Stable-Diffusion-webUI 代码阅读02 —— 按钮?按一下!
由于实习工作需要,决定用几天时间阅读一遍stable-diffusion-webui的代码。
本文参考知乎专栏,并且添加了一些自己的理解,感谢大佬!知乎专栏:自动做游戏:AI技术落地于游戏开发 - 知乎 (zhihu.com)
最近工作主要侧重于OneFlow框架应用于SD的加速和不同Sampler的支持适配的工作,所以阅读代码也将其作为切入点。
由于本人刚刚入门,故许多内容比较粗糙,有问题希望多多批评指正!
webui本身更新较快,本文所阅读的内容为 AUTOMATIC1111大佬的1.4.1,这里是项目地址
点击了txt2img之后...
按钮位置
接上一篇文章代码阅读01的末尾部分,可以在modules\ui.py的create_ui函数中找到txt2img的模块(末尾有代码块)
由于我是小白,对于js不是很熟练,只能通过函数和变量的命名来推断对应的UI部分,锁定了如下的代码块:
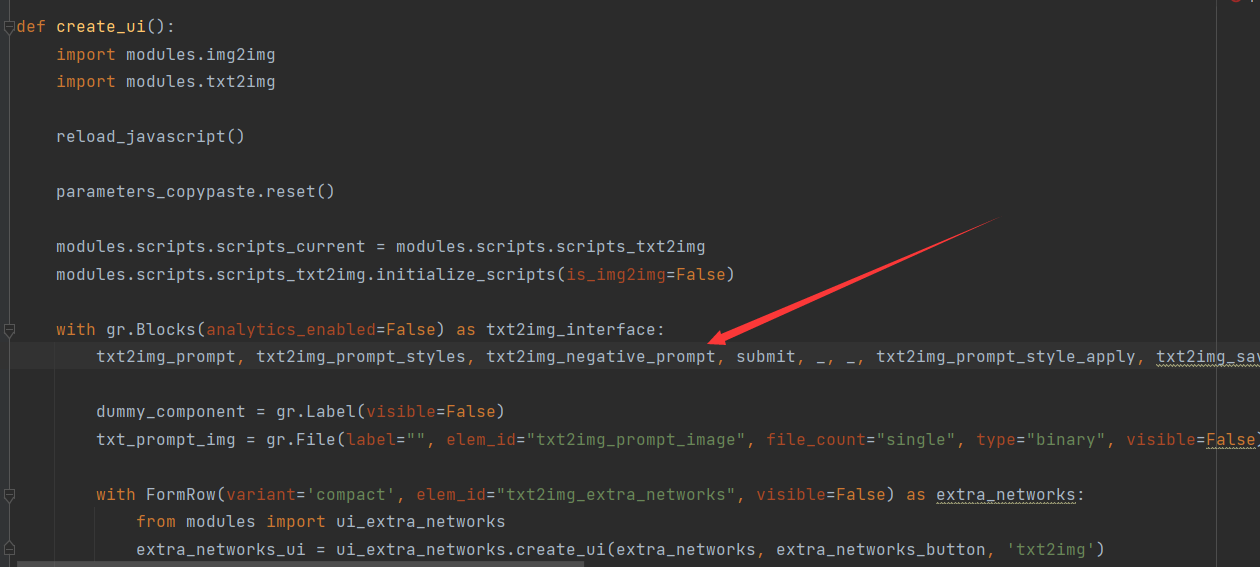
txt2img_prompt, txt2img_prompt_styles, txt2img_negative_prompt, submit, _, _, txt2img_prompt_style_apply, txt2img_save_style, txt2img_paste, extra_networks_button, token_counter, token_button, negative_token_counter, negative_token_button, restore_progress_button = create_toprow(is_img2img=False)
虽然这一行很长,但是可以看得出来,webUI对于generate,skip等按钮是做了顶层模块化的,因为他们无论是在txt2img,还是img2img等位置都有。
于是顺着代码,我们找到create_toprow
def create_toprow(is_img2img):
id_part = "img2img" if is_img2img else "txt2img"
with gr.Row(elem_id=f"{id_part}_toprow", variant="compact"):
with gr.Column(elem_id=f"{id_part}_prompt_container", scale=6):
with gr.Row():
with gr.Column(scale=80):
with gr.Row():
prompt = gr.Textbox(label="Prompt", elem_id=f"{id_part}_prompt", show_label=False, lines=3, placeholder="Prompt (press Ctrl+Enter or Alt+Enter to generate)", elem_classes=["prompt"])
with gr.Row():
with gr.Column(scale=80):
with gr.Row():
negative_prompt = gr.Textbox(label="Negative prompt", elem_id=f"{id_part}_neg_prompt", show_label=False, lines=3, placeholder="Negative prompt (press Ctrl+Enter or Alt+Enter to generate)", elem_classes=["prompt"])
button_interrogate = None
button_deepbooru = None
if is_img2img:
with gr.Column(scale=1, elem_classes="interrogate-col"):
