近些年来人脸三维重建的发展主要围绕数据表示来进行,从一开始的显式表示到探索线性参数化表示,到后来非线形参数化表示和神经场表示,表示能力越来越强。此外,还有些方法结合了参数化模型表示和GAN等生成模型,以优化参数化模型对细节的缺失。
从0开始的三维人脸重建入门 (二)
FLAME (Learning a model of facial shape and expression from 4D scans)
3DDFA之后,研究界提出了更大体量的人脸模型FLAME,之后的工作往往基于FLAME。
相比于BFM,提供了更大的数据集构建的模型,主要区别如下:
- FLAME对一些可旋转部位进行的建模,称之为pose,而BFM未对此进行建模,而是对整个人脸进行旋转表示。
- FLAME是对整个人头进行的建模,BFM主要针对人脸。
- FLAME使用的数据量更大,因此模型的精度要更高,可以理解为上限更高。
- FLAME缺乏纹理,BFM有纹理数据。
表情和shape前面已经探讨过,pose这里是采用了SMPL: A Skinned Multi-Person Linear Model这篇
SMPL (SMPL: A Skinned Multi-Person Linear Model)
SMPL是一篇人体重建的模型,影响了人脸重建很多。
文章的方法进行建模和训练,在SMPL中是这样表示的:
由于SMPL是人体模型,因此可旋转的点定义了23个+1个全局点,其清楚地给出了旋转的公式:
其中\(t_i\)就是旋转前后的一个顶点,在世界坐标系中进行表示,\(w\)则是影响程度,下面的累乘\((G_k(\vec{\theta}, \mathbf{J}))\)是前向运动学公式,即给定每个子节点相对父节点的旋转和在父节点下的坐标,得到任意节点相对根节点坐标系的位置(变换矩阵),第二个公式表达的意思是先将这一点的世界坐标转换到第k个joint的坐标系下,即原始角度表示下的逆矩阵,然后利用前向运动学公式求出参数\(\theta\)时的位置。
这样的pose建模虽然简单但是和shape、expression的建模并没有一致性(基的线性和),于是对pose的旋转进行一致性建模:
这样就建模成了线性和的形式。可以看到\(\theta\)在两个地方出现,后者更多的是描述不同人的“体态”的pose,所以出现在blend pose里,这里是认为pose本身也应该作为组成人的一个基,就好像有些人本身就驼背一样,这应该属于这类人的特性;而前者才描述运动pose,此外,由于shape的不同会导致joint的位置不同,而在旋转的时候是需要joint的坐标的,因此\(J\)的作用是得到joint的坐标。
值得注意的是,shape基是在pose normalize之后通过PCA得到的,而pose的基则是利用multi-pose的dataset训练得到,为啥可以训练呢,因为基的坐标咱可以人为定义,相当于数据集中有标注,具体定义为和rest pose的残差:
其中系数为\(\theta\)下轴角表示的变换阵与rest pose的差,\(P_n\)就是其对应的基,其中\(w\)和\(P_n\)都是训练来的,训练是拿有标注的3D数据集进行registration学习这些参数,\(P_n\)加了正则项惩罚,这块其实等价于autoencoder,以得到基。
关于code实现中
G = G - self.pack(
np.matmul(
G,
np.hstack([self.J, np.zeros([24, 1])]).reshape([24, 4, 1])
)
)
看到有些人问,想了下,应该是一个坐标系的转换,转到joint系下再做变换,由于根节点是相对于世界系的变换,所以最终运动链的变换会直接变为世界系下的坐标,所以并不需要转回去。
\(w\)控制的是joint对某个顶点的影响程度,也是通过训练得到的,那如何保证哪些顶点受哪些joint影响呢?
