为什么我的贷款申请过不了,为什么银行不给我提额,为什么同样逾期十天,催收就给我紧急联系人打电话,为什么我的芝麻信用分是733,
银行或者金融公司是怎样对用户的信用进行评级的,下面我来简单介绍一下评分卡,通常来说,评分卡根据用户阶段不同分为以下三种;
A卡(Application Scorecard):A卡是指申请评分卡,也称为行为评分卡(Behavior Scorecard)。它用于对借款人在申请贷款时的信用风险进行评估。A卡根据个人信息、收入、债务以及其他与信用相关的指标来预测借款人的违约概率。这种评分卡通常用于决定是否批准贷款申请。
B卡(Behavior Scorecard):B卡是指行为评分卡,也称为账户评分卡(Account Scorecard)。B卡用于监测和评估借款人在还款期间的行为表现。它考虑了借款人的还款历史、逾期情况、使用信用额度的方式等因素,以确定他们在当前贷款上的信用风险水平。B卡可以帮助金融机构更好地了解借款人的还款能力和还款意愿。
C卡(Collections Scorecard):C卡是指催收评分卡,用于评估借款人处于逾期状态或无法按时偿还贷款时的违约风险。C卡考虑了逾期情况、催收历史以及与还款能力相关的因素,以确定借款人在催收阶段的信用风险水平。这种评分卡可以帮助金融机构制定更有效的催收策略,并决定是否采取法律或其他手段来追回欠款
那么评分卡是怎么构建的评分卡呢,大部分金融机构基于模型可解释性的以及稳定性的要求,采用的是逻辑回归算法,部分公司可能采用xgboot,lightgbm等树模型算法,以逻辑回归为例子评分卡的构建通常分为以下几个步骤;
1、Y标确认
用户风险从用户借款目的来分可分为欺诈风险与信用风险,信用风险又可根据时间分为短期信用风险,中期信用风险,长期信用风险,
不同风险类型采用的建模Y标与用户观察期不一致。在策略眼里,评分卡只是工具而已,
假设在申请授信前用户就没还款意愿的定义为欺诈风险,机构认为用户通常会在第一期到期还款日逾期,很多机构会用首借首逾来量化欺诈风险
而信用风险要怎么量化与划分呢,以下几个概念需要了解一下:
Vintage:Vintage是指特定时间段内发放的贷款组合。通常以月份作为时间单位,可以将贷款根据其发放的时间划分为不同的vintage组。例如,2019年1月发放的所有贷款构成一个vintage组,2019年2月发放的所有贷款构成另一个vintage组,依此类推。
迁移率(Migration Rate):迁移率是指贷款或债务在不同状态之间转移的比例或概率。在信贷中,迁移率可用于描述贷款在不同逾期阶段之间的转移情况。例如,一个30天逾期的贷款可能会迁移到60天逾期的状态,迁移率即表示这种转移的概率或比例。
滚动率(Roll Rate):滚动率是指在特定时间段内,从一个状态(如逾期状态)滚动到另一个状态(如更严重的逾期状态)的比例或概率。滚动率用于衡量贷款或债务在逾期过程中向更高风险状态的转移情况。
入催率(Delinquency Rate):入催率是指处于逾期状态的贷款数量占总贷款组合的比例。一般来说,逾期状态是根据贷款的还款违约天数来定义的,例如,30天逾期、60天逾期等。入催率可以帮助评估贷款组合中逾期情况的严重程度。
首逾率(First Payment Default Rate):首逾率是指在特定时间段内,首次付款未能按时支付的贷款数量占总贷款组合的比例。首逾率通常用于衡量借款人最初偿还债务的能力和风险水平,因为首次付款未能按时支付可能预示着后续还款困难的可能性。
通常信贷机构需要观察用户风险的迁移率与滚动率,来选取一个合适的观察期,同时也要根据自身产品和业务的特性确立Y标
2、入模用户筛选(GBIE)
选取合适的Y标之后,要选取合适的入模用户进行建模分析,是不是所有用户都应该入模呢,假如Y标是指用户进入M1,逾期三十天以上的用户为坏用户,那么某个用户因为还款日设置为发薪日,
但是无良公司老师推迟几天发工资,导致该用户老是会逾期个三五天,三五天后又立马还款了,他算好用户还是坏用户呢?欺诈用户是否要纳入考虑呢?通常金融机构会定义以下四类用户标签;
G (Good):代表好客户或良好的借款人。这些客户按时还款并表现良好。
B (Bad):代表坏客户或风险较高的借款人。这些客户可能违约、逾期或无法按时偿还债务。
I (Indeterminacy):代表不确定客户。这些客户可能由于数据缺失、特殊情况或其他原因而无法明确归类为好客户或坏客户。
E (Exclusion):代表排除客户。这些客户被在建模或分析过程中排除在外,可能是因为特定规则、策略或业务需求等原因。
通常只会将GB两类用户用于逻辑回归建模,有时候E类用户或者边界用户的加入可能会使模型效果更差,鲁棒性更差
3、入模特征初步筛选
确定Y标以及入模用户之后,我们就需要去获取用户的数据特征了,这里涉及到的数据就比较多了,征信报告数据,用户基本数据,历史借贷数据,多头数据,运营商数据,关系图谱数据,以及各种三方数据,特征既有原始特征,也有衍生特征,衍生特征与原始特征相关性可能会比较强,如果都入模会带来严重的共线性问题,筛选时主要有以下几个要点:
a、特征本身不存在任何数据穿越的信息,即所有入模特征的时间范围都只是表现期之前的统计口径
b、剔除缺失值过多的特征,缺失过多难以保证模型的稳定性
c、筛选方法有很多,基于信息增益,基于IV值,基于KS检验,或者用树模型按照特征重要性筛选等等
d、初步筛选的特征不一定都要入模,还得满足PSI稳定性、WOE单调性,低共线性等要求
4、入模特征分箱,WOE编码
特征分箱前首先要了解三个基本概念,分别是WOE,IV和PSI;
a、WOE(Weight of Evidence)是一种用于评估特征变量与目标变量之间关联性的指标,常用于信用评分模型和风险建模中WOE = ln((good_pct)/(bad_pct))
b、IV(Information Value)是一种常用于评估特征变量预测能力的指标,通常用于评估分类模型中的变量重要性。IV = Σ (good_pct - bad_pct) * WOE其中good_pct 是某个分组中目标变量取好值(例如“违约”)的比例;bad_pct 是某个分组中目标变量取坏值(例如“非违约”)的比例,通常认为iv<0.02的变量没有预测能力
c、PSI(Population Stability Index)是一种用于衡量两个群体之间稳定性差异的指标,常用于监测模型在不同时间段或不同样本群体上的表现是否保持稳定。计算 PSI 的公式如下:
PSI = Σ ((Actual_pct - Expected_pct) * ln(Actual_pct / Expected_pct)),其中,Actual_pct 是当前群体中某个分组的实际占比;Expected_pct 是基准群体中相应分组的期望占比,psi越接近0说明群体分布越稳定,通常需要psi<0.1
了解基本概念后分箱操作需要注意以下几点;
a、逻辑回归终究是线性模型,分箱的目的是让模型加入非线性,提升模型性能的同时保证特征的稳定性与解释性
b、没有完美的分箱方法,分箱需要追求最大信息量IV,最高稳定性PSI,WOE单调性,每个区间的占比数不能过低(经验值5%)
c、连续特征需要分箱,总的来说有分裂法或者合并法,分裂法例如基于信息熵增益,GINI系数等,分裂法例如基于卡方检验合箱等
d、离散特征若类别数过多可能需要合箱,否则特征稳定性会较差,缺失值可自成一类,PSI通常需要小于0.01,IV通常需要大于0.02
woe 分析demo如下:

5、模型建立与性能测试
建立模型,逻辑回归模型比较简单,建模过程就是寻找每个特征woe编码后的系数大小的过程,评估模型通常需要考虑KS,AUC,GINI,LIF四个指标,
其中GINI和AUC是衡量模型区分好怀用户的平均能力,其中KS=MAX(|FPR-TPR|),GINI=2AUC-1,而KS量化的是好快用户差异最大的值,lift量化好坏分布差异的趋势,如下图所示,lift最大的时为模型预测概率值在第一个十分位时,然后慢慢递减,而ks是在第三个十分位时

#画ROC曲线
roc_test=metrics.roc_auc_score(y_test,y_pro_test)
roc_train=metrics.roc_auc_score(y_train,y_pro_train)
fig1 = plt.figure('fig1')
fpr, tpr, thresholds = metrics.roc_curve(y_test,y_pro_test,pos_label=1)
plt.plot(fpr,tpr,linewidth=2,color="red",label = "ROC curve of %s (test AUC = %.4f)" % ('GBM',roc_test))
plt.title("ROC curve of GBM")
fpr, tpr, thresholds = metrics.roc_curve(y_train,y_pro_train,pos_label=1)
plt.plot(fpr,tpr,linewidth=2,color="blue",label = "ROC curve of %s (train AUC = %.4f)" % ('GBM',roc_train))
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.legend()
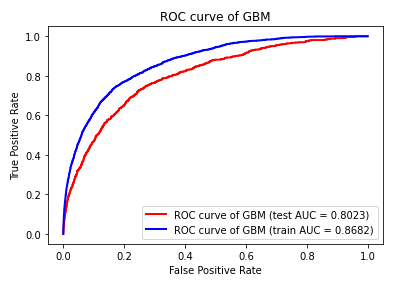
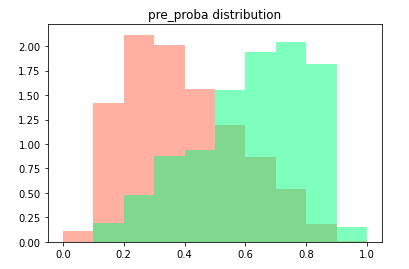
fig5= plt.figure('fig5')
pro_hist=pd.DataFrame()
pro_hist['proba']=y_pro_test
pro_hist['y']=list(y_test)
plt.hist(pro_hist[pro_hist['y']==0]['proba'],bins=[i/10 for i in range(11)],color='tomato',alpha=0.5, density=True, stacked=True )
