Keras != tf.keras
▪ datasets
▪ layers
▪ losses
▪ metrics(主要)
▪ optimizers
1 Keras.Metrics
1.Metrics(新建一个Matrics)
2.update_state(添加数据)
3.result().numpy()(得到结果)
4.reset_states(清0)
1.1 step1.Build meter

第一个数准确度的metrics,第二个是平均值的metrics。
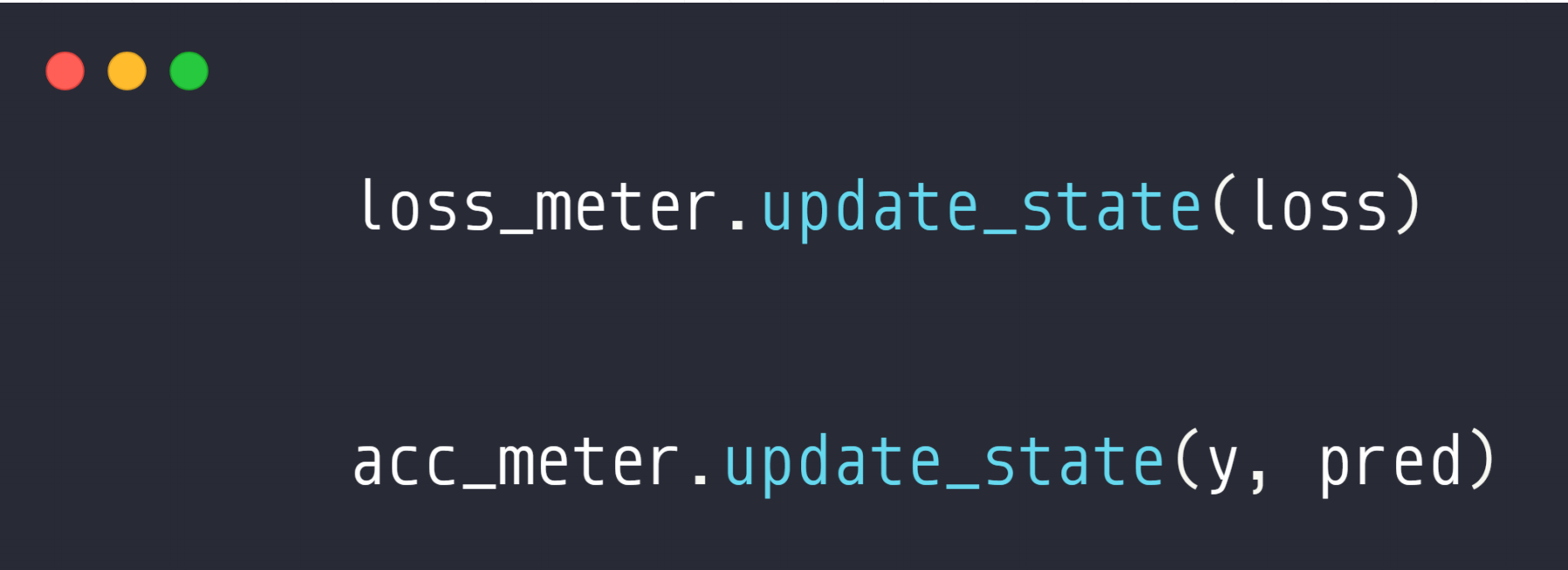
1.2 step2.Update data
我们向那个里面添加数据,我们就调用那个名字.update_state()
1.3 step3.Get Average data
可以得到一个结果,就是将他转化成.result().numpy()

1.4 step4.clear buffer
就是如果我们向清理这个里面的缓存的话,我们调用.reset_states()
我们之前的代码用了那些API之后:
import tensorflow as tf
from tensorflow.keras import datasets, layers, optimizers, Sequential, metrics
def preprocess(x, y):
x = tf.cast(x, dtype=tf.float32) / 255.
