楔子
在编写网络应用程序时,我们使用了 socket 库来读取和写入客户端。虽然在构建低级网络库时直接使用套接字很有效,但用法上还是有些复杂,例如启动服务端、等待客户端连接以及向客户端发送数据等等。asyncio 的设计者意识到这一点,并构建了网络流 API,这些更高级的 API 比套接字更容易使用,利用这些 API 创建的任何客户端、服务端应用程序,比我们自己使用套接字更方便且更健壮。而流是在 asyncio 中构建基于网络的应用程序的推荐方法。
什么是流
在 asyncio 中,流是一组高级的类和函数,用于创建、管理网络连接和通用数报流。使用它们,我们可以创建客户端连接来读取和写入数据,也可以创建服务端并自己管理它们。这些 API 抽象了很多关于管理套接字的方法,例如处理 SSL 或丢失的连接,极大地减轻了开发人员的工作负担。
流 API 构建在称为传输和协议的一组较低级别的 API 之上,这些 API 直接包装了我们在前几章中使用的套接字,并提供了一个简单的方式来读取套接字数据以及将数据写入套接字。
这些 API 的结构与其他 API 稍有不同,因为它们使用回调样式设计。与之前所做的那些主动等待套接字数据不同,当数据可用时,我们会调用的实例上的某个方法,然后根据需要来处理在此方法中收到的数据。下面就来学习这些基于回调的 API 是如何工作的,让我们首先看看如何通过构建一个基本的 HTTP 客户端来使用较低级的传输和协议。
传输和协议
在高层次上,传输是与任意数据流进行通信的抽象,与套接字或任何数据流(如标准输入)通信时,我们将使用一组熟悉的操作。从数据源读取数据或向目标写入数据,当我们完成对它的处理时,将关闭相应的数据源。而套接字完全符合我们定义的这种传输抽象的方式,也就是说,读取和写入数据,一旦完成,就关闭它。简而言之,传输提供了向源发送数据和从源接收数据的定义。传输有多种实现,具体取决于我们使用的源的类型,我们主要关注 ReadTransport、WriteTransport 和 Transport,还有其他一些用于处理 UDP 连接和子进程通信的实现。

在套接字之间来回传输数据只是这个过程的一部分,那么套接字的生命周期是怎样的呢?我们建立连接,写入数据,然后处理得到的任何响应,这些是协议拥有的一组操作。注意,这里的协议只指一个 Python 类,而不是 HTTP 或 FTP 之类的协议。传输可以管理数据的传递,并在事件发生时调用协议上的方法,例如建立连接或准备处理数据。
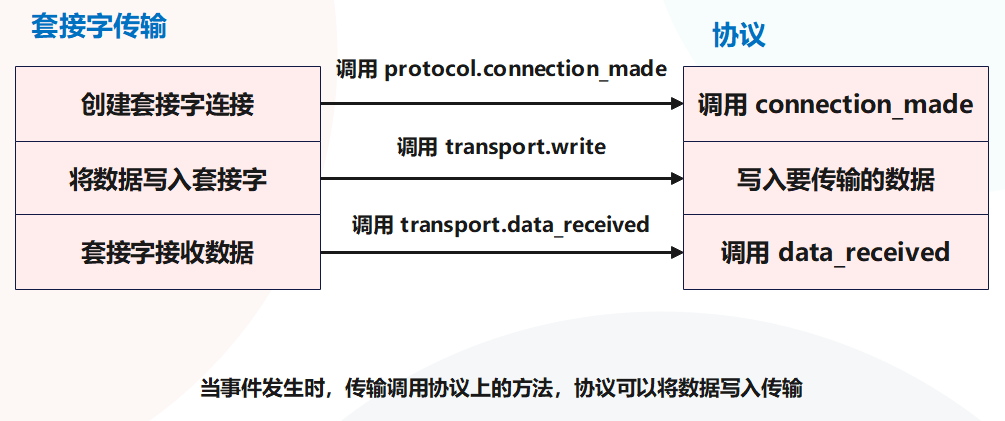
为了解传输和协议如何协同工作,我们将构建一个基本应用程序来运行单个 HTTP GET 请求。我们需要做的第一件事是定义一个继承 asyncio.Protocol 的类,并覆盖父类的一些方法来发出请求、从请求中接收数据,并处理连接中的任何错误。
需要实现的第一个协议方法是 connection_made,当底层套接字与 HTTP 服务器成功连接时,传输将调用此方法。此方法使用 Transport 作为参数,我们可以使用它与服务器通信。这种情况下,将使用传输立即发送HTTP 请求。
需要实现的第二个方法是 data_received,传输在接收数据时调用此方法,并将其作为字节传递给我们。这个方法可以被多次调用,所以需要创建一个内部缓冲区来存储数据。
import asyncio
from asyncio import Transport, AbstractEventLoop
from typing import Optional
class HTTPGetClientProtocol(asyncio.Protocol):
def __init__(self, host: str, loop: AbstractEventLoop):
self._host = host
self._future = loop.create_future()
self._transport: Optional[Transport] = None
self._response_buffer: bytes = b""
async def get_response(self):
# 等待 self._future,直到从服务器得到响应并写入 self._future
return await self._future
def _get_request_bytes(self) -> bytes:
# 创建 HTTP 请求
request = ("GET / HTTP/1.1\r\n"
"Connection: close\r\n"
f"Host: {self._host}\r\n\r\n")