button_interrogate = gr.Button('Interrogate\nCLIP', elem_id="interrogate")
button_deepbooru = gr.Button('Interrogate\nDeepBooru', elem_id="deepbooru")
with gr.Column(scale=1, elem_id=f"{id_part}_actions_column"):
with gr.Row(elem_id=f"{id_part}_generate_box", elem_classes="generate-box"):
interrupt = gr.Button('Interrupt', elem_id=f"{id_part}_interrupt", elem_classes="generate-box-interrupt")
skip = gr.Button('Skip', elem_id=f"{id_part}_skip", elem_classes="generate-box-skip")
submit = gr.Button('Generate', elem_id=f"{id_part}_generate", variant='primary')
skip.click(
fn=lambda: shared.state.skip(),
inputs=[],
outputs=[],
)
interrupt.click(
fn=lambda: shared.state.interrupt(),
inputs=[],
outputs=[],
)
with gr.Row(elem_id=f"{id_part}_tools"):
paste = ToolButton(value=paste_symbol, elem_id="paste")
clear_prompt_button = ToolButton(value=clear_prompt_symbol, elem_id=f"{id_part}_clear_prompt")
extra_networks_button = ToolButton(value=extra_networks_symbol, elem_id=f"{id_part}_extra_networks")
prompt_style_apply = ToolButton(value=apply_style_symbol, elem_id=f"{id_part}_style_apply")
save_style = ToolButton(value=save_style_symbol, elem_id=f"{id_part}_style_create")
restore_progress_button = ToolButton(value=restore_progress_symbol, elem_id=f"{id_part}_restore_progress", visible=False)
token_counter = gr.HTML(value="<span>0/75</span>", elem_id=f"{id_part}_token_counter", elem_classes=["token-counter"])
token_button = gr.Button(visible=False, elem_id=f"{id_part}_token_button")
negative_token_counter = gr.HTML(value="<span>0/75</span>", elem_id=f"{id_part}_negative_token_counter", elem_classes=["token-counter"])
negative_token_button = gr.Button(visible=False, elem_id=f"{id_part}_negative_token_button")
