基于Redis的数据一致性
发布时间 2023-08-28 16:14:52作者: zhangliangddq
1. 分布式的环境下, MySQL和Redis如何保持数据的一致性?
解决方案: 延时双删
参考链接: https://www.zhihu.com/question/36413559
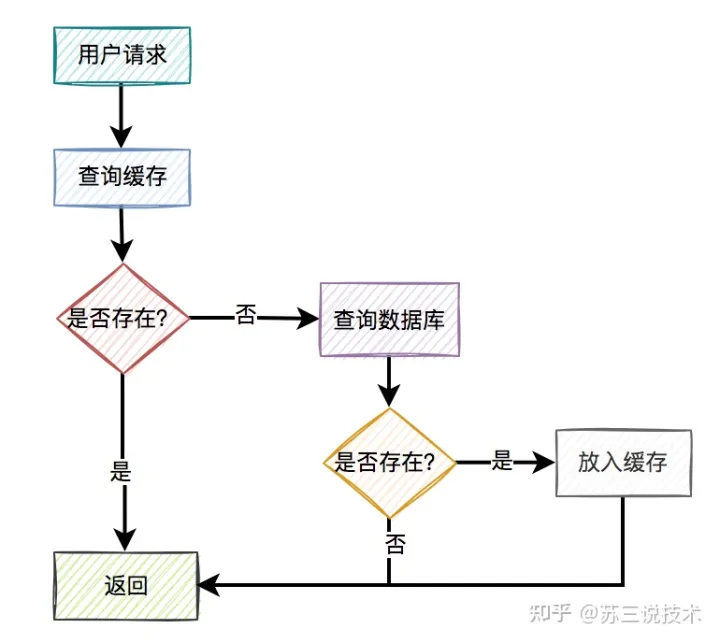
2.通常情况下的查询请求处理流程
3. 如果数据库中的某条数据值被更新了 那么将会更新对应的缓存数据 方案如下几种
- 先写缓存,再写数据库 -- 此时数据库网络异常,导致数据库失败就产生脏数据
- 先写数据库,再写缓存 -- 在非大事务场景下没问题
- 先删缓存,再写数据库 -- 高并发读写下会产生脏数据
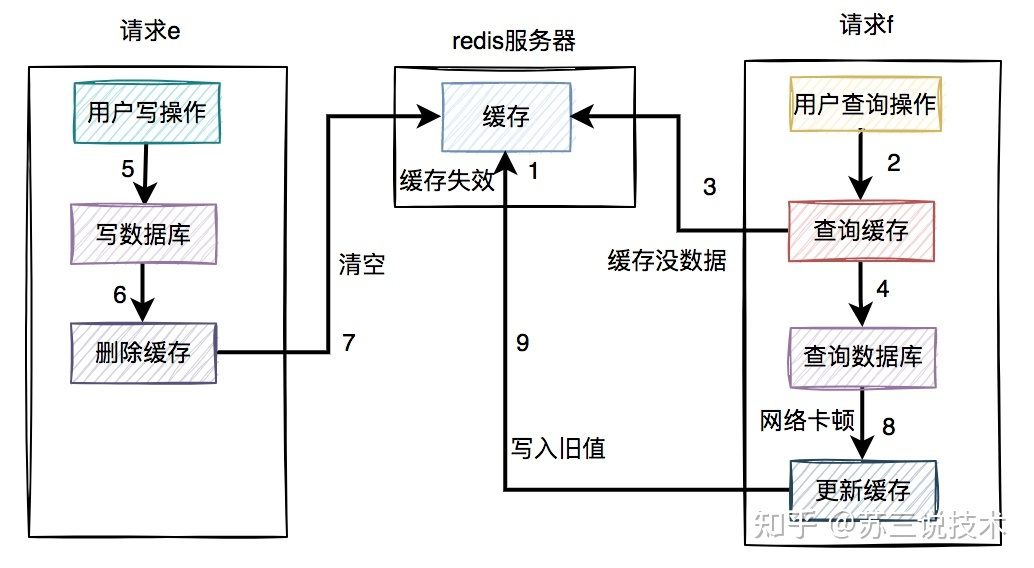
- 先写数据库,再删缓存 -- 主要是怕缓存自己失效了,例如时间到期,查询会查询数据并更新缓存 此时有可能会产生脏数据 如下图
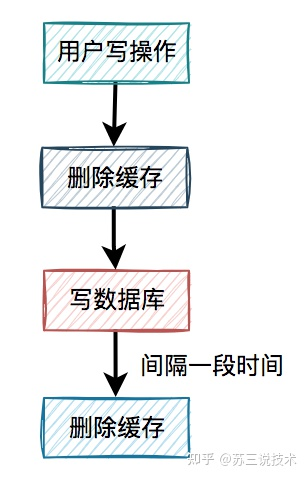
4. 延时双删
- 删除缓存
- 开启事务删除数据
- 等待一个业务查询的时间 再次删除缓存数据(最好的方式是将删除操作写入到MQ中)
5. 缓存删除失败的处理
- 每次都单独起一个线程,该线程专门做重试的工作。但如果在高并发的场景下,可能会创 建太多的线程,导致系统OOM问题,不太建议使用。
- 将重试的任务交给线程池处理,但如果服务器重启,部分数据可能会丢失。
- 将重试数据写表,然后使用elastic-job等定时任务进行重试。
- 将重试的请求写入mq等消息中间件中,在mq的consumer中处理。
- 订阅mysql的binlog,在订阅者中,如果发现了更新数据请求,则删除相应的缓存。