return request.encode("utf-8")
def connection_made(self, transport: Transport) -> None:
"""底层套接字和服务器端建立连接时会调用此方法"""
print(f"和 {self._host} 建立连接")
# 会自动传入一个 transport 参数,它就是传输,我们用它来管理数据
# 并在事件发生时调用协议上的方法,比如这里的 connection_made,我们将传输保存起来
self._transport = transport
# 调用传输的 write 方法写入数据
self._transport.write(self._get_request_bytes())
def data_received(self, data: bytes) -> None:
"""传输在收到数据时会调用协议的 data_received 方法"""
print("收到数据")
self._response_buffer += data
def eof_received(self) -> Optional[bool]:
"""
如果服务端已经将所有数据都返回完毕,那么会关闭连接
此时传输会自动调用协议的 eof_received 方法
"""
print("数据全部接收完毕")
# 响应数据都接收完毕,将其写入 future 中
self._future.set_result(self._response_buffer)
# 该方法返回一个布尔值,用于确定如何关闭传输(底层套接字)
# 返回 False 则让传输自行关闭,返回 True 意味着需要编写协议来关闭
# 由于当前不需要在关闭时执行什么特殊逻辑,所以返回 False 即可
# 因此我们不需要手动处理关闭传输
return False
def connection_lost(self, exc: Optional[Exception]) -> None:
"""当连接关闭时会调用此方法"""
# 如果连接正常关闭,则什么也不做
if exc is None:
print("连接正常关闭")
else:
# 否则将异常设置到 future 里面
self._future.set_exception(exc)
async def make_request(host: str, port: int, loop: AbstractEventLoop):
# 协议工厂,调用之后创建一个协议实例
def protocol_factory():
return HTTPGetClientProtocol(host, loop)
# create_connection 将创建到给定主机的套接字连接,并将其包装在适当的传输中
# 当建立连接之后,会自动调用协议的 connection_made,在该方法中会向目的主机发送请求
# 当数据达到时,会自动协议的 data_received,数据返回完毕时自动调用协议的 eof_received
transport, protocol = await loop.create_connection(protocol_factory, host=host, port=port)
# 将数据写入 future 之后,调用 get_response 得到响应数据
# 在 create_connection 里面我们传入了一个协议工厂,在里面会自动调用
# 返回的 transport 就是传输,protocol 就是内部的创建协议实例,但传输这里我们不需要
return await protocol.get_response()
async def main():
loop = asyncio.get_running_loop()
result = await make_request("www.baidu.com", 80, loop)
print("百度一下".encode("utf-8") in result)
asyncio.run(main())
"""
和 www.baidu.com 建立连接
收到数据
收到数据
数据全部接收完毕
True
连接正常关闭
"""
我们已经学会了使用传输和协议,但这些 API 是较低级别的,因此不推荐。我们更建议使用流,这是一种扩展了传输和协议的更高级别的抽象。
流读取与流写人
传输和协议是较低级别的 API,最适合在发送和接收数据时直接控制所发生的事情。例如,如果正在设计一个网络库或 Web 框架,可能会考虑传输和协议。但对于大多数应用程序,我们不需要这种级别的控制,使用传输和协议将会编写一些重复的代码。