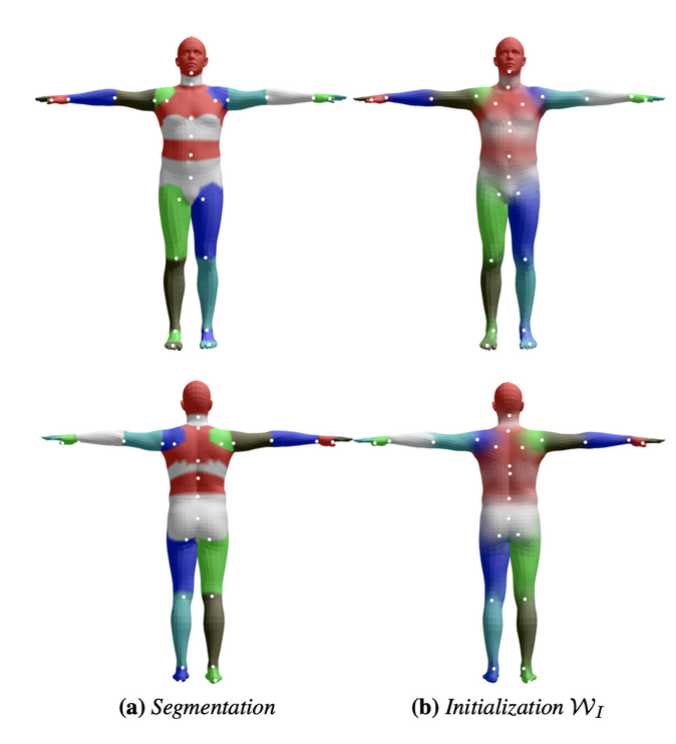
先通过segmentation分区域,然后让\(w\)去拟合这个结果。
至此SMPL中的pose搞清楚了,再看看人脸中的pose。
同样的,定义了4个joint
基于对SMPL的理解,FLAME的pose也是一样的建模方式加上个expression,只是关节链没有在论文中给出,下载数据集之后看parents是:
[-1 0 1 1 1]

其中0为根节点。
DECA (Learning an Animatable Detailed 3D Face Model from In-The-Wild Images)
在FLAME和之前可微分渲染的基础上,DECA提升了带纹理的FLAME的重建细节。整个结构由coarse reconstruction和detail reconstruction组成,其简单结构如下:
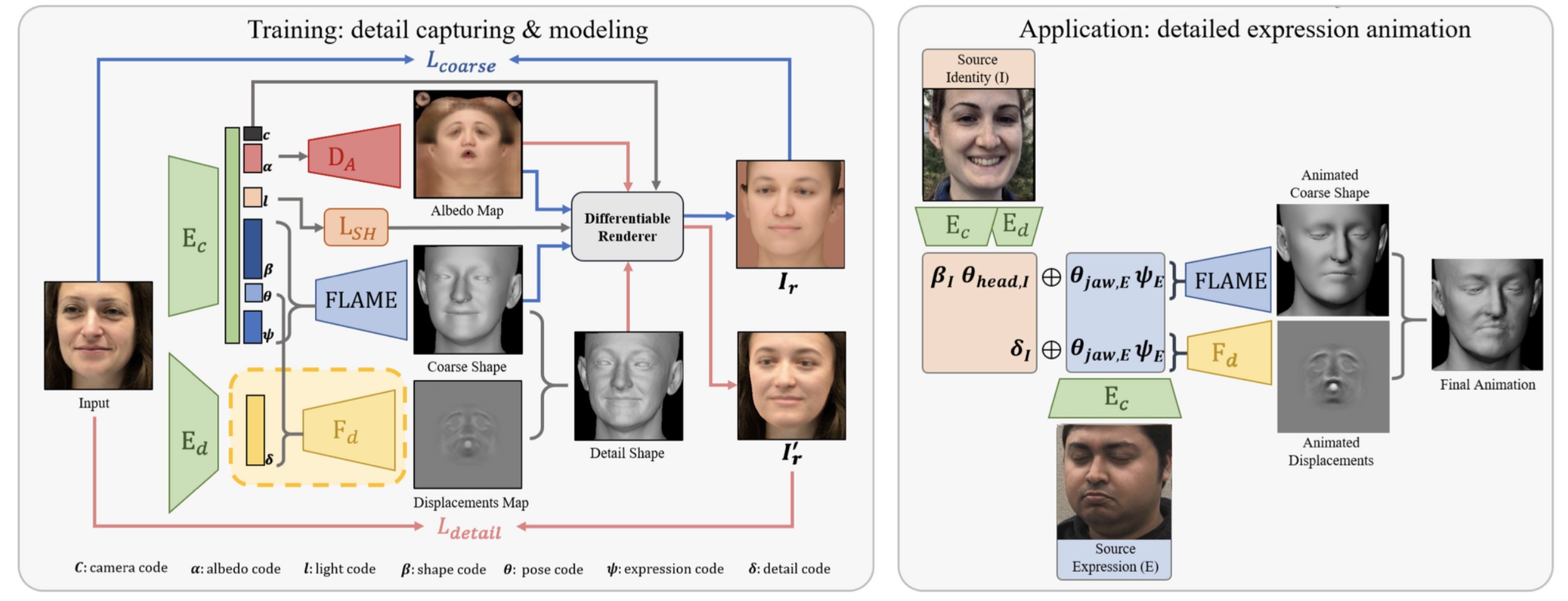
其中coarse reconstruction就和之前一样,预测模型参数和渲染参数,粗略地重建人脸,之所以是粗略的重建,是因为作者认为FLAME的分辨率决定了该模型对细节重建的上限,即细节不够好,因此本文的一大贡献就是外套一个细节增强分支去增强细节。除此之外,如果能够提升mesh的分辨率或者确保FLAME的数据有充分的中频细节,也是可以提升FLAME的细节上限的,但显然从用户角度,再训练个增强模型要更为可操作。
从左图中可以看出,\(D_A\)预测的其实是环境贴图,对应的是渲染时的反射率,\(F_d\)预测了位移贴图,但从代码看好像是法线贴图,并没有直接改变顶点的位置。
相比于法线贴图,既改变法向量,也改变节点的位置,在mesh分辨率比极高的时候效果比较好。
之后将贴图后的人脸渲染计算相应损失。
整个架构和前面可微渲染的架构变化不大,相对来说很好理解。
Nonlinear (Nonlinear 3D Face Morphable Model)
这是人脸重建的另一个分支,之前我们的是通过线性基来表示数据,通过对基的线性组合实现人脸表示,但人脸可能并非能够完全显性表示的,其表示能力有限。本文提出用非线形方式表示人脸,实现了更佳的重建效果。由于文章发表于2017年,因此是以3DMM模型实验的。