y = tf.cast(y, dtype=tf.int32)
return x,y
batchsz = 128
(x, y), (x_val, y_val) = datasets.mnist.load_data()
print('datasets:', x.shape, y.shape, x.min(), x.max())
db = tf.data.Dataset.from_tensor_slices((x,y))
db = db.map(preprocess).shuffle(60000).batch(batchsz).repeat(10)
ds_val = tf.data.Dataset.from_tensor_slices((x_val, y_val))
ds_val = ds_val.map(preprocess).batch(batchsz)
network = Sequential([layers.Dense(256, activation='relu'),
layers.Dense(128, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(32, activation='relu'),
layers.Dense(10)])
network.build(input_shape=(None, 28*28))
network.summary()
optimizer = optimizers.Adam(lr=0.01)
acc_meter = metrics.Accuracy() #定义
loss_meter = metrics.Mean() #定义
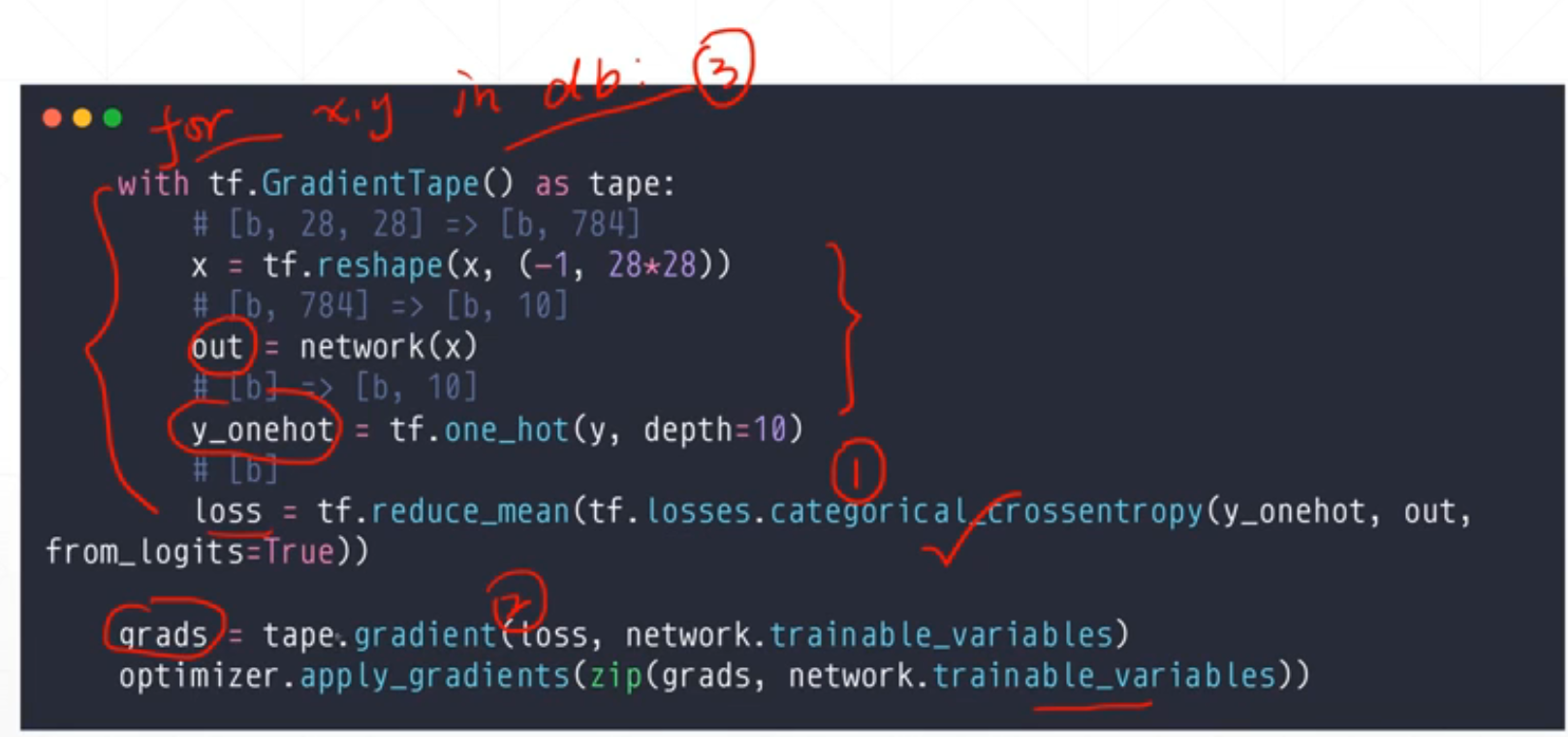
for step, (x,y) in enumerate(db):
with tf.GradientTape() as tape:
# [b, 28, 28] => [b, 784]
x = tf.reshape(x, (-1, 28*28))
# [b, 784] => [b, 10]
out = network(x)
# [b] => [b, 10]
y_onehot = tf.one_hot(y, depth=10)
# [b]
loss = tf.reduce_mean(tf.losses.categorical_crossentropy(y_onehot, out, from_logits=True))
loss_meter.update_state(loss) #更新
