通过前面的学习,相信你已经见识到了 Kubernetes 的强大能力,它能帮你轻松管理大规模的容器服务,尤其是面对复杂的环境时,比如节点异常、容器异常退出等,Kubernetes 内部的 Service、Deployment 会动态地进行调整,比如增加新的副本、关联新的 Pod 等。
当然 Kubernetes 的这种自动伸缩能力可不止于此。
我们今天就来看看如果利用这些伸缩能力,帮我们在应对大促这样的大流量活动时,控制业务的资源水位,以提供稳定的服务,避免容器的负载过高被打爆,出现流量下跌、业务抖动等情况,从而引发业务故障。
Pod 水平自动伸缩(Horizontal Pod Autoscaler,HPA)
一般来说,我们在遇到这种大流量的场景时,映入我们脑海中的一个想法就是水平扩展,即增加一些实例来分担流量压力。像 Deployment 这种支持多副本的工作负载,我们就可以通过调整spec.replicas来增加或减少副本数,从而改变整体的业务水位满足我们的需求,即整体负载高时就增加一些实例,负载低就适当减少一些实例来节省资源。
当然人为不断地调整spec.replicas的数值显然是不太现实的,HPA可以根据应用的 CPU 利用率等水位信息,动态地增加或者减少 Pod 副本数量,帮你自动化地完成这一调和过程。
HPA 大多数是用来自动扩缩(Scale)一些无状态的应用负载,比如 Deployment,或者你自己定义的其他类型的无状态工作负载。当然你也可以用来扩缩有状态的应用负载,比如 StatefulSet。
我们来看下面这张图,它描述了 HPA 通过动态地调整Deployment的副本数,从而控制 Pod 的数量。
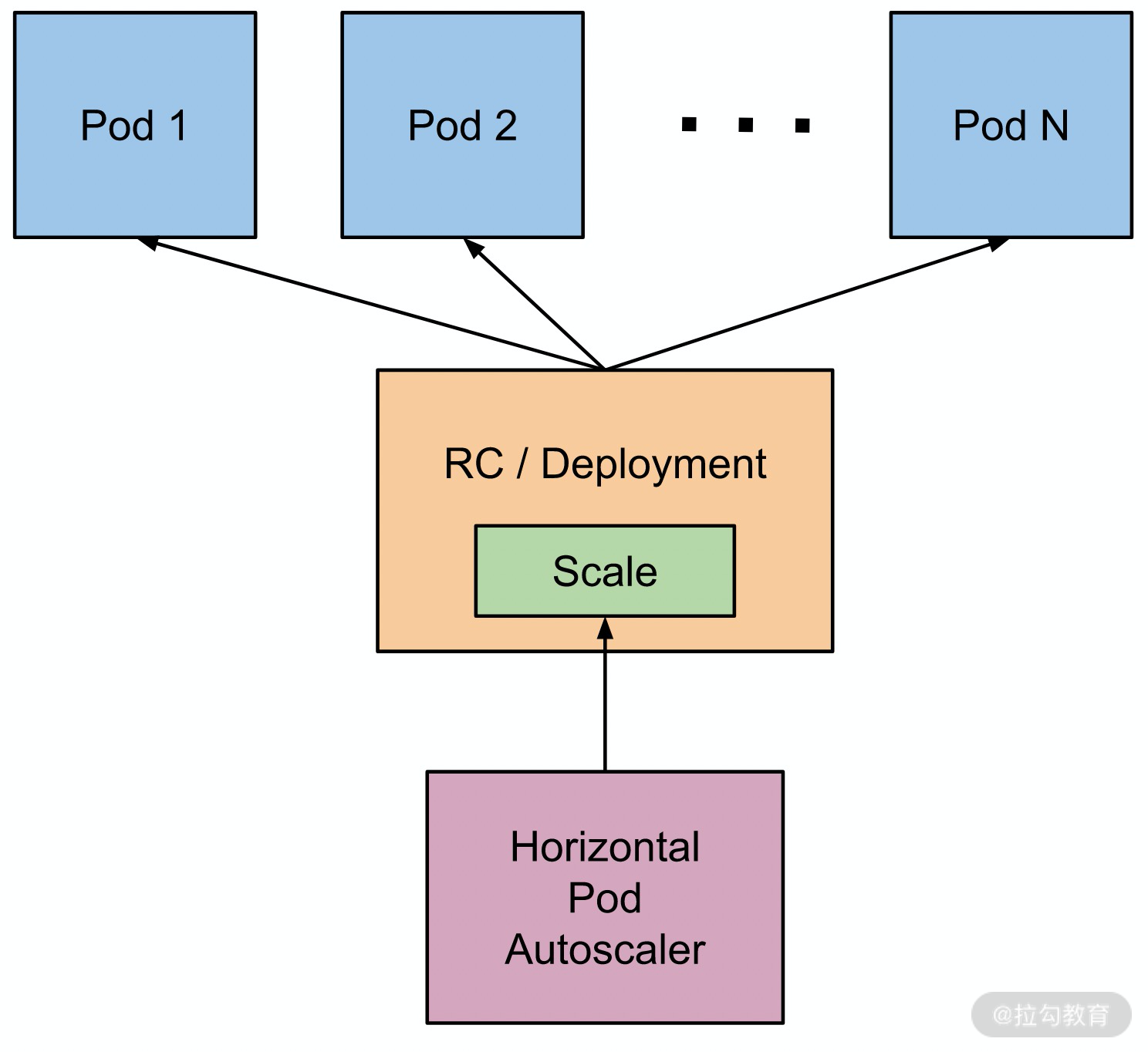
(https://github.com/kubernetes/website/blob/master/static/images/docs/horizontal-pod-autoscaler.png)
{kind=link}
在使用 HPA 的时候,你需要提前部署好 metrics-server,可以通过 kubectl apply -f一键部署完成(如果你想了解更多关于 metrics-server 的部署,可以参考官方文档)。
$ kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.3.7/components.yaml
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
serviceaccount/metrics-server created
deployment.apps/metrics-server created
service/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
我们来查看下metrics-server对应的 Deployment 的状态,如下图它已经处于 Ready 状态。
kubectl get deploy -n kube-system metrics-server
NAME READY UP-TO-DATE AVAILABLE AGE
metrics-server 1/1 1 1 26s
你可以通过kubectl logs来查看对应 Pod 的日志,来确定其是否正常工作。如果有异常,可以参考这里调整部署参数。
现在我们来看看如何来使用 HPA。
首先我们部署一个 Deployment,其 YAML 配置如下(你可以保存为nginx-deploy-hpa.yaml文件):
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
namespace: demo
spec:
selector:
matchLabels:
app: nginx
usage: hpa
replicas: 1
template:
metadata:
labels:
app: nginx
usage: hpa
spec:
