作业一
要求
- 熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
- 使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
候选网站
输出信息:
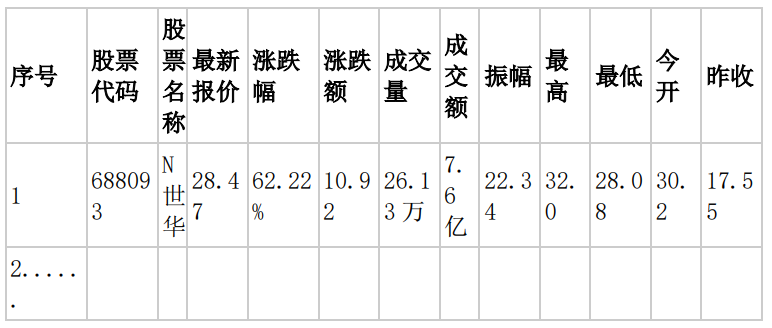
- MYSQL 数据库存储和输出格式如下,表头应是英文命名例如:序号,id,股票代码:bStockNo……,由同学们自行定义设计表头:
思路
- Selenium可以直接爬取网站。
代码
shijian4_1.py
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium import webdriver
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
import time
import csv
def csv_init():
csv_file = open('stock_data.csv', 'w', newline='', encoding='utf-8')
csv_writer = csv.writer(csv_file)
csv_writer.writerow(['股票代码', '名称', '最新价', '涨跌幅', '涨跌额', '成交量', '成交额', '振幅', '最高', '最低', '今开', '昨收', '量比', '换手率', '市盈率', '市净率'])
return csv_writer, csv_file
def driver_init():
# "Q:\Program Files\scoop\apps\chromedriver\118.0.5993.70\chromedriver.exe"
# options = Options()
# options.binary_location = chrome_path
# s = Service(chrome_path)
driver = webdriver.Chrome()
return driver
def crawl(driver, csv_writer):
# 上证A股
button_sh = driver.find_element(By.CSS_SELECTOR, 'li[id="nav_sh_a_board"] > a')
button_sh.click()
time.sleep(3)
button_next = driver.find_element(By.CSS_SELECTOR, 'a[class="next paginate_button"]')
while button_next:
data = driver.page_source
saveToCSV(data, csv_writer)
print(button_next)
button_next.click()
time.sleep(3)
try:
button_next = driver.find_element(By.CSS_SELECTOR, 'a[class="next paginate_button"]')
except:
break
def saveToCSV(data, csv_writer):
bs = BeautifulSoup(data, 'lxml')
table = bs.select_one('table[id="table_wrapper-table"]')
table_body = table.select("tbody > tr")
for tr in table_body:
imformations = [x.text for x in tr]
imformations.pop(3)
imformations.pop(-1)
csv_writer.writerow(imformations[1:])
print(imformations[1:]) # 输出到控制台
def spider(driver, csv_writer):
main_url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board"
driver.get(main_url)
time.sleep(3)
crawl(driver, csv_writer)
def end(driver):
driver.close()
if __name__ == "__main__":
try:
csv_writer, csv_file = csv_init()
driver = driver_init()
spider(driver, csv_writer)
except Exception as e :
print(e)
finally:
end(driver)
csv_file.close()
运行截图
保存为csv文件便于查看,实际上代码没什么差别

