RabbitMQ - 消息中间件
1 消息队列Rabbitmq介绍
1.0 什么是消息队列
消息:指的是两个应用间传递的数据【字符串、对象等等】
消息队列:在消息的传输过程中保存消息的容器,在消息队列中游生产者和消费者两个角色
生产者:生产者只负责发送数据到消息队列
消费者:消费者只负责从消息队列中取出数据处理
1.1 rabbitmq介绍
RabbitMQ是一款使用Erlang语言开发的,实现AMQP(高级消息队列协议)的开源消息中间件。首先要知道一些RabbitMQ的特点,官网可查:
- 可靠性。支持持久化,传输确认,发布确认等保证了MQ的可靠性。
- 灵活的分发消息策略。这应该是RabbitMQ的一大特点。在消息进入MQ前由Exchange(交换机)进行路由消息。分发消息策略有:简单模式、工作队列模式、发布订阅模式、路由模式、通配符模式。
- 支持集群。多台RabbitMQ服务器可以组成一个集群,形成一个逻辑Broker。
- 多种协议。RabbitMQ支持多种消息队列协议,比如 STOMP、MQTT 等等。
- 支持多种语言客户端。RabbitMQ几乎支持所有常用编程语言,包括 Java、.NET、Ruby 等等。
- 可视化管理界面。RabbitMQ提供了一个易用的用户界面,使得用户可以监控和管理消息 Broker。
- 插件机制。RabbitMQ提供了许多插件,可以通过插件进行扩展,也可以编写自己的插件。


# Broker: 消息中间件,AMQP实体
接收和分发消息的应用,RabbitMQ 的服务就是一个Message Broker
# Virtual host: 虚拟主机
出于多租户和安全因素设计的,把AMQP的基本组件划分到一个虚拟的分组中,类似于网络中的namespace概念
当多个不同的用户使用同一个RabbitMQ server提供的服务时,可以划分出多个vhost,每个用户在自己的vhost创建exchange/queue
# Connection: 连接
publisher/consumer和broker之间的TCP连接
断开连接的操作只会在client端进行,Broker不会断开连接,除非出现网络故障或broker服务出现问题
# Channel: 通道
如果每一次访问RabbitMQ都建立一个Connection,在消息量大的时候建立TCP Connection的开销将是巨大的,效率也较低
Channel是在connection内部建立的逻辑连接,如果应用程序支持多线程,通常每个thread创建单独的channel进行通讯,AMQP method包含了channel id帮助客户端和message broker识别channel,所以channel之间是完全隔离的。
Channel作为轻量级的Connection极大减少了操作系统建立TCP connection的开销。
# Exchange: 交换机
message到达broker的第一站,根据分发规则,匹配查询表中的routing key,分发消息到queue中去。
常用的类型有:
'''
1【direct (point-to-point)-点对点模式】点对点模式Message中的routing key如果和Binding中的binding key一致,Direct exchange则将message发到对应的queue中
2【topic (publish-subscribe)-发布-订阅模式】根据routing key,及通配规则,Topic exchange将分发到目标queue中
3【fanout (multicast)-多播模式】每个发到Fanout类型Exchange的message都会分到所有绑定的queue上去。
'''
# Queue: 队列
消息最终被送到这里等待consumer取走
一个message可以被同时拷贝到多个queue中
# Binding: 绑定
exchange和queue之间的虚拟连接,binding中可以包含routing key
Binding信息被保存到exchange中的查询表中,用于message的分发依据
1.2 MQ解决的问题
① 应用解耦:提升系统的可用性,消息队列做缓冲,进程间通信IPC可以用消息队列来做
② 流量削峰:高峰期,生成的数据放到消息队列中慢慢消费
③ 消息分发:【发布-订阅模式】MQ做消息中间件
④ 异步消息:实现异步调用消息
⑤ IPC:进程间通信也可以通过消息队列