containers:
- name: nginx
image: nginx:1.19.2
ports:
- containerPort: 80
resources:
requests: # 这里我们把quota设置得小一点,方便做压力测试
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
下面我们通过 kubectl 来创建这个 Deployment:
$ kubectl create -f nginx-deploy-hpa.yaml
deployment.apps/nginx-deployment created
现在我们来查看一下该 Deployment 的状态,通过下面几条命令可以看到它已经 ready :
$ kubectl get deploy -n demo
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 1/1 1 1 4s
$ kubectl get pod -n demo
NAME READY STATUS RESTARTS AGE
nginx-deployment-6d4b885966-zngnd 1/1 Running 0 8s
可以看到,我们创建的 Deployment 运行成功。
现在我们来创建一个 Service ,来关联这个 Deployment,我们后续就可以通过这个 Service 来访问 Deployment 的各个 Pod 实例了。通过如下命令,我们就可以快速创建一个对应的 Service 出来,当然你也可以通过 YAML 文件来创建。
$ kubectl expose deployment/nginx-deployment -n demo
service/nginx-deployment exposed
我们用kubectl get来查看一下这个 Service 和对应的 Endpoints 对象:
$ kubectl get svc -n demo
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx-deployment ClusterIP 10.109.93.199 <none> 80/TCP 4s
$ kubectl get endpoints -n demo
NAME ENDPOINTS AGE
nginx-deployment 10.1.0.163:80,10.1.0.164:80 12s
后面我们就可以通过访问这个 Service 的10.109.93.199地址来访问该服务。
现在我们来创建一个 HPA 对象。通过kubectl autoscale的命令,我们就可以将 Deployment 的副本数控制在 1~10 之间,CPU 利用率保持在 50% 以下,即当该 Deployment 所关联的 Pod 的平均 CPU 利用率超过 50% 时,就增加副本数,直到小于该阈值。当平均 CPU 利用率低于 50% 时,就减少副本数:
$ kubectl autoscale deploy nginx-deployment -n demo --cpu-percent=50 --min=1 --max=10
horizontalpodautoscaler.autoscaling/nginx-deployment autoscaled
我们来查看一下刚才创建出来的 HPA 对象:
$ kubectl get hpa -n demo
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx-deployment Deployment/nginx-deployment 0%/50% 1 10 0 6s
在 kube-controller-manager 中有对应的 HPAController 负责算出合适的副本数,它会根据 metrics-server 上报的对应 Pod metrics 进行计算,具体的算法细节可以通过官方文档来了解。
好了,到现在,一切准备就绪,我们开始见证 HPA 的魔力!