心得体会
- 因为之前有做过相关的内容,所以这个做起来难度不是特别大,算是巩固知识吧
作业二
要求
- 熟练掌握 Selenium 查找 HTML 元素、实现用户模拟登录、爬取 Ajax 网页数据、
- 等待 HTML 元素等内容。
候选网站
输出信息:
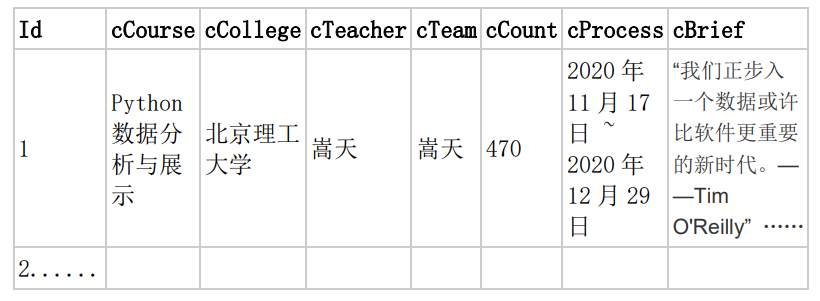
- MYSQL 数据库存储和输出格式
思路
- 由于mooc平台课程过多,于是选择爬取所有的国家精品课程
代码
shijian4_2.py
import csv
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
def saveToCSV(courses):
with open('Mooc.csv', 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = ['ID', '课程名', '学校', '老师', '团队', '参与人数', '进度', '简介']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for course in courses:
writer.writerow({
'ID': course[0],
'课程名': course[1],
'学校': course[2],
'老师': course[3],
'团队': course[4],
'参与人数': course[5],
'进度': course[6],
'简介': course[7]
})
def jinrujiemian(key):
driver = webdriver.Chrome()
driver.get("https://www.icourse163.org/")
time.sleep(10)
keyInput = driver.find_element(By.XPATH, "/html/body/div[4]/div[1]/div/div/div/div/div[7]/div[1]/div/div/div[1]/div/div/div/div/div/div/input")
keyInput.send_keys(key)
keyInput.send_keys(Keys.ENTER)
time.sleep(10)
tag = 1
Id = 1
courses = []
while tag == 1:
WebDriverWait(driver, 1000).until(
EC.presence_of_all_elements_located(
(By.ID, "j-courseCardListBox")
)
)
driver.execute_script('document.documentElement.scrollTop=10000')
lis = driver.find_elements(By.XPATH,'//div[@class="u-clist f-bgw f-cb f-pr j-href ga-click"]')
for li in lis:
try:
cCourse = li.find_element(By.XPATH,'.//span[@class=" u-course-name f-thide"]').text
except Exception as err:
cCourse = 'only'
try:
cCollege = li.find_element(By.XPATH,'.//a[@class="t21 f-fc9"]').text
except Exception as err:
cCollege = 'only'
try:
cTeacher = li.find_element(By.XPATH,'.//a[@class="f-fc9"]').text
except Exception as err:
cTeacher = 'only'
try:
cTeam = li.find_element(By.XPATH,'.//span[@class="f-fc9"]').text
except Exception as err:
cTeam = 'only'
try:
cCount = li.find_element(By.XPATH,'.//span[@class="hot"]').text
cCount.replace('参加','')
except Exception as err:
cCount = 'only'
try:
cProcess = li.find_element(By.XPATH,'.//span[@class="txt"]').text
cProcess.replace('进度:','')
except Exception as err:
cProcess = 'only'
try:
cBrief = li.find_element(By.XPATH,'.//span[@class="p5 brief f-ib f-f0 f-cb"]').text
except Exception as err:
cBrief = 'only'
courses.append((Id, cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief))
Id += 1
try:
next_page_element = driver.find_element(By.XPATH, "/html/body/div[4]/div[2]/div[2]/div[2]/div/div[6]/div[2]/div[2]/ul/li[10]/a[@class='th-bk-main-gh']")
next_page_element.click()
except:
tag = 0
saveToCSV(courses)
driver.close()
jinrujiemian("计算机")
运行截图
同样保存为csv文件便于查看,db文件代码的话相差无几

心得体会
- 使用click来执行翻页的操作,对于Xpath的使用更进一步,可惜没有实现老师设想中的登录功能
作业③
要求
- 掌握大数据相关服务,熟悉 Xshell 的使用
- 完成文档 华为云_大数据实时分析处理实验手册-Flume 日志采集实验(部分)v2.docx 中的任务,即为下面 5 个任务,具体操作见文档。
环境搭建
- 任务一:开通 MapReduce 服务

实时分析开发实战
-
任务一:Python 脚本生成测试数据

-
任务二:配置 Kafka

-
任务三: 安装 Flume 客户端

-
任务四:配置 Flume 采集数据

心得体会
- 学会了运用华为公有云的MRS服务,了解了Flume的作用和环境搭建的过程。
- 跟着老师的教程走,虽然版本变化了,但还是非常顺利地完成了。