| 这个项目属于哪个课程 | 2023数据采集与融合技术 |
|---|---|
| 组名、项目简介 | 组名:普雷蒙奇、项目需求:多模态情感分析、项目目标:通过在网页中搜索关键词来得到一个综合的情感分析、项目开展技术路线:前端、python 、华为云平台 |
| 团队成员学号 | 102102112、102102115、102102116、102102118、102102119、102102120、102102156、102102159 |
| 这个项目目标 | 通过在网页中上传文本、图片、视频或音频分析其中的情感 |
| 其他参考文献 | [1]梁爱华,王雪峤 多模态学习数据采集与融合、[2]陈燕、赖宇斌 基于CLIP和交叉注意力的多模态情感分析模型 、[3]武星、殷浩宇 面向视频数据的多模态情感分析 |
项目整体介绍:
项目名称:国产手机情感分析
项目背景:近年来,国货新潮流兴起,华为Mate60系列供应链90%以上来自国内,消费者的真实反馈对于手机品牌口碑和市场表现至关重要,收集和分析消费者对于国产手机的反馈,不仅可以为用户提供一个选择手机品牌的依据,也可以为品牌提供有价值的建议和改进方向。
项目目标:通过采集和挖掘不同模态(文本、图片、音频)的数据,运用不同的情感分析模型,构造一个可以对国产手机各个方面进行多模态分析的系统,对国产手机品牌得到一个综合的情感分析,直观的感受到大众对于国产手机的的态度,以便于更好的判断国产手机中的“国货之光”。