asyncio 的设计者意识到了这一点,并创建了更高级别的流 API,该 API 将传输和协议的标准用例封装成两个易于理解和使用的类:StreamReader 和 StreamWriter。顾名思义,它们分别处理对流的读取和写入,使用这些类是在 asyncio 中开发网络应用程序的推荐方法。
为帮助你了解如何使用这些 API,下面列举一个发出 HTTP GET 请求并将其转换为流的示例。asyncio 没有直接生成 StreamReader 和 StreamWriter 的实例,而是提供一个名为 open_connection 的库协程函数,它将创建这些实例。这个协程接收目的主机的地址和端口,并以元组形式返回 StreamReader 和 StreamWriter。我们的计划是使用 StreamWriter 发送 HTTP 请求,并使用 StreamReader 读取响应。StreamReader 方法很容易理解,我们有一个方便的 readline 协程方法,它会一直等到我们获得一行数据,或者也可以使用 SteamReader 的 read 协程方法等待指定数量的字节到达。
StreamWriter 稍微复杂一些,它有一个 write 方法,该方法是一个普通方法而不是协程。在内部,流写入器尝试立即写入套接字的输出缓冲区,但此缓冲区可能已满。如果套接字的写入缓冲区已满,则数据将存储在内部队列中,以后可以进入缓冲区。但这带来一个潜在问题,即调用 write 不一定会立即发送数据,这会导致什么后果呢?想象一下,网络连接变慢了,每秒只能发送 1KB,但应用程序每秒写入 1MB。这种情况下,应用程序的写缓冲区填满的速度,比把数据发送到套接字缓冲区的速度快得多,最终将达到机器内存的限制,并导致崩溃。
那怎么能等到所有数据都正确地发送出去呢?为解决这个问题,可使用一个叫做 drain 的协程方法。这个协程将阻塞(直到所有排队的数据被发送到套接字),确保我们在继续运行程序之前,已经写出所有内容。从技术角度看,不必在每次写入后都调用 drain,但这有助于防止错误发生。
import asyncio
from asyncio import StreamReader
from typing import AsyncGenerator
async def read_until_empty(stream_reader: StreamReader) -> AsyncGenerator[bytes, None]:
# 读取一行,直到没有任何剩余数据
while response := await stream_reader.readline():
yield response
async def main():
host = "www.baidu.com"
request = ("GET / HTTP/1.1\r\n"
"Connection: close\r\n"
f"Host: {host}\r\n\r\n")
stream_reader, stream_write = await asyncio.open_connection(host, 80)
try:
stream_write.write(request.encode("utf-8"))
await stream_write.drain()
response = b"".join([r async for r in read_until_empty(stream_reader)])
print("百度一下".encode("utf-8") in response)
finally:
# 关闭 writer
stream_write.close()
# 并等待它完成关闭
await stream_write.wait_closed()
asyncio.run(main())
"""
True
"""
我们首先创建了一个简单的异步生成器从 StreamReader 读取所有行,直到没有任何剩余的数据要处理。然后在主协程中,打开一个到 baidu.com 的连接,在这个过程中创建一个 StreamReader 和 StreamWriter 实例。然后分别使用 write 和 drain 写入请求。一旦完成了写入请求,将使用异步生成器从响应中获取每一行数据,将它们存储在响应列表中,最后通过调用 close 关闭 StreamWriter 实例,然后等待 wait_closed 协程。为什么需要在这里调用一个方法和一个协程?原因是当调用 close 时会执行一些动作,例如取消注册套接字和底层传输调用 connection_lost 方法,这些都是在事件循环的后续迭代中异步发生的。这意味着在调用 close 之后,连接不会马上关闭,而是直到稍后的某个时间才会关闭。如果你需要等待连接关闭才能继续操作,或者担心关闭时可能发生的任何异常,最好调用 wait_closed。
然后再来聊一聊 StreamReader,它有以下几个协程方法:
read(self, n=-1):如果 n 为 -1,那么会一直读到 EOF 并返回已读取的所有内容。如果 n 大于 0,则读取指定的字节数并返回,如果不够那么有多少读多少;readexactly(self, n):读取 n 个字节,数据不够 n 个字节,则返回 IncompleteReadError;readline(self):从流中读取数据块,直到找到换行符 b"\\n"。如果成功,那么返回带有换行符的数据块。如果在遇到换行符之前先遇到了 EOF(响应结束了),那么直接返回读到的行;readuntil(self, separator=b'\n'):读取数据,直到找到指定的分隔符 separator。readline 本质上也是调用了 readuntil,而且 readuntil 的 separator 的默认就是换行符,所以它默认等价于 readline,当然我们也可以指定为别的;
如果没有返回数据(直接读到了 EOF),那么这几个方法会返回空字节串(readexactly 特殊,字节不够会报错)。
现在通过发出 Web 请求了解了有关流 API 的基础知识,但这些类的用处超出了基于 Web 和网络的应用程序,接下来我们将了解如何利用流读取器来创建非阻塞命令行应用程序。
非阻塞命令行输入
一般情况下,在 Python 中要获取用户输入时,我们会使用 input 函数。该函数将会阻塞线程,直到用户提供输入并按下 Enter 键。但如果想在后合运行代码,同时保持对输入的响应呢?例如,我们可能想让用户同时启动多个长时间运行的任务,例如长时间运行的 SQL 查询。而对于命令行聊天应用程序,则可能希望用户能够在接收来自其他用户的消息时键入自己的消息。
由于 asyncio 是单线程的,在 asynio 应用程序中使用 input 意味着停止运行事件循环,直到用户提供输入内容,这将停止整个应用程序。即使使用任务在后台启动操作也行不通。为演示这一点,让我们尝试创建一个应用程序,用户输入应用程序的休眠时间。我们希望能够在接收用户输入的同时,一起运行多个这些休眠操作。
import asyncio
async def delay(seconds):
print(f"休眠 {seconds} 秒")
await asyncio.sleep(seconds)
print(f"{seconds} 秒休眠完成")
async def main():
while True:
delay_time = input("请输入休眠时间: ")
asyncio.create_task(delay(int(delay_time)))
asyncio.run(main())
"""
请输入休眠时间: 5
请输入休眠时间: 3
请输入休眠时间: 4
请输入休眠时间:
"""
这个问题原因应该很容易理解,input 会阻塞整个线程,所以任务永远不执行。
我们真正想要的是将 input 函数改为协程,可以编写类似 words = await input() 的代码。如果能做到这一点,任务将正确调度,并在等待用户输入时继续运行。不幸的是,input 没有协程变体,所以需要使用其他技术来实现。 而这正是协议和流读取器可以帮助我们的地方,回顾一下,流读取器有 readline 协程方法,这是我们正在寻找的协程类型。如果有办法将流读取器连接到标准输入,就可以使这个协程实现用户输入。
asyncio 在事件循环上有一个名为 connect_read_pipe 的协程方法,它将协议连接到类似文件的对象,这与我们预想的几乎相同。这个协程方法接收一个协议工厂(protocol factory)和一个管道(pipe),协议工厂只是一个创建协议实例的函数,管道(pipe)是一个类似文件的对象,它被定义为一个对象,上面有读写等方法。connect_read_pipe 协程将管道连接到工厂创建的协议,从管道中获取数据,并将其发送到协议。
就标准控制台输入而言,sys.stdin 符合传递给 connect_read_pipe 的类文件对象的要求。一旦调用了这个协程,就会得到一个工厂函数创建的协议和一个 ReadTransport。现在的问题是我们应该在工厂中创建什么协议,以及如何将它和具有我们想要使用的 readline 协程的 StreamReader 连接起来?
asyncio 提供了一个名为 StreamReaderProtocol 的实用程序类,用于将流读取器的实例连接到协议。当实例化这个类时,我们传入一个流读取器的实例,然后协议类委托给我们创建的流读取器,允许使用流读取器从标准输入中读取数据。将所有这些内容放在一起,可创建一个在等待用户输入时,不会阻塞事件循环的命令行应用程序。
import asyncio
from asyncio import StreamReader
import sys
async def create_stdin_reader() -> StreamReader:
stream_reader = asyncio.StreamReader()
protocol = asyncio.StreamReaderProtocol(stream_reader)
loop = asyncio.get_running_loop()
await loop.connect_read_pipe(lambda: protocol, sys.stdin)
return stream_reader
在代码中,我们创建了一个名为 create_stdin_reader 的可重用协程,它创建了个 StreamReader,我们将使用它来异步读取标准输入。首先创建一个流读取器实例并将其传递给流读取器协议,然后调用 connect_read_pipe,将协议工厂作为 lambda 函数传入。这个 lambda 函数会自动调用,并返回我们之前创建的流读取器协议,然后通过 sys.stdin 将标准输入连接到流读取器协议。并且 connect_read_pipe 会返回传输和协议,但当前不需要它们,因此忽略了。现在可以使用此函数从标准输入异步读取,并构建应用程序。
import asyncio
from asyncio import StreamReader
import sys
async def create_stdin_reader() -> StreamReader:
stream_reader = asyncio.StreamReader()
protocol = asyncio.StreamReaderProtocol(stream_reader)
loop = asyncio.get_running_loop()
await loop.connect_read_pipe(lambda: protocol, sys.stdin)
return stream_reader
async def delay(seconds):
print(f"休眠 {seconds} 秒")
await asyncio.sleep(seconds)
print(f"{seconds} 秒休眠完成")
async def main():
stdin_reader = await create_stdin_reader()
while True:
delay_time = await stdin_reader.readline()
asyncio.create_task(delay(int(delay_time)))
asyncio.run(main())
"""
10
休眠 10 秒
5
休眠 5 秒
1
休眠 1 秒
1 秒休眠完成
5 秒休眠完成
10 秒休眠完成
"""
在主协程中,调用 create_stdin_reader 并无限循环,等待来自具有 readline 协程的用户的输入。一旦用户在键盘上按下 Enter 键,这个协程就会传递输入的文本。当从用户那里得到输入的内容,就将它转换成一个整数并创建一个delay 任务。运行它,你将能在输入命令行的同时,运行多个 delay 任务。
但令人遗憾的是,在 Windows 系统上,connect_read_pipe 与 sys.stdin 不匹配。这是由于 Windows 实现文件描述符的方式导致的未修复错误,你可通过 https://bugs.python.org/issue26832 了解更多详细信息。
创建服务器
构建服务器时,我们创建了一个服务器套接字,将其绑定到一个端口并等待传入的连接。虽然这可行,但 asyncio 允许在更高的抽象级别上创建服务器,这意味着创建它们之后不用操心套接字的管理问题。以这种方式创建服务器简化了需要为使用套接字编写的代码,因此使用这些更高级别的 API 是使用 asyncio 创建和管理服务器的推荐方法。
可使用 asyncio.start_server 协程创建一个服务器,这个协程接收几个可选参数来配置诸如 SSL 的参数,但我们关注的主要参数是 host、port 和 client_connected_cb。host 和 port 就像我们之前看到的一样:服务器套接字监听的地址的端口,但有趣的部分是 client_connected_cb,它要么是一个回调函数,要么是一个在客户端连接到服务器时将运行的协程。此回调将 StreamReader 和 StreamWriter 作为参数,让我们可以读取和写入连接到服务器的客户端。
而 await start_server 时,它会返回一个 AbstractServer 对象,这是一个抽象类,调用它的 serve_forever 方法可以永远运行服务器,直到我们终止它。并且这个类也是一个异步上下文管理器,这意味着可使用带有 async with 语法的实例来让服务器在退出时正确关闭。
为了掌握如何创建服务器,让我们再次创建一个回显服务器,但要提供一些更高级的功能。除了回显输出,还将显示有多少其他客户端已连接到服务器,并且客户端和服务器断开连接时显示断开的客户端信息。
import asyncio
from asyncio import StreamReader, StreamWriter
import logging
class ServerState:
def __init__(self):
self._writers = []
async def add_client(self, reader: StreamReader, writer: StreamWriter):
"""添加客户端,并创建回显任务"""
self._writers.append(writer)
await self._on_connect(writer)
asyncio.create_task(self._echo(reader, writer))
async def _on_connect(self, writer: StreamWriter):
"""当有新连接时,告诉客户端有多少用户在线,并同时其他人有新用户上线"""
writer.write(f"欢迎, 当前在线人数有 {len(self._writers)} 人\n".encode("utf-8"))
await writer.drain()
await self._notify_all("新用户上线\n")
async def _echo(self, reader: StreamReader, writer: StreamWriter):
try:
while (data := await reader.readline()) != b"":
writer.write(data + b"~")
await writer.drain()
# 如果客户端断开连接,那么通知其他用户,有人断开连接
self._writers.remove(writer)
await self._notify_all(f"有人断开连接, 当前在线人数为 {len(self._writers)}")
except ConnectionError:
logging.info("客户端断开连接")
except Exception as e:
logging.error(f"出现异常: {e}")
self._writers.remove(writer)
async def _notify_all(self, message: str):
"""向所有其他用户发送消息的辅助方法, 如果发送失败, 将删除该用户"""
for writer in self._writers:
try:
writer.write(message.encode("utf-8"))
await writer.drain()
except ConnectionError as e:
logging.error("无法向客户端写入数据, 连接断开")
self._writers.remove(writer)
async def main():
server_state = ServerState()
async def client_connected(reader: StreamReader, writer: StreamWriter):
await server_state.add_client(reader, writer)
# 当客户端连接时,会调用 client_connected 协程函数,并自动传入 reader 和 writer
# 在里面我们执行 await server_state.add_client
server = await asyncio.start_server(client_connected, "localhost", 9999)
async with server:
await server.serve_forever()
asyncio.run(main())
当用户连接到服务器时,client_connected 回调会响应该用户的读取器和写入器,进而调用 ServerState 实例的 add_client 协程。在 add_client 协程中存储了 StreamWriter,因此我们可以向所有连接的客户端发送消息,并在客户端断开连接时将其删除。然后语用 _on_connect,它会向客户端发送一条消息,通知有多少其他用户已连接。在 _on_connect 中,还通知其他所有已连接的客户端有新用户连接。
小结
在本篇文章中,我们学习了以下内容:
- 使用较低级别的传输和协议 API 来构建一个简单的 HTTP 客户端,这些 API 是高级 asyncio stream API 的基础,不推荐用于一般用途;
- 使用 StreamReader 和 StreamWriter 类来构建网络应用程序,这些更高级别的 API 是在 asyncio 中使用流的推荐方法;
- 使用流来创建非阻塞命令行应用程序,这些应用程序可以在后台运行任务,并保持对用户输入的响应;
- 使用 start_server 协程创建服务器,这种方法是在 asyncio 中创建服务器的推荐方法,而不是直接使用套接字;