clear_prompt_button.click(
fn=lambda *x: x,
_js="confirm_clear_prompt",
inputs=[prompt, negative_prompt],
outputs=[prompt, negative_prompt],
)
with gr.Row(elem_id=f"{id_part}_styles_row"):
prompt_styles = gr.Dropdown(label="Styles", elem_id=f"{id_part}_styles", choices=[k for k, v in shared.prompt_styles.styles.items()], value=[], multiselect=True)
create_refresh_button(prompt_styles, shared.prompt_styles.reload, lambda: {"choices": [k for k, v in shared.prompt_styles.styles.items()]}, f"refresh_{id_part}_styles")
return prompt, prompt_styles, negative_prompt, submit, button_interrogate, button_deepbooru, prompt_style_apply, save_style, paste, extra_networks_button, token_counter, token_button, negative_token_counter, negative_token_button, restore_progress_button
同样地,我们依旧是排除没用的部分,直接去定位"Generate"按钮,
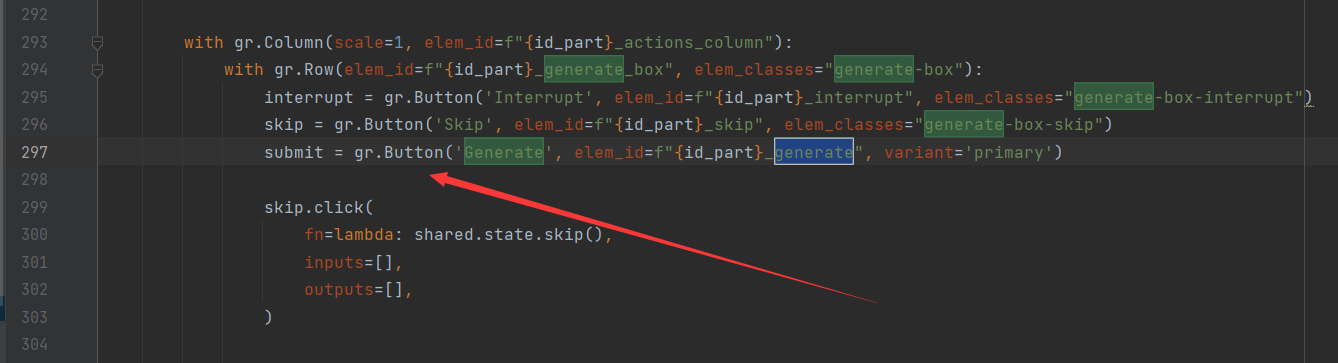
可以看得到,这个按钮所绑定的变量为submit
submit事件
通过全局搜索的方式,最终找到了这个submit的点击事件
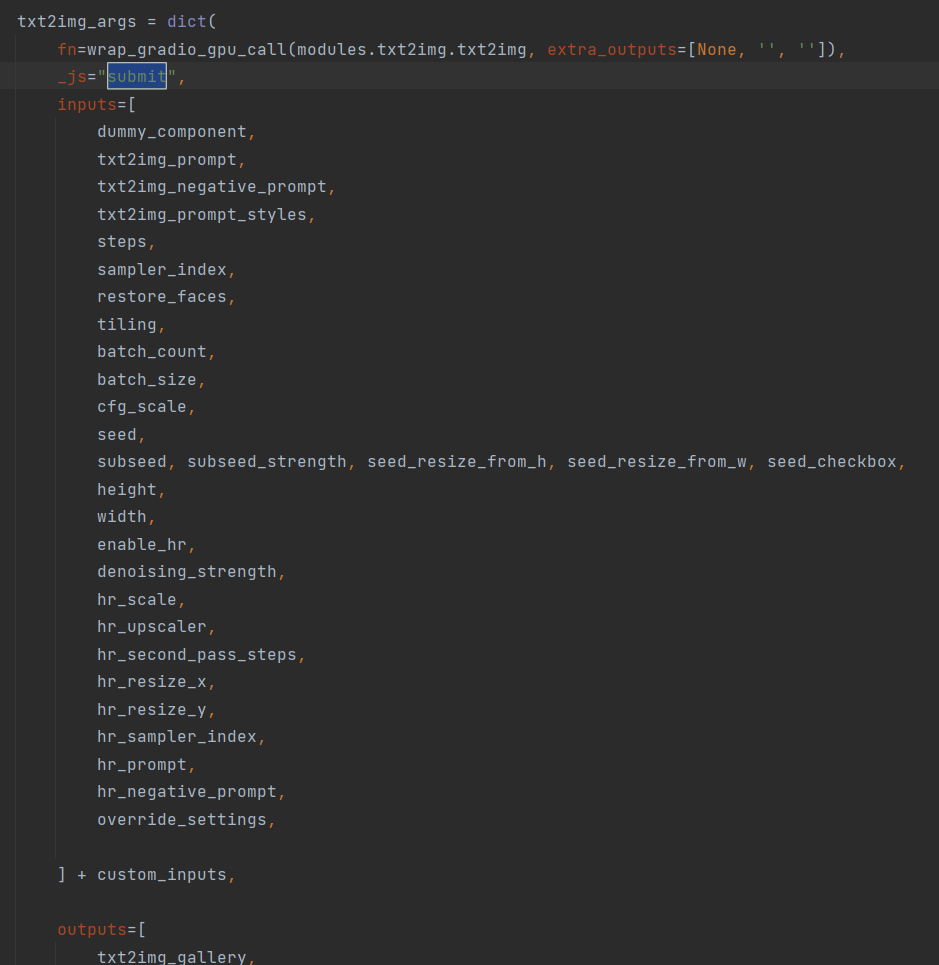
函数的在webui.py 的create_ui()函数里
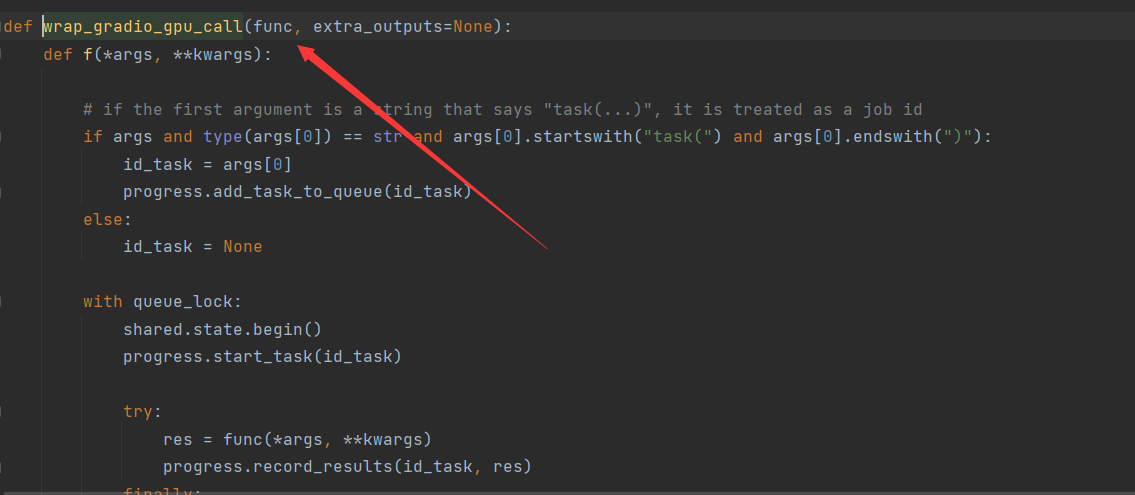
wrap_gradio_gpu_call
观察这个函数,发现执行了wrap_gradio_gpu_call这个方法,此方法:
# \modules\call_queue.py
def wrap_gradio_gpu_call(func, extra_outputs=None):
def f(*args, **kwargs):
# if the first argument is a string that says "task(...)", it is treated as a job id
if args and type(args[0]) == str and args[0].startswith("task(") and args[0].endswith(")"):
id_task = args[0]
progress.add_task_to_queue(id_task)
else:
id_task = None
with queue_lock:
shared.state.begin()
progress.start_task(id_task)
try:
res = func(*args, **kwargs)
progress.record_results(id_task, res)
finally:
progress.finish_task(id_task)
shared.state.end()
return res