项目具体流程图:
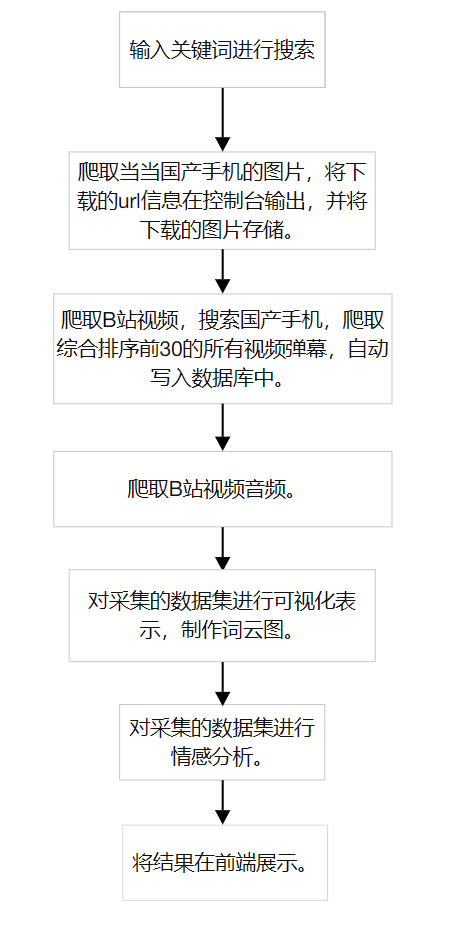
技术路线:
-
前端开发:
-
使用HTML、CSS和JavaScript进行前端的是界面设计,实现输入关键词后可以显示一个综合结果和词云图。
-
提升用户体验,使用动画效果和过渡效果,可以提高页面的交互性和吸引力。
-
-
后端开发:
-
使用python语言来实现后端开发的编写
-
使用Django框架来处理前端信息的接收,以及后端得到的信息返回
-
-
数据处理与分析:
-
文本爬取:
- 爬取B站弹幕和京东评论,但是京东评论在项目最后阶段爬取不到数据,所以只保留了弹幕的爬取。
- 采用request库的findall()函数获取指定cid的弹幕,并通过正则表达式提取出弹幕文本。
-
图片爬取:
- 爬取当当网的图片。
- 使用requests库的findall()函数和正则表达式取所有满足条件的图片链接。
- 并使用多线程机制将图片进行下载。
-
音/视频爬取:
- 爬取B站相关视频。
- 采用request库的findall()函数和正则表达式提取JSON中BV号。
- 使用正则表达式和json库获取视频和音频的url。
- 使用requests库来下载视频和音频文件。
-
文本分析: 首先考虑ERNIE-UIE文心模型,可是配置不成功,导致没有结果显示。接着考虑讯飞的情感分析模型,发现只能单句分析,不太符合需求,最后考虑百度云的API接口。