我们现在新开两个终端,分别运行命令kubectl get deploy -n demo -w和kubectl get hpa -n demo -w来观察其状态变化。
现在创建一个 Pod 来增加上面 Nginx 服务的访问压力。这里我们用压测工具ApacheBench 进行压力测试看看:
$ kubectl run demo-benchmark --image httpd:2.4.46-alpine -n demo -it sh
/usr/local/apache2 # ab -n 50000 -c 500 -s 60 http://10.109.93.199/
This is ApacheBench, Version 2.3 <$Revision: 1879490 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 10.109.93.199 (be patient)
Completed 5000 requests
Completed 10000 requests
Completed 15000 requests
Completed 20000 requests
Completed 25000 requests
Completed 30000 requests
Completed 35000 requests
Completed 40000 requests
Completed 45000 requests
Completed 50000 requests
Finished 50000 requests
Server Software: nginx/1.19.2
Server Hostname: 10.109.93.199
Server Port: 80
Document Path: /
Document Length: 612 bytes
Concurrency Level: 500
Time taken for tests: 74.783 seconds
Complete requests: 50000
Failed requests: 2
(Connect: 0, Receive: 0, Length: 1, Exceptions: 1)
Total transferred: 42250000 bytes
HTML transferred: 30600000 bytes
Requests per second: 668.60 [#/sec] (mean)
Time per request: 747.830 [ms] (mean)
Time per request: 1.496 [ms] (mean, across all concurrent requests)
Transfer rate: 551.73 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 95 347.7 10 3134
Processing: 9 49 295.1 33 60048
Waiting: 5 44 122.8 30 3393
Total: 19 144 477.2 50 60048
Percentage of the requests served within a certain time (ms)
50% 50
66% 61
75% 65
80% 69
90% 83
95% 1071
98% 1143
99% 1946
100% 60048 (longest request)
在上述 ab 命令运行的同时,我们可以切回之前打开的两个终端窗口看看输出信息:
$ kubectl get hpa -n demo -w
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx-deployment Deployment/nginx-deployment 0%/50% 1 10 1 48m
nginx-deployment Deployment/nginx-deployment 125%/50% 1 10 1 50m
nginx-deployment Deployment/nginx-deployment 125%/50% 1 10 3 50m
nginx-deployment Deployment/nginx-deployment 0%/50% 1 10 3 51m
nginx-deployment Deployment/nginx-deployment 0%/50% 1 10 3 56m
nginx-deployment Deployment/nginx-deployment 0%/50% 1 10 1 56m
$ kubectl get deploy -n demo -w