return wrap_gradio_call(f, extra_outputs=extra_outputs, add_stats=True)
可以发现,此方法是给wrap_gradio_call的一个包裹,在下一个小节会介绍这部分的代码。
可以看到,代码里加入了queue_lock,此队列为多个用户一起执行生成任务的时候,满足先来后到的排队要求,根据锁的方式来满足任务的独立。
此部分代码包裹的目的为排队,即保证先到先服务。
但是这里其实是有问题的,我和师兄在进行尝试时就发现过,模型的切换会出现问题。
在参考了知乎大佬的博客后,很巧合地他谈及了这个问题,这个问题主要原因是,input的参数并不包含全部信息,比如不包含模型名,当不同的两个用户切换模型时,就会发生冲突。而不同的一些插件的加载也容易破坏队列任务中的参数。
wrap_gradio_call
def wrap_gradio_call(func, extra_outputs=None, add_stats=False):
def f(*args, extra_outputs_array=extra_outputs, **kwargs):
run_memmon = shared.opts.memmon_poll_rate > 0 and not shared.mem_mon.disabled and add_stats
if run_memmon:
shared.mem_mon.monitor()
t = time.perf_counter()
try:
res = list(func(*args, **kwargs))
except Exception as e:
# When printing out our debug argument list,
# do not print out more than a 100 KB of text
max_debug_str_len = 131072
message = "Error completing request"
arg_str = f"Arguments: {args} {kwargs}"[:max_debug_str_len]
if len(arg_str) > max_debug_str_len:
arg_str += f" (Argument list truncated at {max_debug_str_len}/{len(arg_str)} characters)"
errors.report(f"{message}\n{arg_str}", exc_info=True)
shared.state.job = ""
shared.state.job_count = 0
if extra_outputs_array is None:
extra_outputs_array = [None, '']
error_message = f'{type(e).__name__}: {e}'
res = extra_outputs_array + [f"<div class='error'>{html.escape(error_message)}</div>"]
shared.state.skipped = False
shared.state.interrupted = False
shared.state.job_count = 0
if not add_stats:
return tuple(res)
elapsed = time.perf_counter() - t
elapsed_m = int(elapsed // 60)
elapsed_s = elapsed % 60
elapsed_text = f"{elapsed_s:.2f}s"
if elapsed_m > 0:
elapsed_text = f"{elapsed_m}m "+elapsed_text
if run_memmon:
mem_stats = {k: -(v//-(1024*1024)) for k, v in shared.mem_mon.stop().items()}