-
视频和音频分析:
- 对B站相关视频进行爬取,得到视频和音频。
- 使用Whisper方法将音频转为文本。
- 对上传的音频文件进行特征提取和情感识别。
-
图片分析:
- 使用预训练的BERT模型进行图像处理。
- 使用预训练的ResNet-50提取图片特征。
- 将图像特征输入到分类器中进行预测。
-
-
结果输出与展示:将分析结果通过前端界面展示。
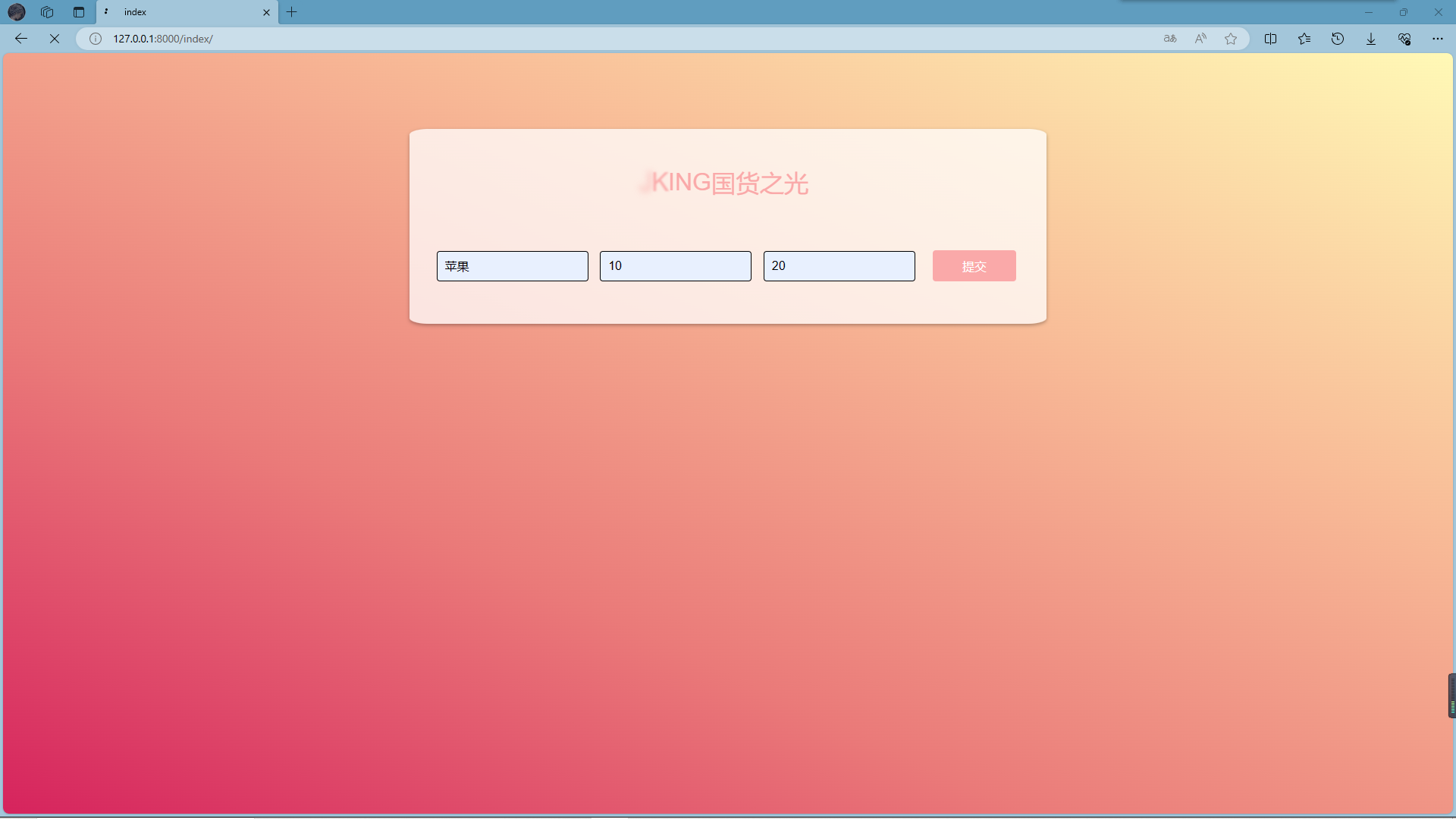
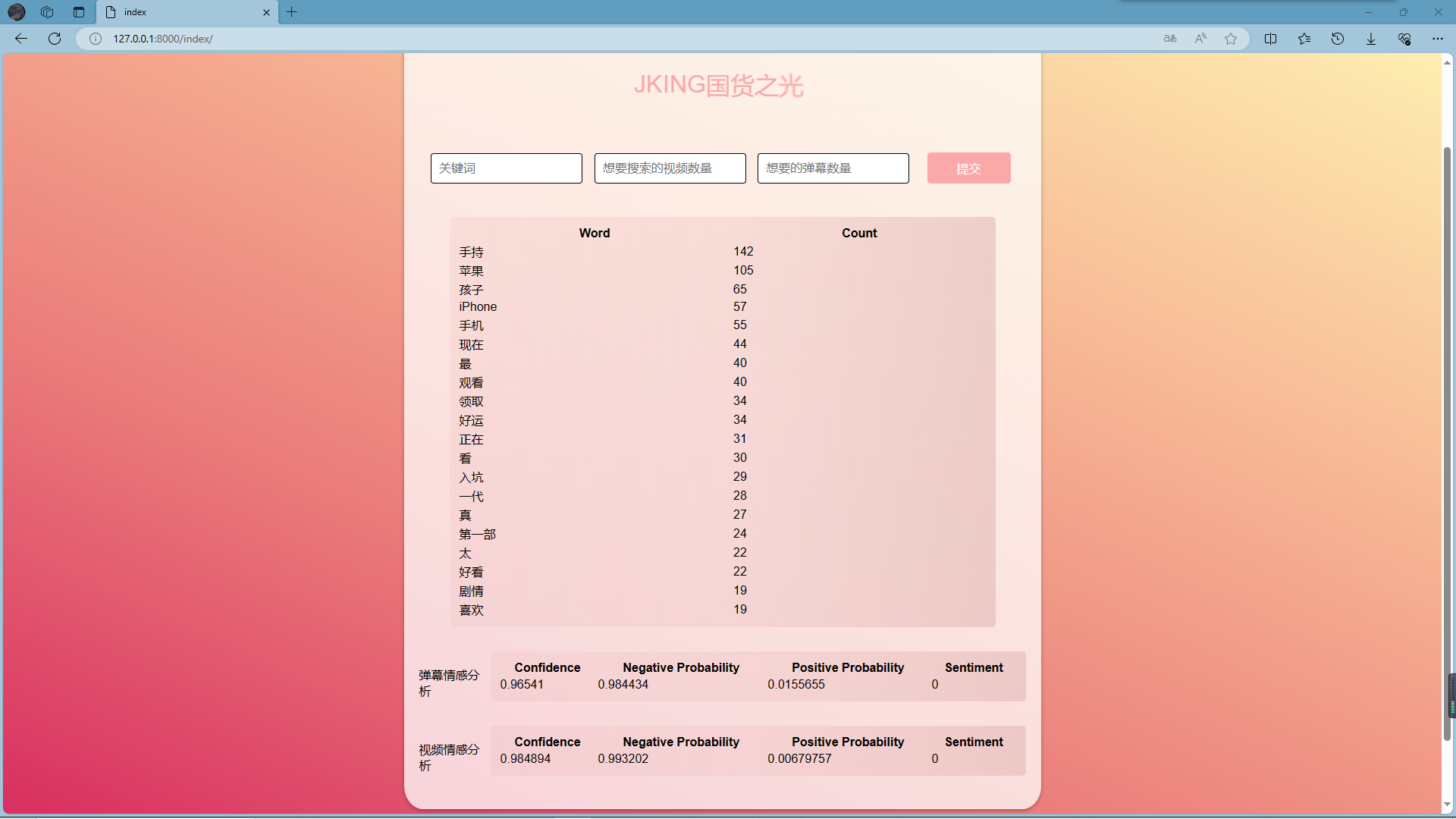
个人分工
初次开会,由王俊凯同学分工为去寻找合适的模型,所以他、我和另一位组员负责,后面认识到一些模型之后,主要由王俊凯同学去跑模型验证哪个模型有可行性;后面任务又发生改变,去采集所需要的数据,一开始在找模型阶段,期间有修改其他组员初始代码,去尝试爬取王俊凯同学需要的数据,所以等模型确定之后,我和另一位组员主要负责是采集数据,所需要的文本、图像、视频、音频等。总体上,我的个人分工有三大部分:
1. 寻找合适的模型可以实现对多源异构数据的情感分析
- 讯飞星火API:做软工实践答辩的时候,听到有人使用现成的,只需调用API就好,所以就去找了讯飞,申请了一个尝试一下,之后发现只会简单的调用,再高级的不会用,然后就没然后了...