文章想表达的非线形是用神经网络来实现,即对于线形模型而言,其相当于以基为全连阶层参数,以系数作为输入的全连阶层;因此,如果要实现非线形模型,就要把基变成一个神经网络。

从上图就很容易看出来了,\(E\)编码输入图像到基的系数,基就是\(D_S\)和\(D_T\)的权重,那和3DMM有啥关系呢?还是要用到3DMM的平均顶点的嘛,网络预测的毕竟是offset。
对于纹理的表示,文章是采用了uv图,而不是3dmm的mesh表示。
PRNet (Joint 3D Face Reconstruction and Dense Alignment with Position Map Regression Network)
基于参数化模型的方式是主流,但也有像本文这样直接考虑根据2D图像去预测3D模型的方法。由于直接预测3D位置是很难的,主要在于这样的1D vector表示破坏了邻近数据的关系,不像2D图像那样,周围的点往往具有相似的像素值。因此为了简化任务难度,文章开创性地用UV图来存储位置,使用神经网络预测UV位置图。
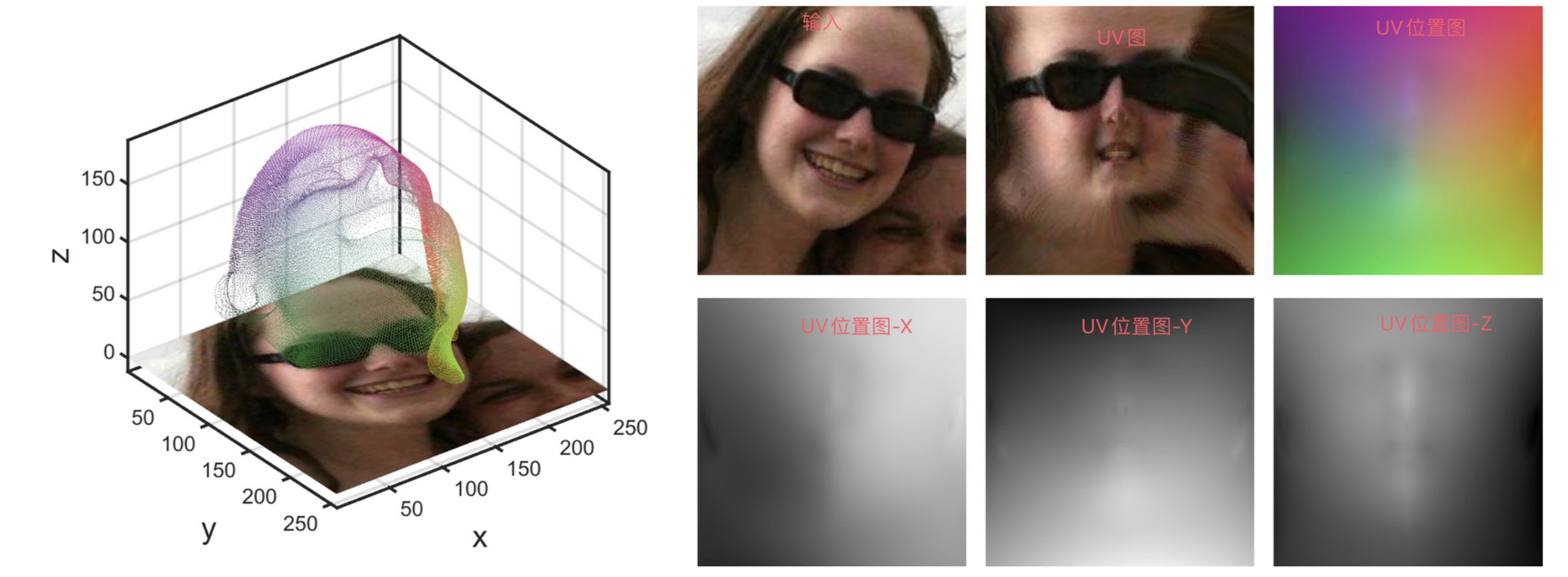
UV位置图就是把三个通道分别用来存储对应点的xyz坐标,而不是原来的rgb颜色,而通过坐标就可以恢复到原来的三维结构。
NeRF (NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis)
文章开创性地把整个场景用神经网络进行编码,也就是说神经网络相当于一个查询器,你给定他一组query:空间中点的位置(x,y,z)和观测方向(\(\theta,\phi\)),位置好理解,方向显然是使用球坐标系表示(还记得三重积分嘛),网络输出该点的颜色和密度,将所有位置都查询一遍,那么整个场景就可以在某个视角下渲染出来。所以,我理解下来,这里神经网络在训练过程中的目的似乎是“过拟合”所有query的结果,过拟合越严重,证明其记忆的越好,渲染效果也越好。按照理解,NeRF对于场景的表示是一种隐式表示,就如同我们描述三维球壳一样,\(X^2+Y^2+Z^2=R^2\),NeRF用神经网络将场景存储了起来。
因此整个神经网络就只做了这么一个简单的建模:
网络结构就是一个简单的MLP。