grads = tape.gradient(loss, network.trainable_variables)
optimizer.apply_gradients(zip(grads, network.trainable_variables))
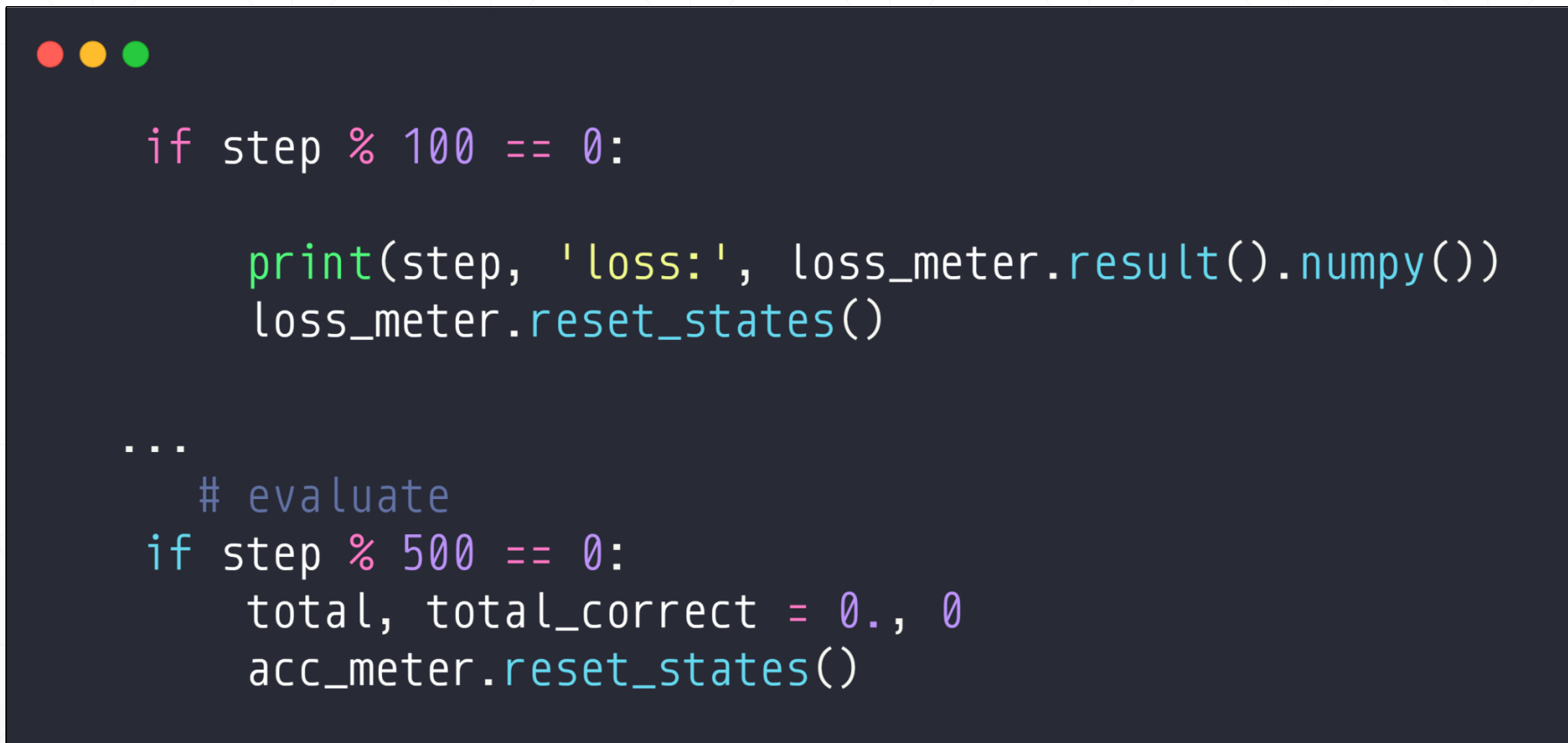
if step % 100 == 0:
print(step, 'loss:', loss_meter.result().numpy()) #输出
loss_meter.reset_states() #清空
# evaluate
if step % 500 == 0:
total, total_correct = 0., 0
acc_meter.reset_states() #清空