-
解耦:假设有系统B、C、D都需要系统A的数据,于是系统A调用三个方法发送数据到B、C、D。这时,系统D不需要了,那就需要在系统A把相关的代码删掉。假设这时有个新的系统E需要数据,这时系统A又要增加调用系统E的代码。为了降低这种强耦合,就可以使用MQ,系统A只需要把数据发送到MQ,其他系统如果需要数据,则从MQ中获取即可。

-
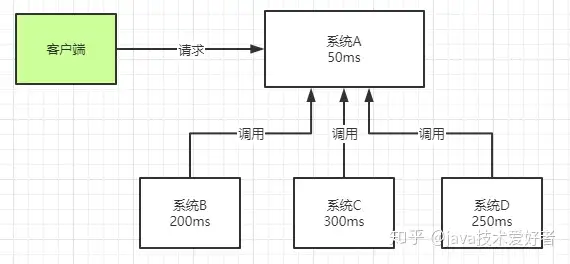
异步:一个客户端请求发送进来,系统A会调用系统B、C、D三个系统,同步请求的话,响应时间就是系统A、B、C、D的总和,也就是800ms。如果使用MQ,系统A发送数据到MQ,然后就可以返回响应给客户端,不需要再等待系统B、C、D的响应,可以大大地提高性能。对于一些非必要的业务,比如发送短信,发送邮件等等,就可以采用MQ。
-
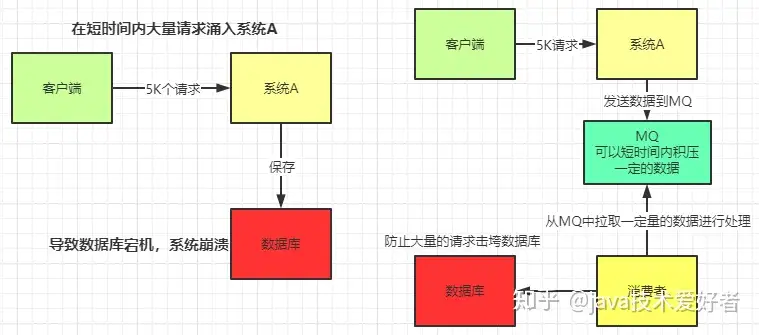
削峰:这其实是MQ一个很重要的应用。假设系统A在某一段时间请求数暴增,有5000个请求发送过来,系统A这时就会发送5000条SQL进入MySQL进行执行,MySQL对于如此庞大的请求当然处理不过来,MySQL就会崩溃,导致系统瘫痪。如果使用MQ,系统A不再是直接发送SQL到数据库,而是把数据发送到MQ,MQ短时间积压数据是可以接受的,然后由消费者每次拉取2000条进行处理,防止在请求峰值时期大量的请求直接发送到MySQL导致系统崩溃。
1.3 常见的消息队列及比较

kafka:吞吐量高,十万级
rabbitmq:消息准确性高,吞吐量 万级
2 RabbitMQ介绍安装
2.1 下载
官网:https://www.rabbitmq.com/
下载地址:https://www.rabbitmq.com/download.html
因为Rabbitmq是基于erlang语言开发,无论什么平台,都需要先安装erlang
注意rabbitmq和errlang的版本对应关系
https://www.rabbitmq.com/which-erlang.html
2.2 安装
(1)window安装
官网安装,下一步下一步即可
(2)linux下安装rabbitmq
以centos为例
# 1 安装上传下载软件
yum install -y lrzsz
# 2 把centos7文件夹下两个软件拖入
# 3 安装erlang
rpm -ivh esl-erlang_24.0-1_centos_7_amd64.rpm
# 如果报错误
错误:依赖检测失败:
libodbc.so.2()(64bit)
# 安装unixODBC
yum -y install unixODBC
# 查看安装的erlang
rpm -qa | grep erlang
# 卸载
rpm -e esl-erlang-23.3.1-1.x86_64
# 4 安装rabbitmq-server
rpm -ivh rabbitmq-server-3.8.16-1.el7.noarch.rpm
# 如果报错
错误:依赖检测失败:
socat 被 rabbitmq-server-3.8.16-1.el7.noarch 需要
# 安装socat
yum install socat
(3)docker安装
# 安装好Docker,执行下面命令
docker pull rabbitmq:management
docker run -di --name Myrabbitmq -e RABBITMQ_DEFAULT_USER=admin -e RABBITMQ_DEFAULT_PASS=admin -p 15672:15672 -p 5672:5672 rabbitmq:management
# 浏览器访问:
http://10.0.0.103:15672
# 输入用户名:guest 密码:guest ,进入到管理控制台
2.3 配置web管理插件
rabbitmq自带一个 web图形化界面,可以可视化使用
(1)windows配置
# 1 安装web管理插件
rabbitmq-service.bat enable rabbitmq_management
# 2 启动服务
rabbitmq-server.bat
# 3 访问web管理页面
http://127.0.0.1:15672/
# 4 使用用户登录
用户名:guest
密码:guest


(2)centos7配置
# 1 安装web管理插件
rabbitmq-plugins enable rabbitmq_management
# 2 新建配置文件(https://github.com/rabbitmq/rabbitmq-server/blob/master/deps/rabbit/docs/rabbitmq.conf.example)
cd /etc/rabbitmq
vi rabbitmq.conf
# 复制官方提供的配置文件
## 注意:把下面注释解开,才能从非本地访问web
## Uncomment the following line if you want to allow access to the guest user from anywhere on the network.
loopback_users.guest = false
# 3 启动RabbitMQ的服务
systemctl start rabbitmq-server
systemctl restart rabbitmq-server
systemctl stop rabbitmq-server
# 4 登录到web管理
http://10.0.0.100:15672/
# 5 用户名密码
用户名:guest
密码:guest
# 6 查看命令帮助
rabbitmqctl help
2.4 用户设置
rabbitmqctl add_user lqz 123
# 设置用户为administrator角色
rabbitmqctl set_user_tags lqz administrator
# 设置权限
rabbitmqctl set_permissions -p "/" root ".*" ".*" ".*"
# 然后重启rabbiMQ服务
systemctl reatart rabbitmq-server
# 然后可以使用刚才的用户远程连接rabbitmq server了。
3 基于queue实现 生产者-消费者 模型
import Queue
import threading
message = Queue.Queue(10)
def producer(i):
while True:
message.put(i)
def consumer(i):
while True:
msg = message.get()
for i in range(12):
t = threading.Thread(target=producer, args=(i,))
t.start()
for i in range(10):
t = threading.Thread(target=consumer, args=(i,))
t.start()
4 基本使用(生产者消费者模型)
对于RabbitMQ来说,生产和消费不再针对内存里的一个Queue对象,而是某台服务器上的RabbitMQ Server实现的消息队列
安装python客户端
pip3 install pika
4.1 生产者
import pika
# 无密码
# connection = pika.BlockingConnection(pika.ConnectionParameters('127.0.0.1'))
# 有密码
credentials = pika.PlainCredentials("admin","admin")
connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials))
channel = connection.channel()
# 声明一个队列(创建一个队列)
channel.queue_declare(queue='lqz')
channel.basic_publish(exchange='',
routing_key='lqz', # 消息队列名称
body='hello world')
connection.close()
4.2 消费者
import pika
credentials = pika.PlainCredentials("admin","admin")
connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials))
channel = connection.channel()
# 声明一个队列(创建一个队列)
channel.queue_declare(queue='lqz')
def callback(ch, method, properties, body):
print("消费者接受到了任务: %r" % body)
channel.basic_consume(queue='lqz',on_message_callback=callback,auto_ack=True)
channel.start_consuming()
5 消息安全 - ack确认机制
5.1 生产者
import pika
# 无密码
# connection = pika.BlockingConnection(pika.ConnectionParameters('127.0.0.1'))
# 有密码
credentials = pika.PlainCredentials("admin","admin")
connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials))
channel = connection.channel()
# 声明一个队列(创建一个队列)
channel.queue_declare(queue='lqz')
channel.basic_publish(exchange='',
routing_key='lqz', # 消息队列名称
body='hello world')
connection.close()
5.2 消费者
import pika
credentials = pika.PlainCredentials("admin","admin")
connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials))
channel = connection.channel()
# 声明一个队列(创建一个队列)
channel.queue_declare(queue='lqz')
def callback(ch, method, properties, body):
print("消费者接受到了任务: %r" % body)
# 通知服务端,消息取走了,如果auto_ack=False,不加下面,消息会一直存在
# ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_consume(queue='lqz',on_message_callback=callback,auto_ack=False)
channel.start_consuming()
6 消息安全之durable持久化
6.1 生产者
import pika
# 无密码
# connection = pika.BlockingConnection(pika.ConnectionParameters('127.0.0.1'))
# 有密码
credentials = pika.PlainCredentials("admin","admin")
connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials))
channel = connection.channel()
# 声明一个队列(创建一个队列),durable=True支持持久化,队列必须是新的才可以
channel.queue_declare(queue='lqz1',durable=True)
channel.basic_publish(exchange='',
routing_key='lqz1', # 消息队列名称
body='111',
properties=pika.BasicProperties(
delivery_mode=2, # make message persistent,消息也持久化
)
)
connection.close()
6.2 消费者
import pika
credentials = pika.PlainCredentials("admin","admin")
connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials))
channel = connection.channel()
# 声明一个队列(创建一个队列)
channel.queue_declare(queue='lqz1')
def callback(ch, method, properties, body):
print("消费者接受到了任务: %r" % body)
# 通知服务端,消息取走了,如果auto_ack=False,不加下面,消息会一直存在
# ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_consume(queue='lqz1',on_message_callback=callback,auto_ack=False)
channel.start_consuming()
7 闲置消费
正常情况如果有多个消费者,是按照顺序第一个消息给第一个消费者,第二个消息给第二个消费者
但是可能第一个消息的消费者处理消息很耗时,一直没结束,就可以让第二个消费者优先获得闲置的消息
7.1生产者
import pika
# 无密码
# connection = pika.BlockingConnection(pika.ConnectionParameters('127.0.0.1'))
# 有密码
credentials = pika.PlainCredentials("admin","admin")
connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials))
channel = connection.channel()
# 声明一个队列(创建一个队列),durable=True支持持久化,队列必须是新的才可以
channel.queue_declare(queue='lqz123',durable=True)
channel.basic_publish(exchange='',
routing_key='lqz123', # 消息队列名称
body='111',
properties=pika.BasicProperties(
delivery_mode=2, # make message persistent,消息也持久化
)
)
connection.close()
7.2 消费者
import pika
credentials = pika.PlainCredentials("admin","admin")
connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials))
channel = connection.channel()
# 声明一个队列(创建一个队列)
# channel.queue_declare(queue='lqz123')
def callback(ch, method, properties, body):
print("消费者接受到了任务: %r" % body)
# 通知服务端,消息取走了,如果auto_ack=False,不加下面,消息会一直存在
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_qos(prefetch_count=1) #####就只有这一句话 谁闲置谁获取,没必要按照顺序一个一个来
channel.basic_consume(queue='lqz123',on_message_callback=callback,auto_ack=False)
channel.start_consuming()
8 发布订阅(交换机模式:fanout)
不同的队列中 fanout
8.1生产者
import pika
credentials = pika.PlainCredentials("admin","admin")
connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials))
channel = connection.channel()
channel.exchange_declare(exchange='m1',exchange_type='fanout')
channel.basic_publish(exchange='m1',
routing_key='',
body='lqz nb')
connection.close()
8.2 消费者
import pika
credentials = pika.PlainCredentials("admin","admin")
connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials))
channel = connection.channel()
# exchange='m1',exchange(秘书)的名称
# exchange_type='fanout' , 秘书工作方式将消息发送给所有的队列
channel.exchange_declare(exchange='m1',exchange_type='fanout')
# 随机生成一个队列
result = channel.queue_declare(queue='',exclusive=True)
queue_name = result.method.queue
print(queue_name)
# 让exchange和queque进行绑定.
channel.queue_bind(exchange='m1',queue=queue_name)
def callback(ch, method, properties, body):
print("消费者接受到了任务: %r" % body)
channel.basic_consume(queue=queue_name,on_message_callback=callback,auto_ack=True)
channel.start_consuming()
9 发布订阅高级之Routing(按关键字匹配)(交换机模式:topic、direct)
发布订阅(观察者模式)
发布者发了消息,所有观察者都能收到
交换机----》不同的队列中 fanout
direct 指定routing_key
topic 模糊匹配routing_key
9.1 交换机模式:direct - 指定routing_key匹配
- 发布者
import pika
credentials = pika.PlainCredentials("admin","admin")
connection = pika.BlockingConnection(pika.ConnectionParameters('10.0.0.101',credentials=credentials))
channel = connection.channel()
### 声明exchange
channel.exchange_declare(exchange='m1',exchange_type='direct')
channel.basic_publish(exchange='m1',
routing_key='lqz',
body='asdfasdfasdfasdfasdf asfasdfasdf')
connection.close()
- 订阅者1
import pika
credentials = pika.PlainCredentials("admin","admin")
connection = pika.BlockingConnection(pika.ConnectionParameters('10.0.0.101',credentials=credentials))
channel = connection.channel()
# exchange='m1',exchange(秘书)的名称
# exchange_type='fanout' , 秘书工作方式将消息发送给所有的队列
#1 声明exchange 交换机
channel.exchange_declare(exchange='m1',exchange_type='direct')
# 随机生成一个队列
result = channel.queue_declare(queue='',exclusive=True)
queue_name = result.method.queue
print('随机生成的queue的名字',queue_name)
# 2 队列queue绑定交换机
# 让exchange和queque进行绑定.
channel.queue_bind(exchange='m1',queue=queue_name,routing_key='lqz')
def callback(ch, method, properties, body):
print("消费者接受到了任务: %r" % body)
channel.basic_consume(queue=queue_name,on_message_callback=callback,auto_ack=True)
channel.start_consuming()
- 订阅者2
import pika
credentials = pika.PlainCredentials("admin","admin")
connection = pika.BlockingConnection(pika.ConnectionParameters('10.0.0.101',credentials=credentials))
channel = connection.channel()
# exchange='m1',exchange(秘书)的名称
# exchange_type='fanout' , 秘书工作方式将消息发送给所有的队列
#1 声明exchange 交换机
channel.exchange_declare(exchange='m1',exchange_type='direct')
# 随机生成一个队列
result = channel.queue_declare(queue='',exclusive=True)
queue_name = result.method.queue
print('随机生成的queue的名字',queue_name)
# 2 队列queue绑定交换机
# 让exchange和queque进行绑定.
channel.queue_bind(exchange='m1',queue=queue_name,routing_key='nb')
def callback(ch, method, properties, body):
print("消费者接受到了任务: %r" % body)
channel.basic_consume(queue=queue_name,on_message_callback=callback,auto_ack=True)
channel.start_consuming()
9.2 交换机模式:topic - 模糊匹配routing_key
- 发布者
import pika
credentials = pika.PlainCredentials("admin","admin")
connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials))
channel = connection.channel()
channel.exchange_declare(exchange='m3',exchange_type='topic')
channel.basic_publish(exchange='m3',
# routing_key='lqz.handsome', #都能收到
routing_key='lqz.handsome.xx', #只有lqz.#能收到
body='lqz nb')
connection.close()
- 订阅者1
*只能加一个单词
#可以加任意单词字符
import pika
credentials = pika.PlainCredentials("admin","admin")
connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials))
channel = connection.channel()
# exchange='m1',exchange(秘书)的名称
# exchange_type='direct' , 秘书工作方式将消息发送给不同的关键字
channel.exchange_declare(exchange='m3',exchange_type='topic')
# 随机生成一个队列
result = channel.queue_declare(queue='',exclusive=True)
queue_name = result.method.queue
print(queue_name)
# 让exchange和queque进行绑定.
channel.queue_bind(exchange='m3',queue=queue_name,routing_key='lqz.#')
def callback(ch, method, properties, body):
print("消费者接受到了任务: %r" % body)
channel.basic_consume(queue=queue_name,on_message_callback=callback,auto_ack=True)
channel.start_consuming()
- 订阅者2
import pika
credentials = pika.PlainCredentials("admin","admin")
connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials))
channel = connection.channel()
# exchange='m1',exchange(秘书)的名称
# exchange_type='topic' , 模糊匹配
channel.exchange_declare(exchange='m3',exchange_type='topic')
# 随机生成一个队列
result = channel.queue_declare(queue='',exclusive=True)
queue_name = result.method.queue
print(queue_name)
# 让exchange和queque进行绑定.
channel.queue_bind(exchange='m3',queue=queue_name,routing_key='lqz.*')
def callback(ch, method, properties, body):
queue_name = result.method.queue # 发送的routing_key是什么
print("消费者接受到了任务: %r" % body)
channel.basic_consume(queue=queue_name,on_message_callback=callback,auto_ack=True)
channel.start_consuming()