理解NeRF一方面需要理解上述对神经网络的使用,另一方面主要还是理解体渲染的过程。
体渲染的过程是从相机焦点出发,发射一条光线,光线经过空间中任意一点都会对最终屏幕显示的颜色有影响,可以理解为某个颜色函数在光线路径上的积分,该积分的结果就是最终的像素值。当我们对所有像素各发射一条光线,最终所有像素都被赋值,形成图像。
我们先假设网络训练完成了,那么整个渲染遵循渲染方程:
其中\(C(\mathbf{r})\)是指在某一条光线路径上颜色的平均值,可以理解为最终一个像素的颜色。
\(t_n\)和\(t_f\)是路径位置的上下限,由于直线可以用参数方程表示,所以只需要一个t可以描述直线上任意位置。
\(\sigma(\mathbf{r}(t))\)描述的是在沿着直线r在t位置处的密度,密度只和位置有关,与观测角度无关。
\(\mathbf{c}(\mathbf{r}(t),\mathbf{d})\)表示的是沿着直线r在t位置处的颜色,颜色是与观测角度有关的。
\(T(t)\)是从起始点到t位置的密度积分的exp负指数,显然描述的是密度的累积对颜色的权重,前面密度累积的足够大时,尽管t依然在增加,但\(T\)控制了其权重变小,因此可以描述一种遮挡的效果。
实际渲染时,对光线路径上的点进行采样求和替换积分。
这样一个任务如何优化呢? 即数据从哪来?
NeRF只需要一些RGB图像就可以训练了,其对应的相机内参、外参都来自于COLMAP包的估计。解决了数据问题,还有两个优化上的技巧。
Positional Encoding
文章对输入做了个调整,即对输入做了positional encoding,但从结果看似乎不做也可以,做了的确有提升,所以到这里其实就已经说明了这个方法的可行性了。

对于positional encoding,其主要观点来自于ICML的On the Spectral Bias of Neural Networks,低维到高维映射的神经网络倾向于学习低频的pattern,这样学习到的网络可能对几何和颜色空间中的高频数据缺乏表达。根据论文结论,输入数据先变为高维后再处理往往可以缓解这一问题。文章对输入坐标做了如下编码提升纬度。
Coarse to fine optimization
先粗采样一些位置优化,再针对密度高的位置着重采样优化,以解决训练效率低的问题。