- 百度模型库——ERNIE-UIE:该框架实现了实体抽取、关系抽取、事件抽取、情感分析等任务的统一建模,发现重点可以进行情感分析。这个应该是针对文本的,并且它这个情感倾向就很直接,就是“正向”或者“负向”,没有一个比较的程度,但是还是准备尝试一下,情感分析的结果,准备环境,安装PaddleNLP,在Pycharm上运行
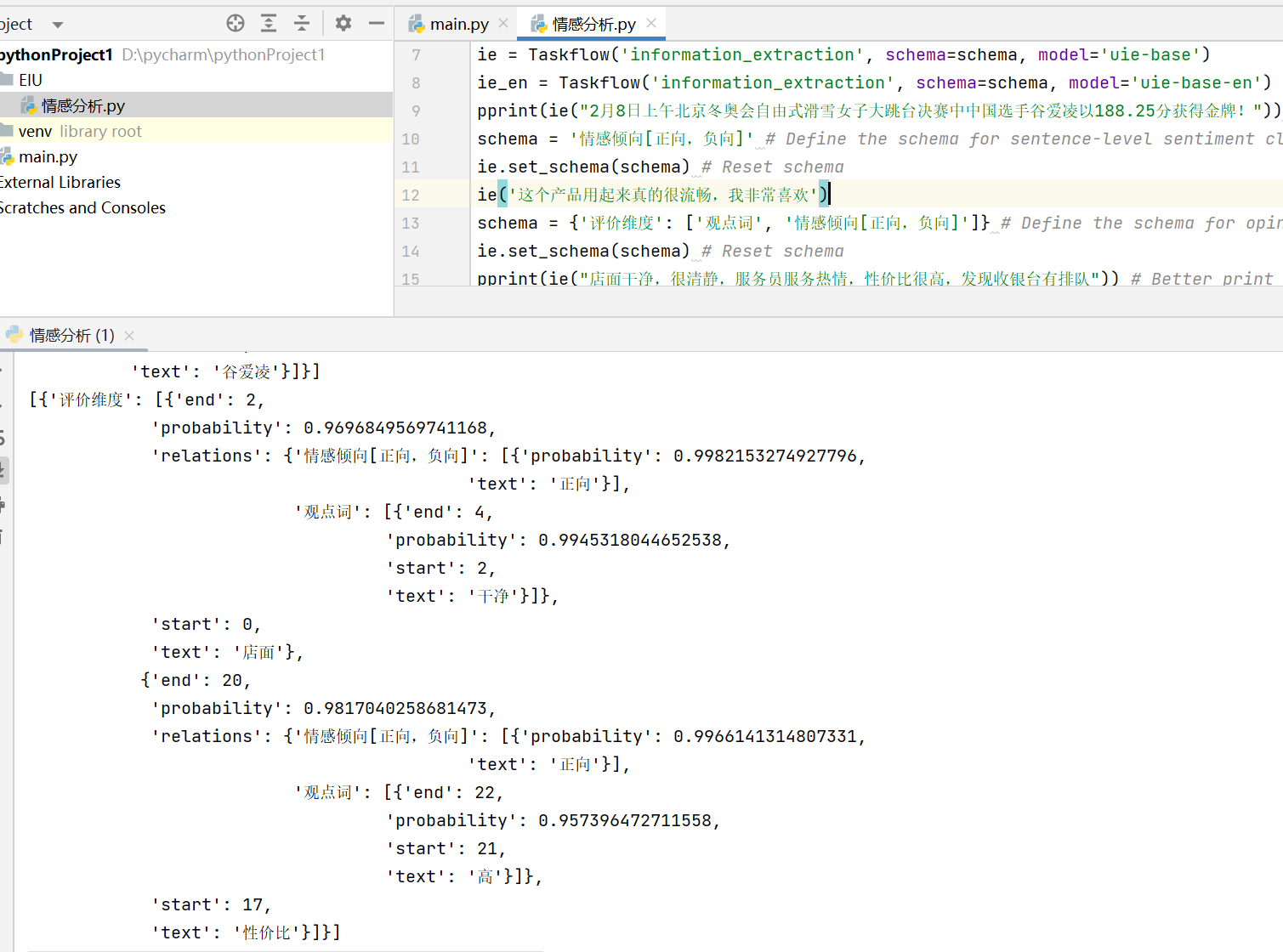
-
多模态情感分析模型VistaNet:VistaNet 利用 Attention 机制进行图像与文本信息的融合,巧妙的解决了不同模态数据的向量空间不一致问题,增强了模型针对评论的情感分析的能力。这个在一篇CSDN里有介绍怎么代码实现,先搭建三个层Word Encoder + Attention、Sentence Encoder + Attention、Document Encoder + Attention,还使用了VGG-16,之后就开始整体模型的搭建,能力有限最后没有修改出来。
-
基于卷积神经网络的图像情感分析:一开始组长也提到这,因为我们机器学习的中期竞赛就用到了卷积神经网络处理图像,但是那个在网上有较多的教程,这个图像情感分析就比较少(ps:个人能力的问题,找不到),有一个是使用Keras框架实现的,还没开始尝试就在GitHub上发现了一个可以实现更多功能的情感分析的项目,就是下面这个基于TensorFlow实现的多模态情感分析。
-
基于TensorFlow实现的多模态情感分析:在Github找到的,使用多模态模型进去情感识别,输入有文本、语言、图片和视频,感觉非常符合实现我们这个项目的需求,但是组长试验过后发现有些问题。
2. 采集数据
- 京东评论:通过稍作修改李子慕同学编写fenleipinglun.py的内容,并重新命名为爬取京东评论.py,可以通过关键字进行爬取相关品牌的用户评论。这里由于前期计划是国产品牌,所以没有局限于手机品牌。