plt.hist(pro_hist[pro_hist['y']==1]['proba'],bins=[i/10 for i in range(11)],color='springgreen',alpha=0.5, density=True, stacked=True)
plt.title('pre_proba distribution')
plt.show()
#ks曲线
fig2 = plt.figure('fig2')
fpr, tpr, thresholds= metrics.roc_curve(y_test,y_pro_test)
ks_value = max(abs(fpr-tpr))
# 画图,画出曲线
plt.plot(1-thresholds,fpr, label='bad',linewidth=2,color="blue")
plt.plot(1-thresholds,tpr, label='good',linewidth=2,color="red")
plt.plot(1-thresholds,abs(fpr-tpr), label='diff')
# 标记ks
x = np.argwhere(abs(fpr-tpr) == ks_value)[0, 0]
x=(1-thresholds)[x]
#plt.plot( (x, x),(0+ks_value, ks_value+ks_value), label='ks - {:.2f}'.format(ks_value), color='g', marker='o', markerfacecolor='g', markersize=5)
#plt.scatter((x, x), (0, ks_value), color='r')
plt.title("KS curve of Model,"+"KS value="+str(round(ks_value,3))+" when thr="+str(round(x,3)))
plt.xlim(0,1)
plt.legend()
plt.show()

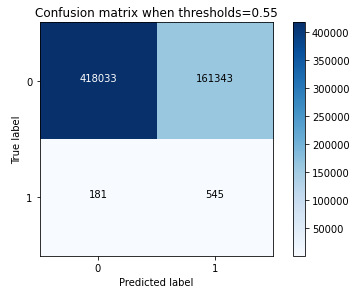
#混淆矩阵
y_pred=np.where(y_pro_test>0.5,1,0)
import itertools
def plot_confusion_matrix(cm, classes,title='Confusion matrix when thresholds=0.5',cmap=plt.cm.Blues):
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes)
plt.yticks(tick_marks, classes)
fmt = 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
cnf_matrix = metrics.confusion_matrix(y_test,y_pred)
np.set_printoptions(precision=2)
# Plot non-normalized confusion matrix
plt.figure()
plot_confusion_matrix(cnf_matrix, classes=[0,1],title='Confusion matrix when thresholds=0.55')
6、模型部署与监控
a、评分卡需要将用户逾期概率转化为具体评分,评分函数如下:
def calculate_score(base_score, odds, pdo, odds_ref=1): # 计算比率对数(log(odds/odds_ref)) log_odds = math.log(odds / odds_ref) # 根据PDO值计算每个评分等级的分数增量 score_increment = pdo / math.log(2) # 计算最终评分 score = base_score + log_odds * score_increment return score
#逾期概率 = 0.9时,odds = 0.9 / (1 - 0.9) = 9 得分536.6
#逾期概率 = 0.8时,odds = 0.8 / (1 - 0.8) = 4 得分560
#逾期概率 = 0.5时,odds = 0.5 / (1 - 0.5) = 1 得分600
#逾期概率 = 0.2时,odds = 0.2 / (1 - 0.2) = 0.25 得分640
#逾期概率 = 0.01时,odds = 0.01 / (1 - 0.01) = 0.01 得分732.9
b、逻辑回归的部署比较简单,可以简单用sql就可以部署,只需将变量不同分值所在woe值取出乘以对应系数就可,可用多个case when就可实现
监控主要监控两个部分,一是模型变量psi,而是入模变量的psi,监控不同时间段,不同业务线进来的用户分布是否和建模样本的分布一致,若评分前策略如反欺诈规则发生变化,或者由于市场行情,政策,用户群体发生变化,模型性能可能会大受影响,需及时发出告警