for step, (x, y) in enumerate(ds_val):
# [b, 28, 28] => [b, 784]
x = tf.reshape(x, (-1, 28*28))
# [b, 784] => [b, 10]
out = network(x)
# [b, 10] => [b]
pred = tf.argmax(out, axis=1)
pred = tf.cast(pred, dtype=tf.int32)
# bool type
correct = tf.equal(pred, y)
# bool tensor => int tensor => numpy
total_correct += tf.reduce_sum(tf.cast(correct, dtype=tf.int32)).numpy()
total += x.shape[0]
acc_meter.update_state(y, pred)
print(step, 'Evaluate Acc:', total_correct/total, acc_meter.result().numpy())
2 Compile&Fit
1.Compile(优化器的选择)
2.Fit(compile之后fit)
3.Evaluate(测试)
4.Predict(预测)
我们之前的Individual loss and optimize
其实上面的三步是确定的,步骤基本都是一样的,所以我们的kears就定义了上面的的更简洁的步骤
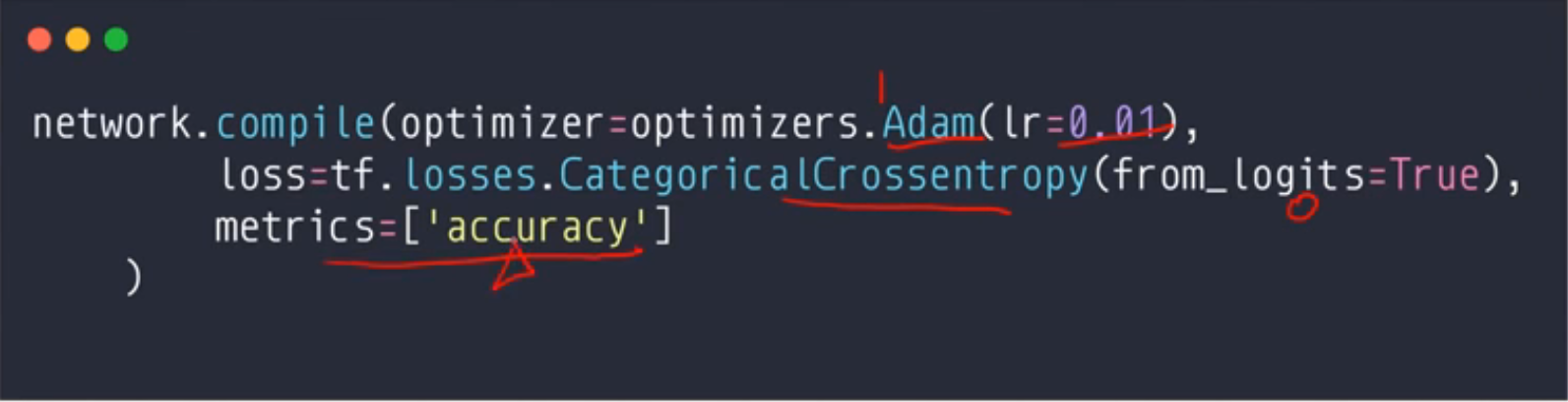
然后以前需要两层循环:Individual epoch and step