active_peak = mem_stats['active_peak']
reserved_peak = mem_stats['reserved_peak']
sys_peak = mem_stats['system_peak']
sys_total = mem_stats['total']
sys_pct = round(sys_peak/max(sys_total, 1) * 100, 2)
vram_html = f"<p class='vram'>Torch active/reserved: {active_peak}/{reserved_peak} MiB, <wbr>Sys VRAM: {sys_peak}/{sys_total} MiB ({sys_pct}%)</p>"
else:
vram_html = ''
# last item is always HTML
res[-1] += f"<div class='performance'><p class='time'>Time taken: <wbr>{elapsed_text}</p>{vram_html}</div>"
return tuple(res)
return f
可以从函数名看出来,这个部分也是为了包裹gradio的请求。
此部分代码主要包裹内容为参数,为了将一些性能信息显示到html页面上

可以看到,此部分的包裹信息,就是在webUI使用时,生成图像的下方所包含的参数信息。
核心功能
txt2img
两个包裹函数看完了,而功能的核心实现为包裹函数内传入的参数,即modules.txt2img
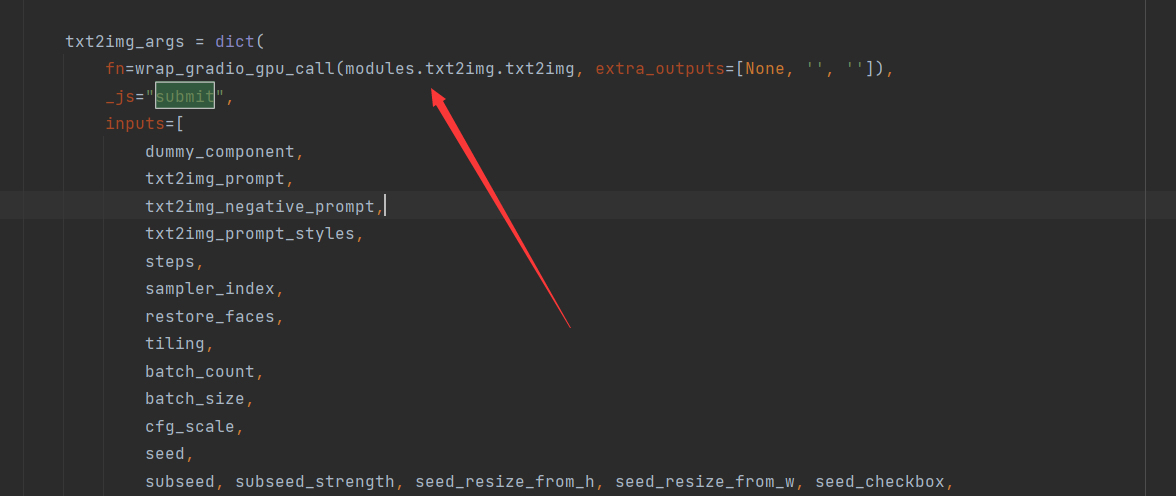
接下来看txt2img
# \modules\txt2img.py
def txt2img(id_task: str, prompt: str, negative_prompt: str, prompt_styles, steps: int, sampler_index: int, restore_faces: bool, tiling: bool, n_iter: int, batch_size: int, cfg_scale: float, seed: int, subseed: int, subseed_strength: float, seed_resize_from_h: int, seed_resize_from_w: int, seed_enable_extras: bool, height: int, width: int, enable_hr: bool, denoising_strength: float, hr_scale: float, hr_upscaler: str, hr_second_pass_steps: int, hr_resize_x: int, hr_resize_y: int, hr_sampler_index: int, hr_prompt: str, hr_negative_prompt, override_settings_texts, *args):
override_settings = create_override_settings_dict(override_settings_texts)
p = processing.StableDiffusionProcessingTxt2Img(
sd_model=shared.sd_model,
outpath_samples=opts.outdir_samples or opts.outdir_txt2img_samples,
outpath_grids=opts.outdir_grids or opts.outdir_txt2img_grids,
prompt=prompt,
styles=prompt_styles,