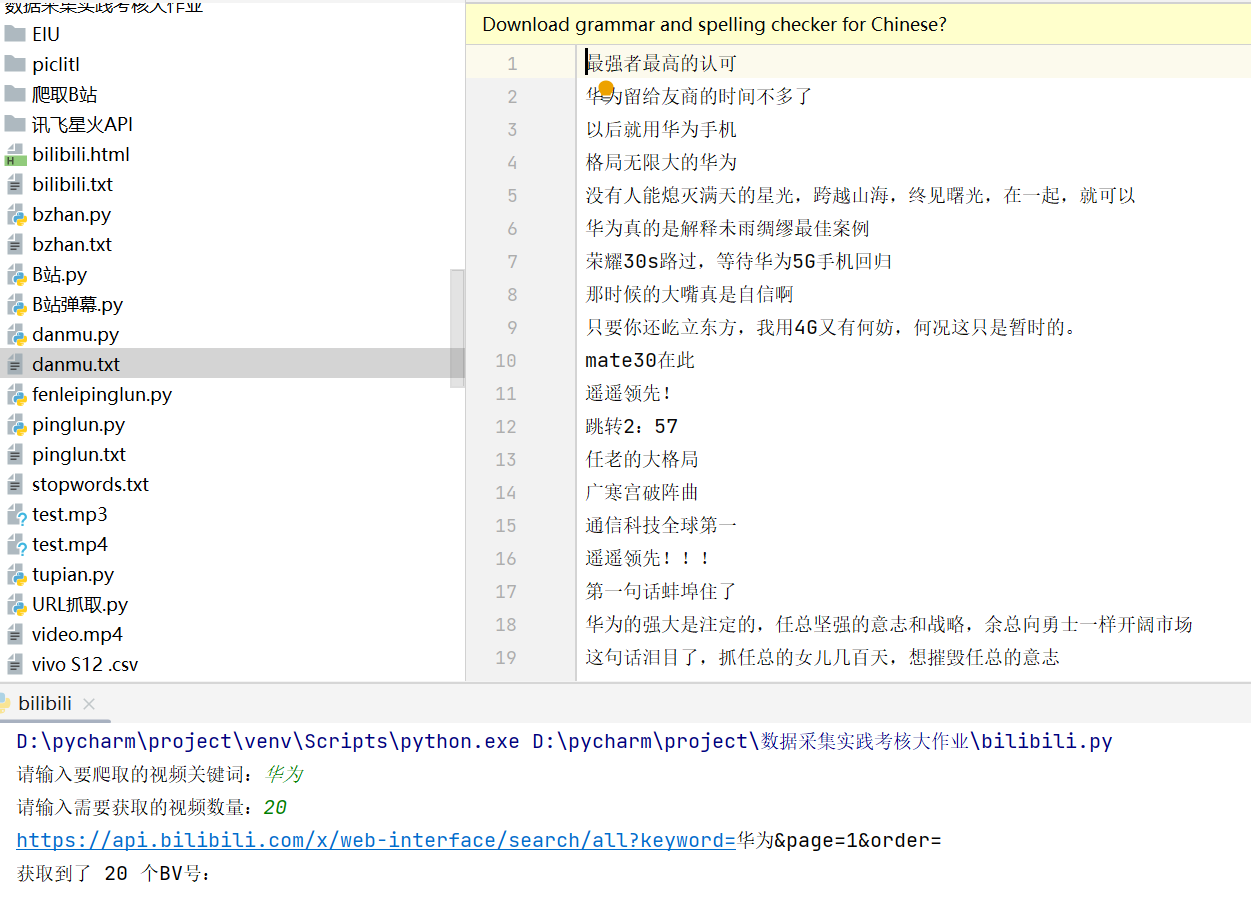
- B站视频弹幕:这个其他课程作业写过代码,所以有现成的代码,只需稍作修改,把源代码中的统计词频并绘制词云图去掉即可,通过输入指定关键字可以爬取想要的B站弹幕。获取弹幕代码:
def getdm(url, content_list): # 从指定url获取弹幕存储在content_list
headers = { # 请求表头
'user-agent': ''
}
response = requests.get(url=url, headers=headers) # 发送请求
response.encoding = 'utf-8' # 解决乱码
content = re.findall('<d p=".*?">(.*?)</d>', response.text) # 正则表达式找出想要的内容
for dms in content:
content_list.append(dms)
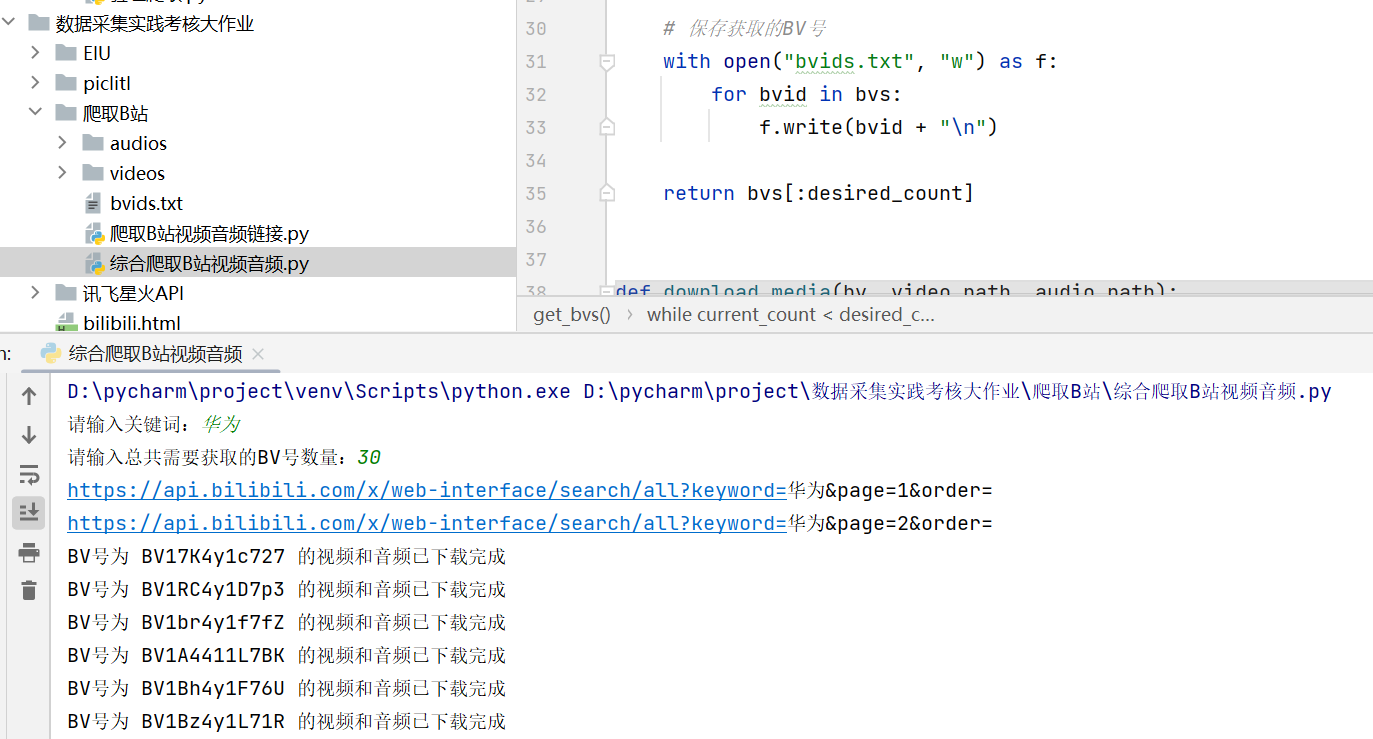
- B站视频音频:好吧,这个是第一次尝试,也是才知道B站的视频是与音频分开的,如果合在一起还需要其他工具ffmpeg合并,但是本来也需要用到音频,这不就刚刚好。通过关键字搜索,然后得到视频号bv,这样就可以实现爬取多个视频号了,下载视频音频代码实现:
def download_media(bv, video_path, audio_path):
url = f'https://www.bilibili.com/video/{bv}/'
header = {
"User-Agent": "",# 这里先删除了
"Referer": "https://www.bilibili.com/", # 设置防盗链
}
