梯度下降:
# w = w - lr*grad
optimizer = optimizers.Adam(lr=1e-3) # 下面有解释
def main():
for epoch in range(30):
for step, (x,y) in enumerate(db): #既要遍历其索引,又要遍历其值,就加一个enumerate(db)
# x: [b, 28, 28] => [b, 784]
# y: [b]
x = tf.reshape(x, [-1, 28*28])
with tf.GradientTape() as tape:
# [b, 784] => [b, 10]
logits = model(x)
y_onehot = tf.one_hot(y, depth=10)
# [b]
loss_mse = tf.reduce_mean(tf.losses.MSE(y_onehot, logits))
loss_ce = tf.losses.categorical_crossentropy(y_onehot, logits, from_logits=True)
loss_ce = tf.reduce_mean(loss_ce)
grads = tape.gradient(loss_ce, model.trainable_variables) #注意我们之前都是在前面定义w1,w2,w3--b1,b2,但是这次是在前面直接定义了神经网络,然后我们想要获取到里面查看里面可训练的变量就用model.trainable_variables
optimizer.apply_gradients(zip(grads, model.trainable_variables))# 自动更新grads和variable中的参数
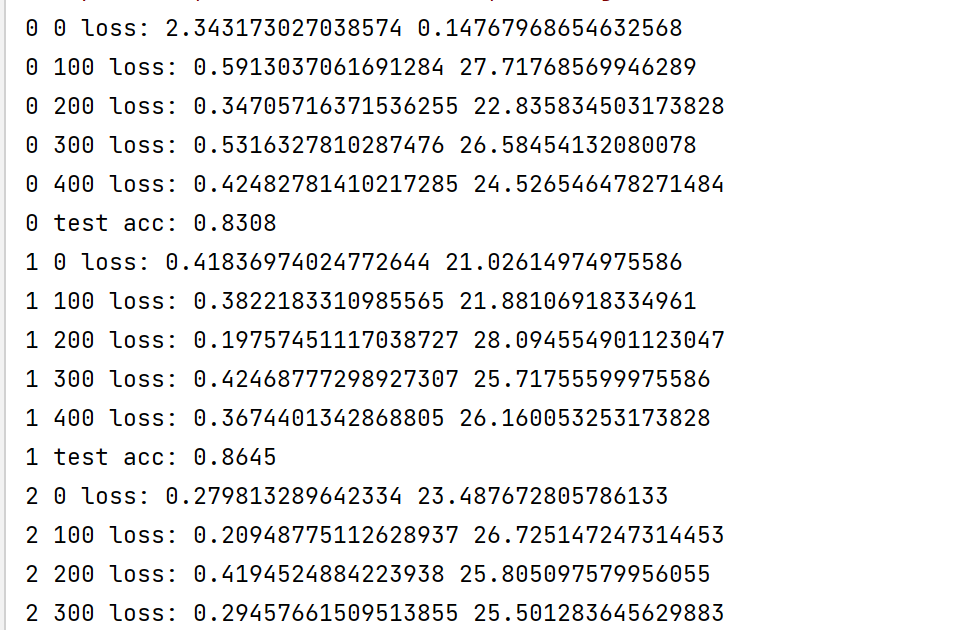
if step % 100 == 0:
print(epoch, step, 'loss:', float(loss_ce), float(loss_mse))
这个里面有三个要说的函数是
1.keras.optimizers.Adam()
optimizer=keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.99, epsilon=1e-08, decay=0.0)
就是我们在做梯度下降的时候w=w-lr*grad,然后我们每一次都这样跟新的话,会很麻烦,所以就有了一个这个函数,然后这个还能和下面optimizer.apply_gradients(自动更新),一起用。其实这个函数就是类似于一个学习率,用来控制梯度下降的大小,在监督学习中我们使用梯度下降法时,学习率是一个很重要的指标,因为学习率决定了学习进程的快慢(也可以看作步幅的大小)。如果学习率过大,很可能会越过最优值,反而如果学习率过小,优化的效率可能很低,导致过长的运算时间,所以学习率对于算法性能的表现十分重要
参数详解:
keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.99, epsilon=1e-08, decay=0.0)
lr:float> = 0.学习率
beta_1:float,0 <beta <1。一般接近1。一阶矩估计的指数衰减率
beta_2:float,0 <beta <1。一般接近1。二阶矩估计的指数衰减率
epsilon:float> = 0,模糊因子。如果None,默认为K.epsilon()。该参数是非常小的数,其为了防止在实现中除以零
decay:float> = 0,每次更新时学习率下降
然后我们这里用了一个固定的步长。
2.model.trainable_variables
model.trainable_variables
我们之前做的时候,都是定义一个variable类型的w1,w2,--b1,b2,但是现在我们都是用Sequential来定义的这个神经网络,但是后面求梯度的时候我们需要用到这些值,所以我们后面求梯度的时候我们可以用这个grads = tape.gradient(loss_ce, model.trainable_variables)
3.for step, (x,y) in enumerate(db):
for step,(x,y) in enumerate(db):
这个enumerate,为什么加这个呢,因为我们加了一个step,我们如果需要循环索引的话,得加上这个
4.apply_gradients
apply_gradients(grads_and_vars,global_step=None,name=None)
功能:更新参数。
参数:grads_and_vars,(gradient, variable) 对的列表,所以我们需要zip(zip(grads, model.trainable_variables))函数
返回值:无返回值,把计算出来的梯度更新到变量上去。
这个函数就是,我们在w = w - lr*grad计算完梯度之后,我们需要更新这里面的Variable变量,但是我们没有定义w1,w2,--b1,b2,所以它给我们提供了一个函数apply_gradients
五。检验准确性:
# test
total_correct = 0
total_num = 0
for x,y in db_test:
# x: [b, 28, 28] => [b, 784]
# y: [b]
x = tf.reshape(x, [-1, 28*28])
# [b, 10]
logits = model(x)
# logits => prob, [b, 10]
prob = tf.nn.softmax(logits, axis=1)
# [b, 10] => [b], int64
pred = tf.argmax(prob, axis=1)
pred = tf.cast(pred, dtype=tf.int32)
# pred:[b]
# y: [b]
# correct: [b], True: equal, False: not equal
correct = tf.equal(pred, y)
correct = tf.reduce_sum(tf.cast(correct, dtype=tf.int32))
total_correct += int(correct)
total_num += x.shape[0]
acc = total_correct / total_num
print(epoch, 'test acc:', acc)