negative_prompt=negative_prompt,
seed=seed,
subseed=subseed,
subseed_strength=subseed_strength,
seed_resize_from_h=seed_resize_from_h,
seed_resize_from_w=seed_resize_from_w,
seed_enable_extras=seed_enable_extras,
sampler_name=sd_samplers.samplers[sampler_index].name,
batch_size=batch_size,
n_iter=n_iter,
steps=steps,
cfg_scale=cfg_scale,
width=width,
height=height,
restore_faces=restore_faces,
tiling=tiling,
enable_hr=enable_hr,
denoising_strength=denoising_strength if enable_hr else None,
hr_scale=hr_scale,
hr_upscaler=hr_upscaler,
hr_second_pass_steps=hr_second_pass_steps,
hr_resize_x=hr_resize_x,
hr_resize_y=hr_resize_y,
hr_sampler_name=sd_samplers.samplers_for_img2img[hr_sampler_index - 1].name if hr_sampler_index != 0 else None,
hr_prompt=hr_prompt,
hr_negative_prompt=hr_negative_prompt,
override_settings=override_settings,
)
p.scripts = modules.scripts.scripts_txt2img
p.script_args = args
if cmd_opts.enable_console_prompts:
print(f"\ntxt2img: {prompt}", file=shared.progress_print_out)
processed = modules.scripts.scripts_txt2img.run(p, *args)
if processed is None:
processed = processing.process_images(p)
p.close()
shared.total_tqdm.clear()
generation_info_js = processed.js()
if opts.samples_log_stdout:
print(generation_info_js)
if opts.do_not_show_images:
processed.images = []
return processed.images, generation_info_js, plaintext_to_html(processed.info), plaintext_to_html(processed.comments)
可以看到,依次调用了如下的方法:
-
重写的设置(略)
-
StableDiffusionProcessingTxt2Img方法构造的对象p
-
modules.scripts.scripts_txt2img.run方法,利用对象p和参数args生成了结果processed
- 若processed在调用后为空,则调用processing.process_images(p)
-
在有了结果之后,将内容写入html(略)
StableDiffusionProcessingTxt2Img
我们可以在modules/processing.py里找到
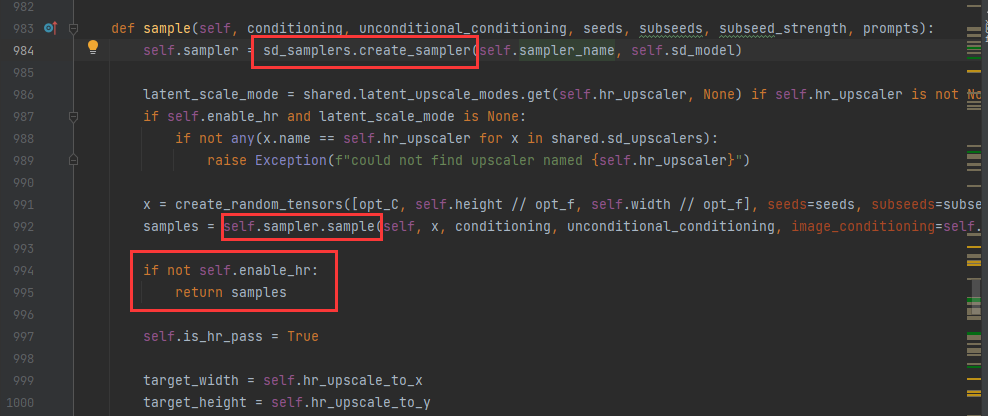