resp = requests.get(url=url, headers=header)
obj = re.compile(r'window.__playinfo__=(.*?)</script>', re.S)
html_data = obj.findall(resp.text)[0] # 从列表转换为字符串
json_data = json.loads(html_data)
videos = json_data['data']['dash']['video'] # 这里得到的是一个列表
video_url = videos[0]['baseUrl'] # 视频地址
audios = json_data['data']['dash']['audio']
audio_url = audios[0]['baseUrl'] # 音频地址
resp1 = requests.get(url=video_url, headers=header)
with open(os.path.join(video_path, f'{bv}.mp4'), mode='wb') as f:
f.write(resp1.content)
resp2 = requests.get(url=audio_url, headers=header)
with open(os.path.join(audio_path, f'{bv}.wav'), mode='wb') as f:
f.write(resp2.content)
print(f"BV号为 {bv} 的视频和音频已下载完成")
运行之后把视频和音频保存到相应文件夹里,效果:
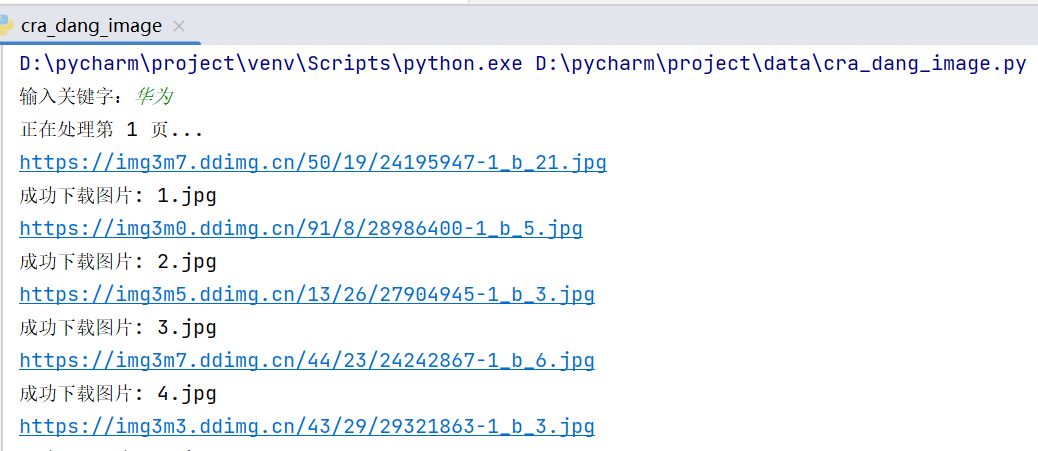
- 当当网商品图片:这个主要用于图像分析,以前作业有做过,所以可以直接拿来用。原先计划是通过京东评论区图片,但是改不出来代码实现,所以退而求其次还是原来的。幸好当当图片结构还是没变:
def get_image_urls(keyword, page):
base_url = 'http://search.dangdang.com/'
params = {
'key': keyword,
'act': 'input',
'page_index': page
}
headers = {
"User-Agent": "" # 暂且删掉
}
response = requests.get(base_url, headers=headers, params=params)
text = response.text# 获取网页内容的文本格式
# print(text) # 打印出来网页内容,查看商品图片链接
# 每页发现前8个商品图片链接与后面的52个商品链接不一样,因此需要将两个图片链接列表合并为一个,以便获取到所有的图片链接
# 使用正则表达式提取图片链接
urls = re.findall("<img src='(.*?)' alt", text) # 前8个链接
url2 = re.findall("img data-original='(.*?)' src", text) #后52个链接
urls.extend(url2) # 合并操作
# print(urls) # 打印所有图片链接
return urls
3.PPT制作
PPT制作主力军,怎么说呢,很少做过PPT,但愿还可以。
心得体会
-
这次实践项目主要从多源异构数据的采集和融合和数据采集、数据分析和处理模型应用和应用平台搭建三个方面全流程闭环做一个整体设计和实践。我们团队主要是通过国产手机品牌进行情感分析。在项目初期,我们对于老师要求的设计内容不是很理解,自选多模态采集与融合应用任务、网页端采集多源异构数据、应用深度学习的模型(CNN,RNN,VE等)或者大模型(例如:文心一言)进行数据特征提取和融合和简单快速地搭建轻量级的网站系统应用平台(例如:flask库)。甚至一开始我们以为不是所有都要实现,而是选取其中的实现,但是发现并不是的,而是完成这些要求去设计出一个交互友好的多源异构数据的采集与融合的小应用。然后我们初步构想为国产手机品牌,但是因为初期没有做出好的计划去实现,在经过初次分工之后,我们的目标有所偏移。一开始定的是国产手机,后面中期变成国产品牌,不但是手机类别,中后期发现要实现这个有点困难,并且没能够计划好实现的难度级别,最后中道崩阻,又改为了国产手机。在这方面我深刻感受到,想要做好一个项目,要坚定目标,即在确定要实现什么样的项目时,要做充分地调研以及考虑好整个团队能力、可在这个项目操作的时间并结合截止时间去确定项目实现难度。
-
在这个项目实现的过程中,完成个人所承担的寻找模型和数据采集,在寻找模型期间,资源还是挺重要的,老师也发布了很多资料还有学习课程,所以要充分利用资源和工具,GitHub是个好工具,可以多找找;对于采集数据,幸好前面的作业都有很好的完成,加上选修的软工也有一个作业是爬取B站的弹幕,所以在这方面帮助很大,也算省了一些力。所以个人认为在结合个人能力的范围下有很好的完成组长交代的任务,并且去主动与组长沟通项目进度,以及还有哪些没有完成,自己还可以去承担哪些任务,比如在最后博客环节,根据老师发布的要求,初步整理出项目基本信息和项目整体介绍两部分框架主体,方便组长及其他成员完善具体内容。
-
总体上,从个人承担的任务上,学习到了查资料要灵活运用所有的资源,不要单单固定到浏览器,有时候换个设备,它所给出的内容都不一样,所以要多尝试,就是对模型的应用还是不会;巩固了数据采集知识,在B站弹幕、视频音频这方面有了更深的理解,B站弹幕这个其他可以课程作业完成过,可以直接拿来用,但是真没想到自己可以完成B站视频音频的爬取,哈哈哈哈这门课没白学;也体会到开会、交流沟通对团队合作、推进项目进度的重要性。