参考:
小林 coding : https://xiaolincoding.com/network/3_tcp/tcp_feature.html
重传机制
常见的重传机制:
- 超时重传:发送方在 RTO 内发送方没有收到接收方的 ack 确认应答报文。问题:超时周期可能相对较长
- 快速重传:接收方接收ack的顺序不对快速重传,发送方收到三个相同的 ack 时重传。问题:不知道重传 快速重传阶段 的哪些报文
- 只重传【三次重复 ack 的那一个报文】,效率低,在这之后丢失的还要继续三次快速重传过程;
- 重传【三次重复 ack 后的所有报文】,则可能重复发送已成功接收的。
- SACK:通过 sack 字段将【快速重传阶段】【已成功接收的数据段】告诉发送方,这样发送方只重传【快速重传阶段】【ack 三次那个以及之后没接收的】数据段。
- D-SACK:使用了 SACK 来告诉「发送方」有哪些数据被重复接收了。
超时重传
重传机制的其中一个方式,就是在发送数据时,设定一个定时器,当超过指定的时间后,没有收到对方的 ACK 确认应答报文,就会重发该数据,也就是我们常说的超时重传。
而以下两种情况会收不到对方的 ACK 确认应答。即 TCP 会在以下两种情况发生超时重传:
- 数据包丢失
- 确认应答丢失
超时重传时间 RTO 的选择
RTT指的是数据发送时刻到接收到确认的时刻的差值,也就是包的往返时间。- 超时重传时间是以
RTO(Retransmission Timeout 超时重传时间)表示。

精确的测量超时时间 RTO 的值是非常重要的,这可让我们的重传机制更高效:
- 当超时时间 RTO 较大时,重发就慢,丢了老半天才重发,没有效率,性能差;
- 当超时时间 RTO 较小时,会导致可能并没有丢就重发,于是重发的就快,会增加网络拥塞,导致更多的超时,更多的超时导致更多的重发。
根据上述的两种情况,我们可以得知,超时重传时间 RTO 的值应该略大于报文往返 RTT 的值。
实际上「报文往返 RTT 的值」是经常变化的,因为我们的网络也是时常变化的。也就因为「报文往返 RTT 的值」 是经常波动变化的,所以「超时重传时间 RTO 的值」应该是一个动态变化的值。
估计往返时间,通常需要采样以下两个:
- 需要 TCP 通过采样 RTT 的时间,然后进行加权平均,算出一个平滑 RTT 的值,而且这个值还是要不断变化的,因为网络状况不断地变化。
- 除了采样 RTT,还要采样 RTT 的波动范围,这样就避免如果 RTT 有一个大的波动的话,很难被发现的情况。
RFC6289 建议使用以下的公式计算 RTO:

在 Linux 下,α = 0.125,β = 0.25, μ = 1,∂ = 4。别问怎么来的,问就是大量实验中调出来的。
如果超时重发的数据,再次超时的时候,又需要重传的时候,TCP 的策略是超时间隔加倍。
快速重传
- Seq2 因为某些原因没收到,Seq3 先到达了,于是还是 Ack 回 2;
- 后面的 Seq4 和 Seq5 都到了,但还是 Ack 回 2,因为 Seq2 还是没有收到;

快速重传的工作方式是当收到三个相同的 ACK 报文时,会在定时器过期之前,重传丢失的报文段。
快速重传机制只解决了一个问题,就是超时时间的问题,但是它依然面临着另外一个问题。就是重传的时候,是重传一个,还是重传所有的问题。
举个例子,假设发送方发了 6 个数据,编号的顺序是 Seq1 ~ Seq6 ,但是 Seq2、Seq3 都丢失了,那么接收方在收到 Seq4、Seq5、Seq6 时,都是回复 ACK2 给发送方,但是发送方并不清楚这连续的 ACK2 是接收方收到哪个报文而回复的。 那是选择重传 Seq2 一个报文,还是重传 Seq2 之后已发送的所有报文呢(Seq2、Seq3、 Seq4、Seq5、 Seq6) 呢?
-
如果只选择重传 Seq2 一个报文,那么重传的效率很低。因为对于丢失的 Seq3 报文,还得在后续收到三个重复的 ACK3 才能触发重传。
-
如果选择重传 Seq2 之后已发送的所有报文,虽然能同时重传已丢失的 Seq2 和 Seq3 报文,但是 Seq4、Seq5、Seq6 的报文是已经被接收过了,对于重传 Seq4 ~Seq6 折部分数据相当于做了一次无用功,浪费资源。
可以看到,不管是重传一个报文,还是重传已发送的报文,都存在问题。
为了解决不知道该重传哪些 TCP 报文,于是就有 SACK 方法。
SACK 方法( Selective Acknowledgment, 选择性确认)
如果要支持 SACK,必须双方都要支持。在 Linux 下,可以通过 net.ipv4.tcp_sack 参数打开这个功能(Linux 2.4 后默认打开)。
这种方式需要在 TCP 头部「选项」字段里加一个 SACK 的东西,它可以将已收到的数据的信息发送给「发送方」,这样发送方就可以知道哪些数据收到了,哪些数据没收到,知道了这些信息,就可以只重传丢失的数据。

Duplicate SACK (D SACK)
Duplicate SACK 又称 D-SACK,其主要使用了 SACK 来告诉「发送方」有哪些数据被重复接收了。
在 Linux 下可以通过 net.ipv4.tcp_dsack 参数开启/关闭这个功能(Linux 2.4 后默认打开)。
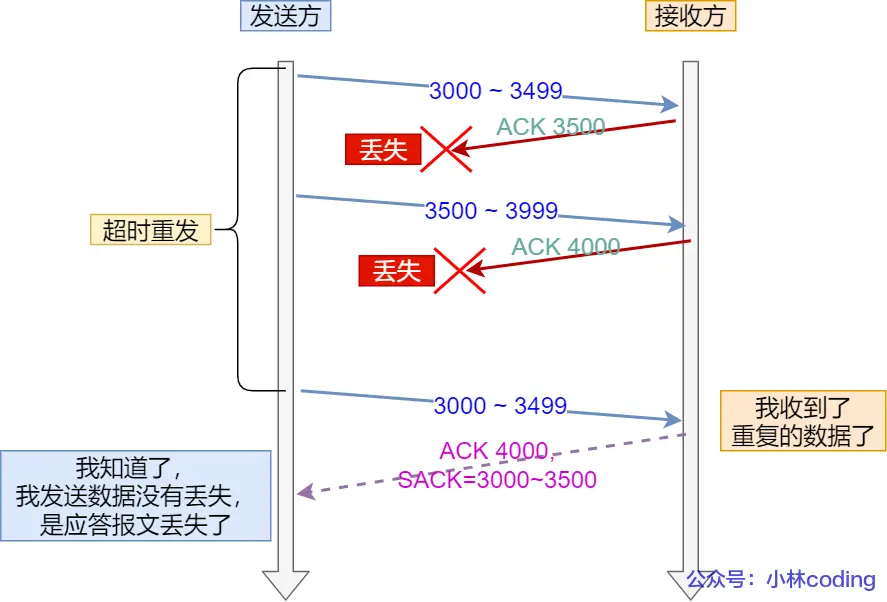
例子一:ACK 丢包 导致重复接收
ack 丢失,导致发送方超时重传,导致接收方重复接收
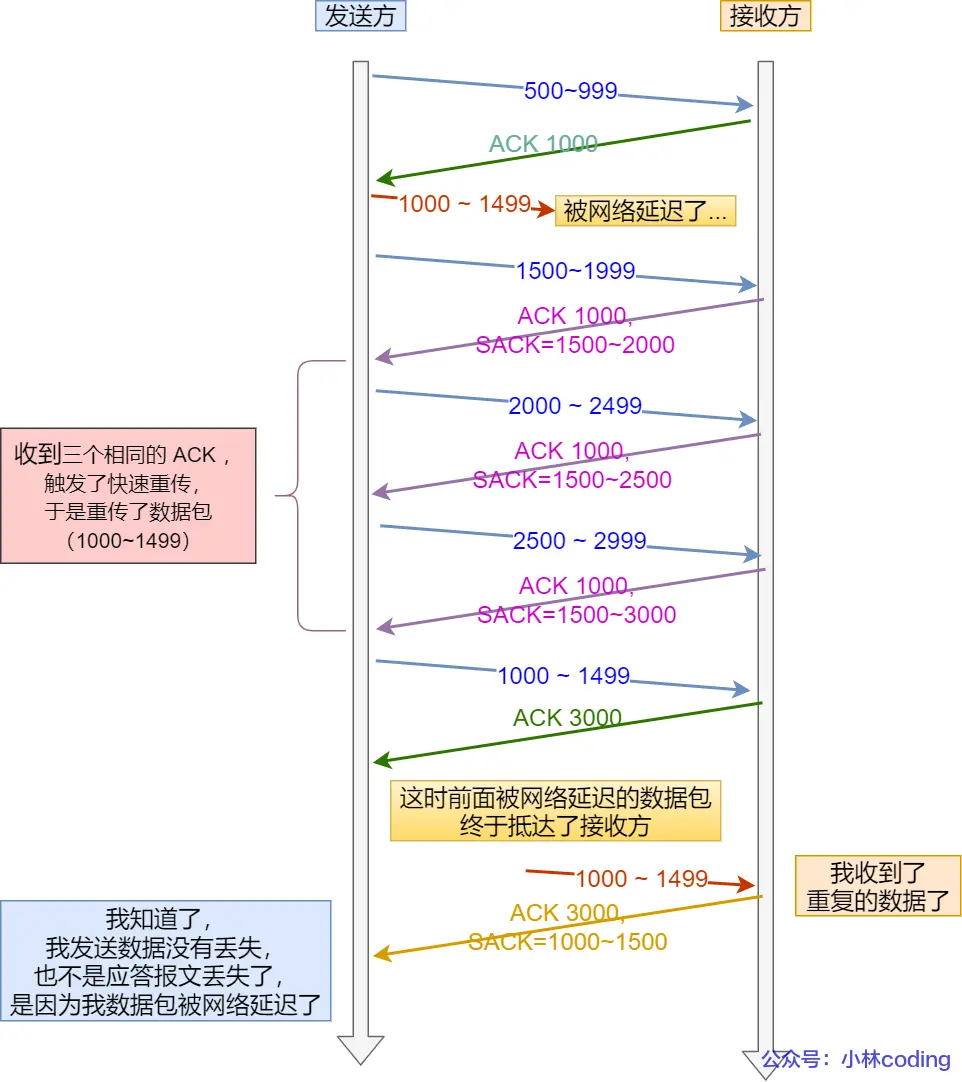
例子二:网络延时 导致重复接收
发送方的上一个包被网络延时,下一个包比它早到达,接收方快速重传后发送方重发,重发完了网络延时的那个包又到了。导致接收方重复接收。
可见,D-SACK 有这么几个好处:
- 可以让「发送方」知道,是发出去的包丢了,还是接收方回应的 ACK 包丢了;
- 可以知道是不是「发送方」的数据包被网络延迟了;
- 可以知道网络中是不是把「发送方」的数据包给复制了;
滑动窗口
引入原因
我们都知道 TCP 是每发送一个数据,都要进行一次确认应答。当上一个数据包收到了应答了, 再发送下一个。
这样的传输方式有一个缺点:数据包的往返时间越长,通信的效率就越低。
为解决这个问题,TCP 引入了窗口这个概念。那么有了窗口,就可以指定窗口大小,窗口大小就是指无需等待ACK确认应答,而可以继续发送数据的最大值。
假设窗口大小为 3 个 TCP 段,那么发送方就可以「连续发送」 3 个 TCP 段,并且中途若有 ACK 丢失,可以通过「下一个确认应答进行确认」。如下图:
- 图中的 ACK 600 确认应答报文丢失,也没关系,因为可以通过下一个确认应答进行确认,只要发送方收到了 ACK 700 确认应答,就意味着 700 之前的所有数据「接收方」都收到了。这个模式就叫累计确认或者累计应答。


窗口大小由哪一方决定?
TCP 头里有一个字段叫 Window,也就是窗口大小。
这个字段是接收端告诉发送端自己还有多少缓冲区可以接收数据。于是发送端就可以根据这个接收端的处理能力来发送数据,而不会导致接收端处理不过来。
所以,通常窗口的大小是由接收方的窗口大小来决定的。
发送方的滑动窗口
已发送但是还未收到ACK确认的数据会占据滑动窗口的大小

在下图,当发送方把数据「全部」都一下发送出去后,可用窗口的大小就为 0 了,表明可用窗口耗尽,在没收到 ACK 确认之前是无法继续发送数据了。

在下图,当收到之前发送的数据 32~36 字节的 ACK 确认应答后,如果发送窗口的大小没有变化,则滑动窗口往右边移动 5 个字节,因为有 5 个字节的数据被应答确认,接下来 52~56 字节又变成了可用窗口,那么后续也就可以发送 52~56 这 5 个字节的数据了。

TCP 滑动窗口方案使用三个指针来跟踪在四个传输类别中的每一个类别中的字节。其中两个指针是绝对指针(指特定的序列号),一个是相对指针(需要做偏移)。
(1) SND.UNA 滑动窗口起始(绿蓝交界)(2)SNA.NEXT 未发送部分的起始(蓝黄交界)(3)SND.WND 发送窗口大小(蓝色+黄色 的宽度)
可用窗口大小 = SND.WND -(SND.NXT - SND.UNA)
接收方滑动窗口
窗口内的数据是一致的
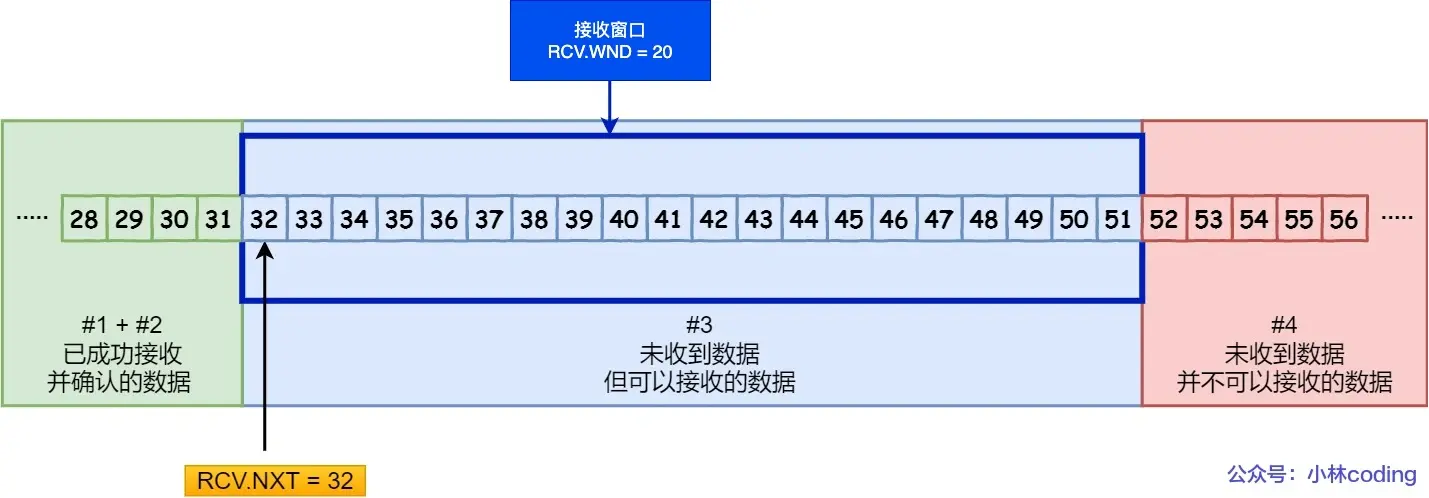
(1)RCV.WND 接收窗口大小(蓝色宽度)(2)RCV.NXT 接收窗口起始(绿蓝交界)
接收窗口和发送窗口的大小是相等的吗?
并不是完全相等,接收窗口的大小是约等于发送窗口的大小的。
因为滑动窗口并不是一成不变的。比如,当接收方的应用进程读取数据的速度非常快的话,这样的话接收窗口可以很快的就空缺出来。那么新的接收窗口大小,是通过 TCP 报文中的 Windows 字段来告诉发送方。那么这个传输过程是存在时延的,所以接收窗口和发送窗口是约等于的关系。
流量控制
发送方不能无脑的发数据给接收方,要考虑接收方处理能力。
如果一直无脑的发数据给对方,但对方处理不过来,那么就会导致触发重发机制(接收方不能及时回复 ACK),从而导致网络流量的无端的浪费。
为了解决这种现象发生,TCP 提供一种机制可以让「发送方」根据「接收方」的实际接收能力控制发送的数据量,这就是所谓的流量控制。