sd_samplers.create_sampler创建了一个采样器对象并且赋值给sampler属性- 接下来使用了
shared.latent_upscale_modes字典根据self.hr_upscaler的值获取对应的缩放模式。 x=create_random_tensors(...)生成一个随机噪音- 之后判断是否进行高清修复
enable_hr,如果没有则直接返回采样器
注意,这个sample方法,只是定义了一个采样器,但是还未执行
采样器
create_sampler
# modules/samplers.py
def create_sampler(name, model):
config = find_sampler_config(name)
assert config is not None, f'bad sampler name: {name}'
sampler = config.constructor(model)
sampler.config = config
return sampler
可以看到,采样器的生成做了一下几个事情
-
加载配置
-
def find_sampler_config(name): if name is not None: config = all_samplers_map.get(name, None) else: config = all_samplers[0] return config -
这里就是一个在一个以name作为键值的map里查找
-
map的定义如下:
-
all_samplers = [ *sd_samplers_kdiffusion.samplers_data_k_diffusion, *sd_samplers_compvis.samplers_data_compvis, ]可以发现,采样器来源于开源项目 K_Diffusion里的采样器数据和Compvis小组自己的采样器数据
-
-
调用
config.constructor来加载模型
config.constructor
我们采取调试的方法,选择Euler a作为sampler
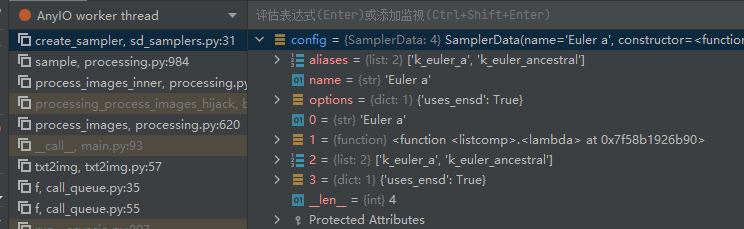
在调试的时候发现遇到了阻碍:
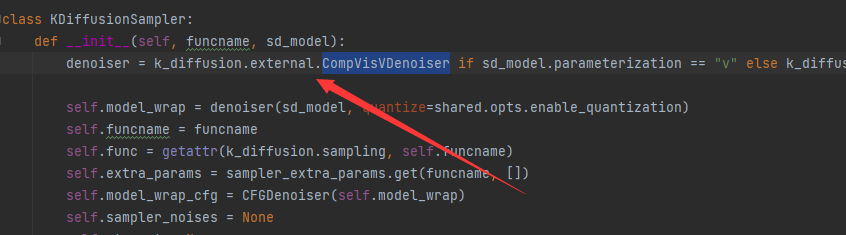
想想,原因应该是在于,k_diffusion是作为外部库的,具体的位置在哪呢?突然想到了在我的第一篇文章内的webui-macos-env的阅读,好像见过类似的库的导入。但我们作为windows启动,那么答案显而易见了,就是之前刻意跳过的launch_utils.py里的内容。
全局搜索k-diffusion.git,最终找到
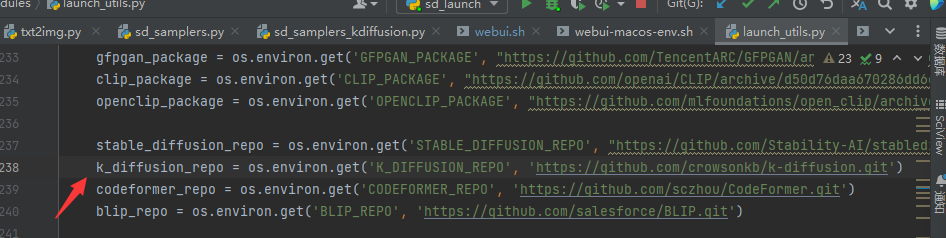
但是!这种外部库十分不方便,尤其是不便于索引到对应的位置并进行调试。
对此尝试了一种新的解决方法,篇幅原因,放到下节再说。
- Stable-Diffusion-webUI Diffusion 按钮 代码 Stablestable-diffusion-webui diffusion按钮 代码 stable-diffusion-webui仓库diffusion代码 stable-diffusion-webui diffusion代码stable stable-diffusion-webui stable-diffusion-webui diffusion stable webui stable-diffusion-webui diffusion ubuntu stable webui stable-diffusion-webui diffusion sd-webui stable-diffusion-webui diffusion过程 环境 画库 圣手stable-diffusion-webui人工智能 stable-diffusion