现在也可以简化:fit之后这个epochs也指定了
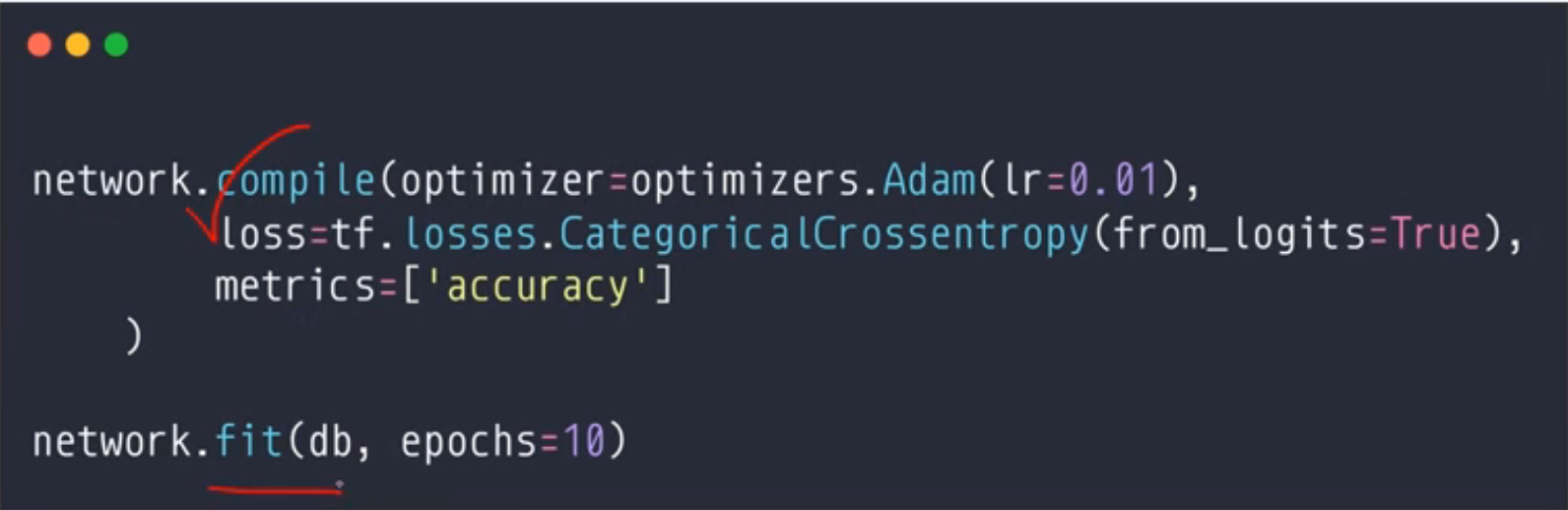
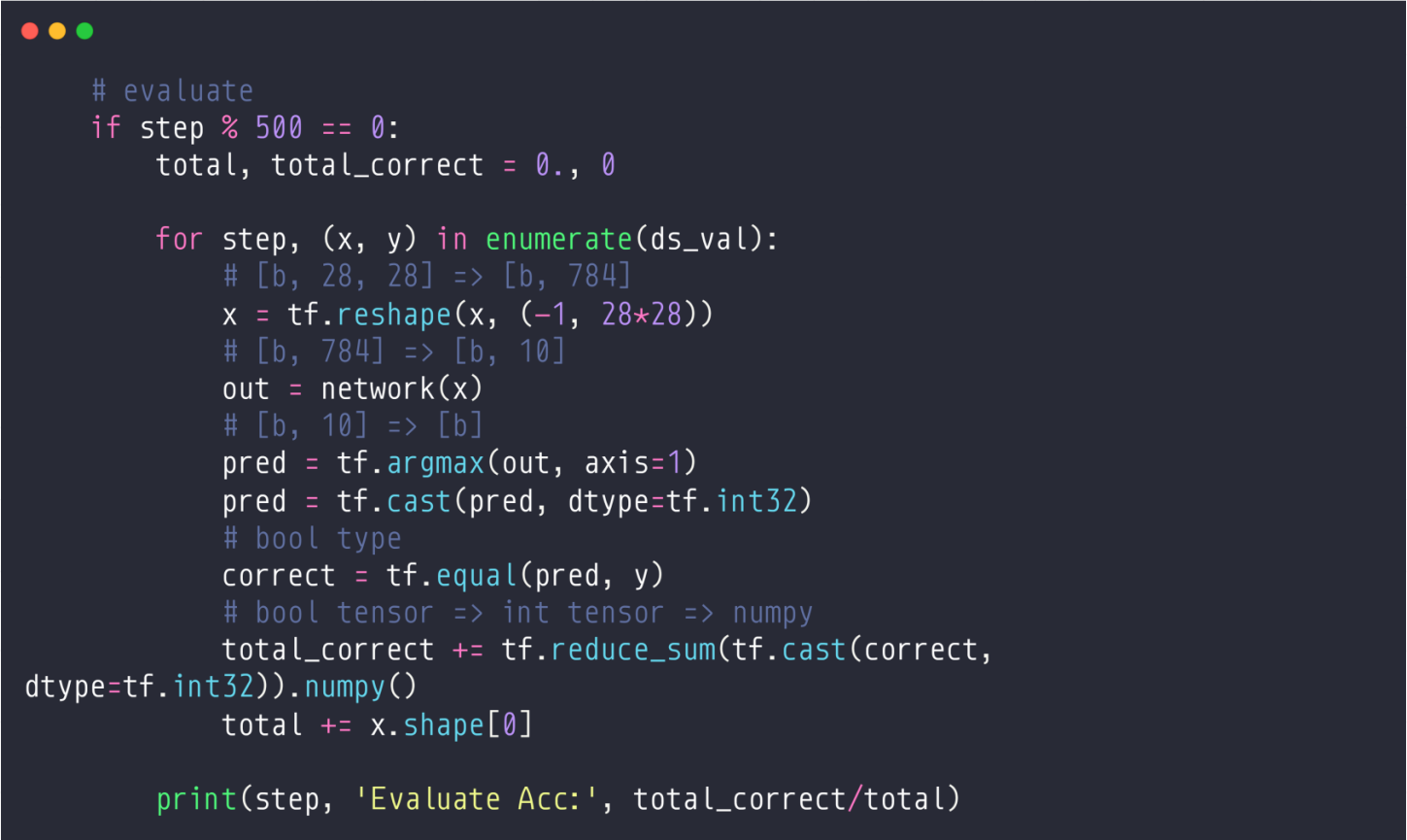
以前的测试:Individual evaluation
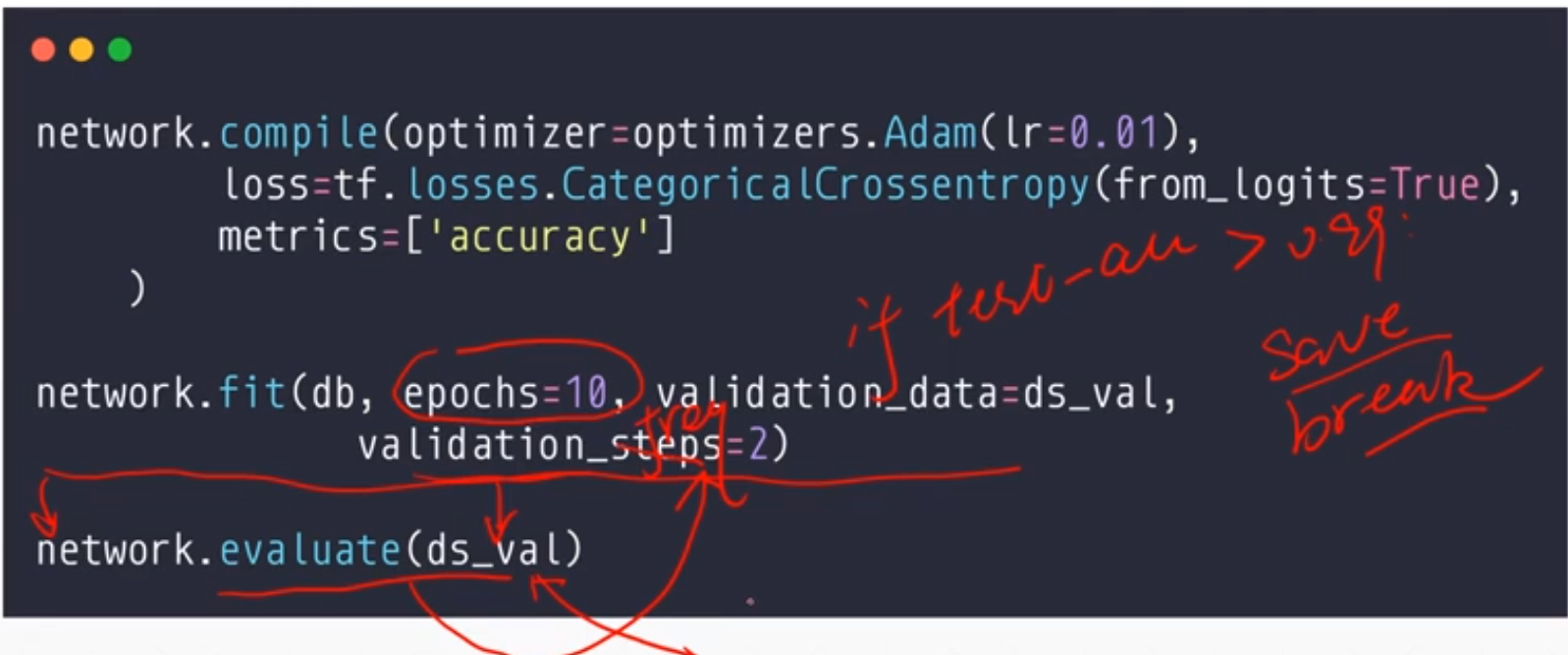
现在的测试:

这个validation_sreq=2,代表着是db,db,ds-val,db,db,ds-val。这个就是两个db之后一个ds-val。
然后输出的结果就是这样的:
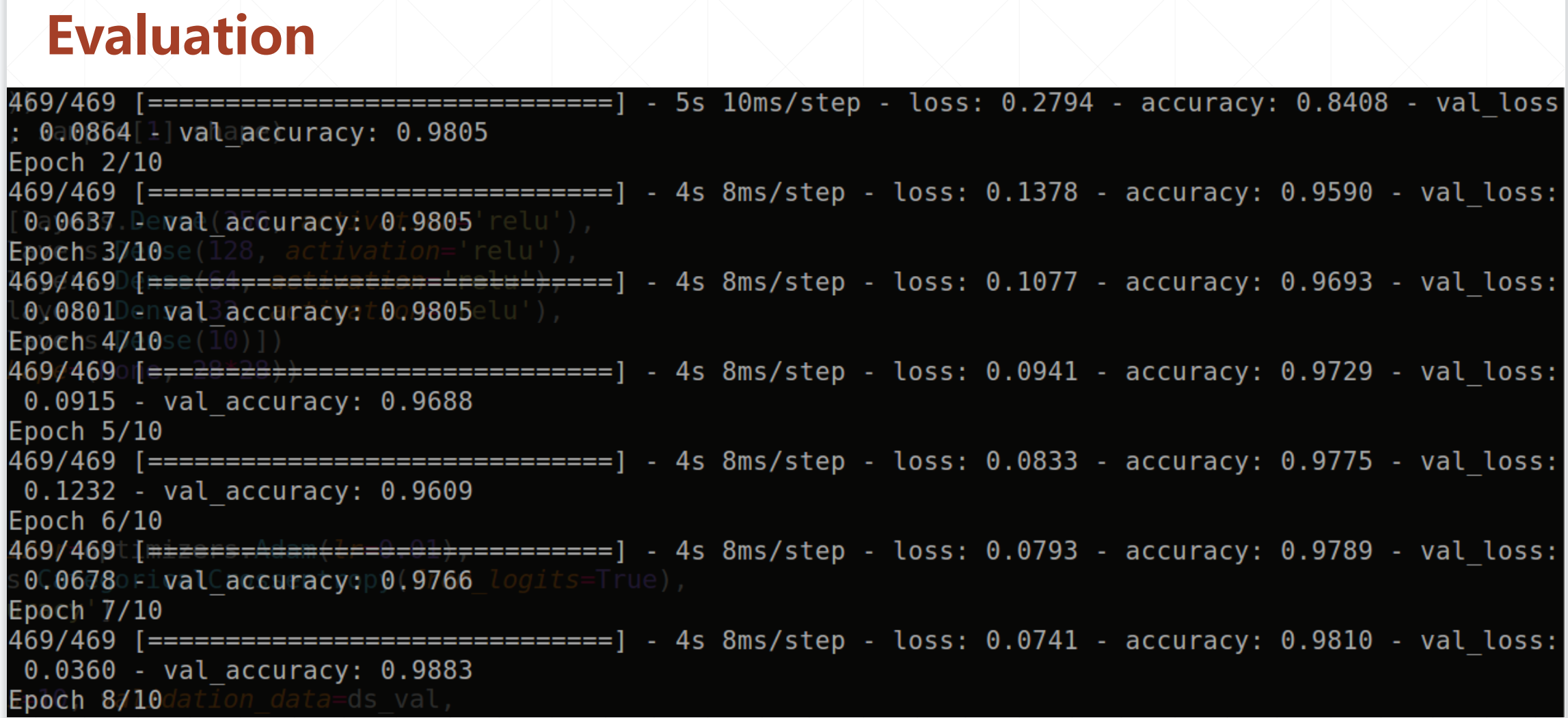
然后就是测试:
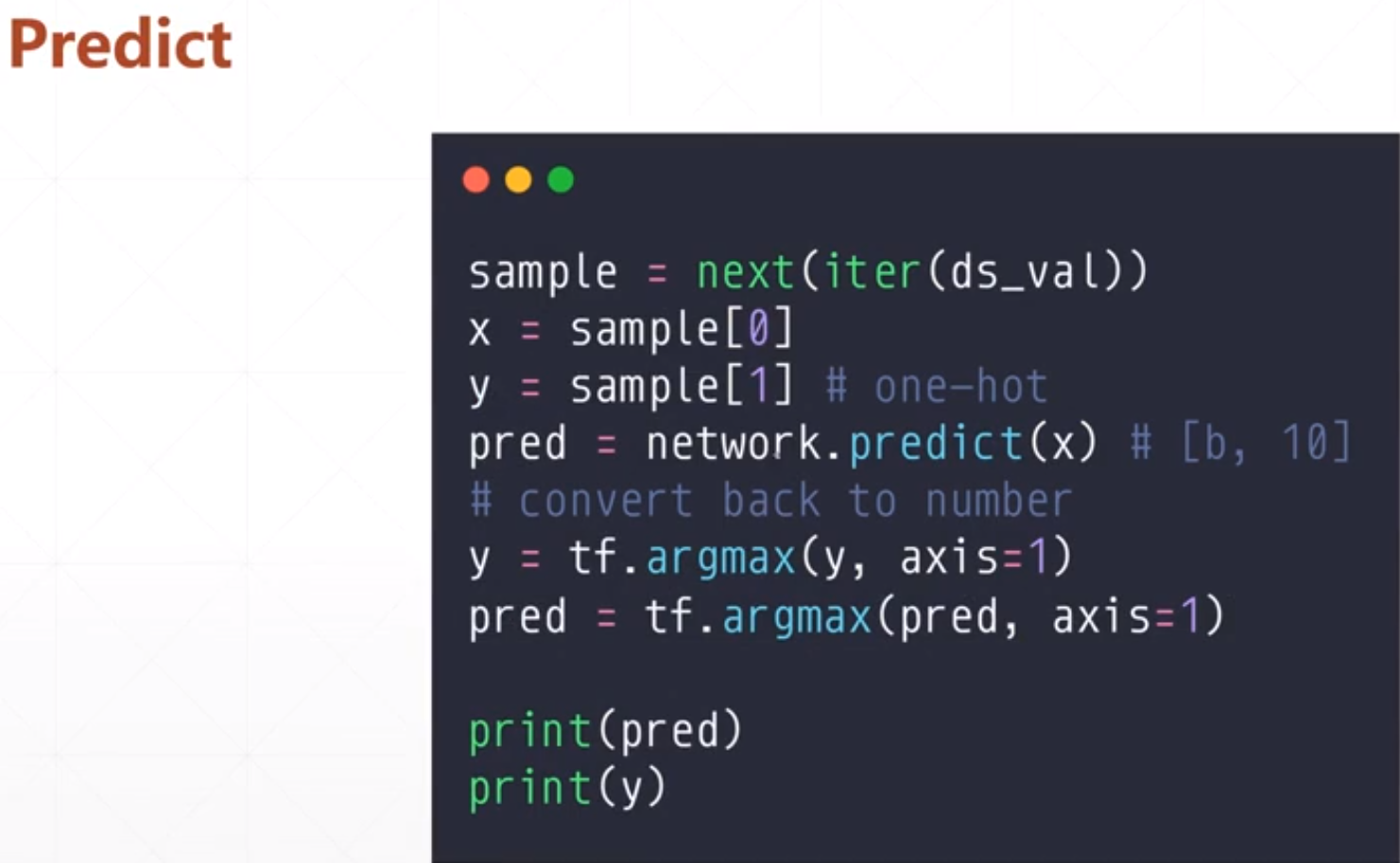
最后就是预测的部分: