Peripheral Instance Augmentation for End-to-End Anomaly Detection Using Weighted Adversarial Learning
abstract
- 对边缘样本的实例学习不足,可能会导致较高的假阳性
- 提出方法用少量样本来指导对抗训练
- 应用加权生成模型生成边缘正常实例作为补充,以更好地学习正常类的特征,同时减少假阳性。
Introduction
-
大多数方法集中在提高异常检测的准确度,对假阳性关注不够。然后阐述了假阳性高的坏处
-
无监督方法由于缺乏标记数据,容易造成较多的假阳性
-
一些方法使用了标记异常数据。但是可能会学习正常实例的次优表示,因为它们无法捕获外围正常实例的特征,从而导致高假阳性。
-
下图为人造数据上,多个baseline的结果图。

- 外围正常实例只占数据的一小部分,很难正确预测。为了解决这个问题,我们引入了一个由异常分数学习器输出引导的加权生成模型,以生成额外的外围正常实例作为补充(见图1(c)中的绿点),以帮助异常分数学习器更好地找到正常类的代表性描述。如图f所示,我们的模型能够产生较高的检测精度和较低的假阳性。
优点:
- 通过生成外围正常实例作为补充,PIA-WAL能够捕获正常实例的复杂特征空间,同时减少false-positive。
- PIA-WAL将特征表示学习和异常评分优化结合在端到端模式中。
- 在不同的异常污染水平下,PIA-WAL始终比其他异常检测方法具有更强的鲁棒性。
贡献点:
- 据我们所知,这项工作是第一次将少量标记异常整合到对抗框架中,以实现端到端异常评分学习。
- 提出了一种新的异常检测模型PIA-WAL。在生成的外围正常实例的帮助下,检测器可以在准确检测异常的同时找到更有代表性的正常类描述。
- 在公开数据集和真实商业欺诈数据集上获得的结果表明,PIA-WAL比最先进的方法取得了实质性的改进。
前置知识(WGAN-GP)
GAN
生成器 \(G\) 对来自于先验噪声分布 \(P_z\) 的高维数据剑魔,以学习真实数据分布 \(P_r\);鉴别器 \(D\) 是一个二元分类器,它估计实例来自真实数据 \(x\) 而不是生成的假数据 \(G(z)\) 的概率。GAN的目标函数为 \(\min_G\max_D\mathbb{E}_{x\sim P_r}[logD(x)]+\mathbb{E}_{z\sim P_z}[log(1-D(G(z)))]\)
WGAN
WGAN的目标函数是
其中 \(\mathcal{D}\) 是 1阶Lipschitz函数的集合。为了在discriminator上执行Lipschitz约束,WGAN简单地将critic(即discriminator的变体)的权重限制在\([-c,c]\)。
WGAN-GP
然而,WGAN的权重限制总是由于没有仔细调整剪裁阈值 \(c\),导致梯度消失或爆炸。
考虑到这些问题,提出了通过引入梯度惩罚来实现WGAN-GP [13]约束。目标函数被定义为一个附加项,迫使梯度小于1:
式中 \(\lambda\) 为惩罚系数,\(P_{\hat{x}}\) 为从原始数据分布和生成数据分布中采样的点对之间沿直线的均匀抽样分布。
Method
问题

PIA_WAL
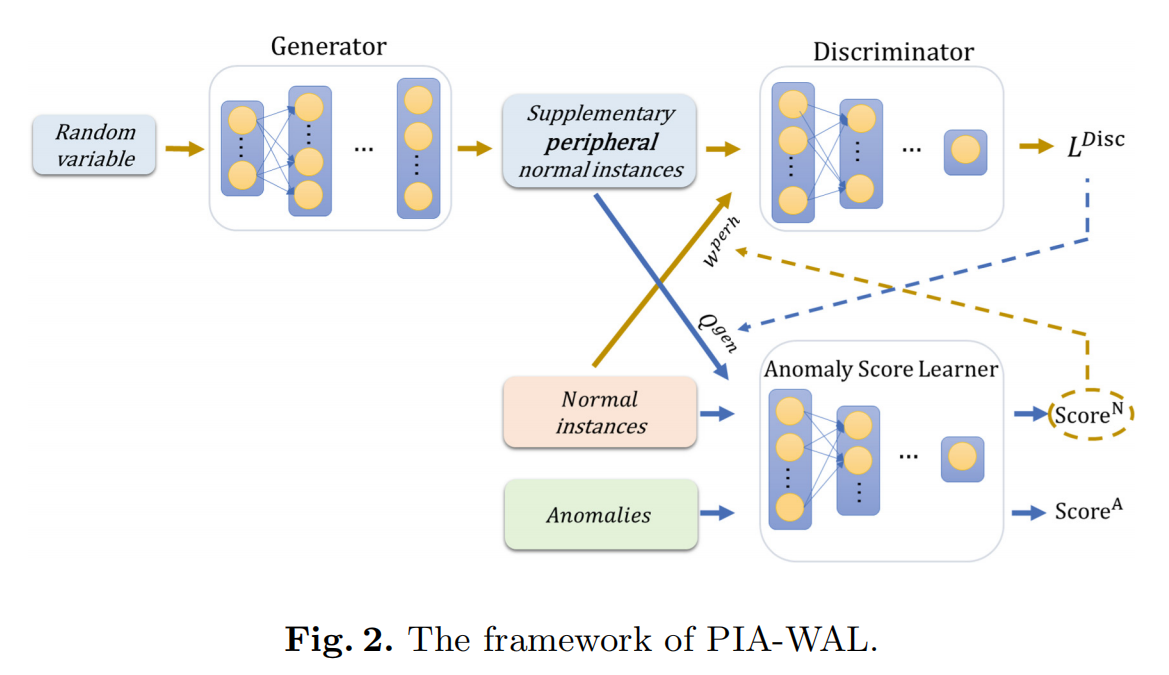
该模型由 异常评分学习器 和 加权生成模型 组成
Anomaly Score Learner
Learner对每个给定的输入产生一个异常分数,并定义一个参考分数来指导后续的异常分数学习。异常的分数被强制显著偏离正常的分数,位于分数分布的上尾。
考虑到高斯分布在各种数据集中的异常得分拟合得很, 我们使用标准高斯分布 \(S\sim N(0,1)\) 作为先验分布,并将参考分数设置为0。Anomaly Score Learner的损失函数如下:
其中 \(\varphi(\cdot)\) 表示异常分数网络的输出。
最小化损失函数会鼓励对所有异常情况产生较大的正偏差。因此,Leaner可以强制异常情况的分数明显偏离正常情况的分数,并位于分数分布的上尾。
异常分数高的正常实例表明它可能是学习者难以检测到的外围正常实例。或者是一个噪声。因此,我们利用异常分数来指导后续生成模型的学习过程。
Weighted Generative Model
为了实现引导实例的生成,我们利用Anomaly Score Learner的输出来计算一个正常实例是外围的程度,记为 \(w^{perh}\)。
其中 \(\mathbb{I}\) 是指示函数,\(|\varphi(x)|\) 是观察到的正常实例的异常评分的绝对值。当 \(|\varphi(x)|\) 超过 \(\alpha\)(即公式的参考分数)时则认为他是一个噪声。
为了使外围正常实例在指导生成器学习中发挥更重要的作用,我们将权重 \(w^{perh}\) 加入到鉴别器损失中。
我们使用 WGAN-GP作为基础生成模型,其鉴别器的损失函数为
Balanced Sampling
因为真实的外围正常实例可能只占mini-batch的极小部分,公式(6)中 \(w^{perh}\) 的作用可能会被减弱。我们采用抽样程序来确保 \(w^{perh}\) 在一个批次内的分布是均匀的。这样具有高 \(w^{perh}\) 权重的正常实例确实可以在生成器学习中发挥重要作用。
Generator’s Quality
WGAN的损失函数与生成是实例的质量存在良好的相关性。生成器的质量计算为
在训练集中包含生成的实例作为正常类的补充后,Anomaly Score Learner的损失函数被修改如下:
Outline of PIA-WAL
综上所述,PIA-WAL的总体目标函数写如下:
在算法1中概述了PIA-WAL的训练过程。

- Augmentation Peripheral End-to-End End Instanceaugmentation peripheral end-to-end end multi-instance entity-level end-to-end extraction end-to-end transformers end-to-end end detection line end-to-end end detection extraction end-to-end generation language predictron end-to-end end learning end-to-end end rfn-nest residual audio-driven end-to-end animation end peripheral