微调定制化的大型语言模型需要投入大量时间和精力,但掌握恰当的微调方法和技巧能显著提高效率。比如用LoRa(LLM的低秩适配Low-Rank Adaptation)微调大模型,能够利用少量显卡和时间对大模型进行微调,降低成本。通过矩阵秩的分解,将原始模型的参数分解成两个小的矩阵乘积,仅训练这两个矩阵的参数,从而实现对大模型的有效微调。这种方法在大模型背景下与量化、剪裁、蒸馏等方法处于同一地位,有效提高了微调效率。
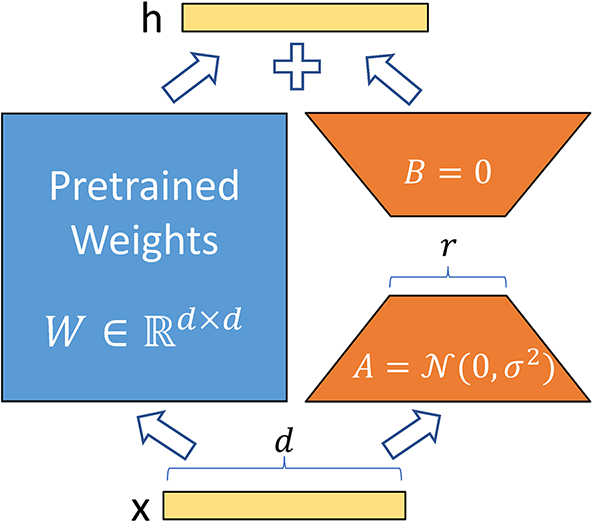
来自原始论文的示意图,展示模型中一个矩阵的张量运算
选择合适的模型
首先在模型的选择上面,关键在于根据实际应用场景和需求选择合适的模型。如果你的应用领域是广泛类型,比如问答或文本生成,那么通用语言模型是个好选择。但如果你专注于特定领域,比如医疗或金融,专门为这些领域设计的模型会提供更高的准确性和专业性。例如,构建金融领域的智能助手,最好选用专为金融领域微调的LoRa模型,以确保获得更精确的预测和建议。
数据准备
在数据集准备过程中,重要的是数据质量。先去除重复数据,以免模型过度依赖某些特定情况进行响应。其次筛选掉嘈杂数据,例如噪音干扰、语音不清晰的样本,以提高模型识别准确率。此外还可以根据实际需求,对数据进行均衡处理,使得模型能够更好地适应不同类型的用户和场景。比如开发一款智能手机的智能语音助手,就需要准备大量与手机语音识别和助手功能相关的数据集,包括训练数据和验证数据。训练数据用于训练模型,而验证数据用于评估模型性能。数据应涵盖用户询问、指令执行、错误处理等各种场景。
微调
接下来就是模型优化,通过不断优化和验证来提高准确性,减少延迟。比如在语音识别系统中,收集大量具有清晰发音和多样性的语音数据进行训练,使模型能适应各种语音环境。同时,对模型进行调整,如改进注意力机制,使其更能关注到关键信息。
超参数的调整
为了获得最佳的微调效果,需要根据实际需求和任务特点来调整学习率、批次大小、迭代次数等超参数。这可能需要多次尝试和验证,以找到最适合当前任务的超参数组合。
较小的学习率会使模型收敛速度较慢,但可能得到更稳定的解;较大的学习率会使模型收敛速度加快,但可能导致不稳定或无法收敛。较大的批次可以提高训练速度,但可能导致梯度消失或梯度爆炸等问题;较小的批次可以提高模型泛化能力,但训练速度较慢。增加迭代次数有助于提高模型性能,但同时会消耗更多时间和计算资源。了解这些超参数对模型性能的影响,通过调整超参数来达到最佳的微调效果。
模型评估
在微调过程中,还需要不断检查模型的性能指标,不断评估模型性能,如准确率、召回率等指标,以便了解微调的效果并据此调整优化策略,提高模型性能。
模型部署
微调后的模型将被部署到实际应用环境中,例如家庭版的LoRa设备,可以无线接收和发送数据,实时控制家居设备。企业通过密切关注用户的使用情况,收集用户反馈和操作数据,分析出使用频率高的功能、需要进一步优化的功能等。
比如,客户习惯在早上起床后,调整温度和灯光,基于这些行为数据,企业可以继续优化微调后的模型,为起床场景增加相应的操控方式。通过不断迭代,家居控制系统更贴切用户的生活习惯和需求,达到更智能化的目的。

对于追求高级AI领域项目研发的开发者来说,最大化LoRa微调语言模型的性能至关重要。这不仅是技术进步的关键,也是推动人工智能应用的提升、在竞争激烈的领域中脱颖而出的必要条件。