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 1/1 1 1 48m
nginx-deployment 1/3 1 1 50m
nginx-deployment 1/3 1 1 50m
nginx-deployment 1/3 1 1 50m
nginx-deployment 1/3 3 1 50m
nginx-deployment 2/3 3 2 50m
nginx-deployment 3/3 3 3 50m
nginx-deployment 3/1 3 3 56m
nginx-deployment 3/1 3 3 56m
nginx-deployment 1/1 1 1 56m
可以看到,随着访问压力的增加,Pod 的平均利用率也直线上升,一度达到了 125%,超过我们的阈值 50%。这个时候,Deployment 的副本数被调整到了 3,随之 2 个新 Pod 被拉起,负载很快降到了 50% 以下。而后随着压测结束,HPA 又将 Deployment 调整为了 1,维持在低水位。
我们现在回过头来看看 metrics-server 创建的对象PodMetrics:
$ kubectl get podmetrics -n demo
NAME AGE
nginx-deployment-6d4b885966-zngnd 0s
nginx-deployment-6d4b885966-lgwd9 0s
nginx-deployment-6d4b885966-hhk7v 0s
$ kubectl get podmetrics -n demo nginx-deployment-6d4b885966-zngnd -o yaml
apiVersion: metrics.k8s.io/v1beta1
containers:
- name: nginx
usage:
cpu: "0"
memory: 5524Ki
kind: PodMetrics
metadata:
creationTimestamp: "2020-10-13T09:38:15Z"
name: nginx-deployment-6d4b885966-zngnd
namespace: demo
selfLink: /apis/metrics.k8s.io/v1beta1/namespaces/demo/pods/nginx-deployment-6d4b885966-zngnd
timestamp: "2020-10-13T09:37:55Z"
HPAController 就是通过这些 PodMetrics 来计算平均的 CPU 使用率,从而确定 spec.replicas 的新数值。
除了 CPU 以外,HPA 还支持其他自定义度量指标,有兴趣可以参考官方文档。
HPA 能够自适应地伸缩 Pod 的数目,但是如果集群中资源不够了怎么办?比如节点紧张无法支撑新的 Pod 运行?
这个时候我们就可以添加新的节点资源到集群中,那么有没有类似 HPA 的做法可以自动化地扩容集群的节点资源?
当然是有的!我们来看看 Cluster Autoscaler。
Cluster Autoscaler
Cluster Autoscaler(下文统称 CA)目前对接了阿里云、AWS、Azure、百度云、华为云、Openstack等云厂商,你可以参照各个厂商的部署要求,进行部署。在部署的时候,请注意 CA 和 Kubernetes 版本要对应,最好两者版本一样。
这里描述了 CA 和 HPA 一起使用的情形。两者一般可以配合起来一起使用。
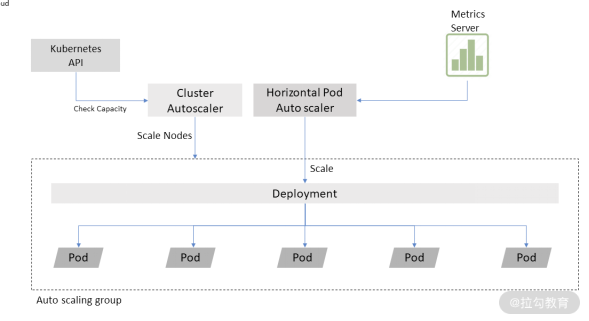
我们来看看 CA 是如何工作的。CA 主要用来监听(watch)集群中未被调度的 Pod (即 Pod 暂时由于某些调度策略、抑或资源不满足,导致无法被成功调度),然后确定是否可以通过增加节点资源来解决无法调度的问题。
如果可以的话,就会调用对应的 cloud provider 接口,向集群中增加新的节点。当然 CA 在创建新的节点资源前,也会尝试是否可以将正在运行的一部分 Pod “挤压”到某些节点上,从而让这些未被调度的 Pod 可以被调度,如果可行的话,CA 会将这些 Pod 进行驱逐。这些被驱逐的 Pod 会被重新调度(reschedule)到其他的节点上。我们会在后续调度章节来深入讨论有关 Pod 驱逐的话题。
目前 CA 仅支持部分云厂商,如果不满足你的需求,你可以考虑基于社区的代码进行二次开发,链接中有详细说明我就不赘述了。
写在最后
除了 HPA 和 CA 以外,还有 Vertical Pod Autoscaler (VPA)可以帮我们确定 Pod 中合适的 CPU 和 Memory 区间,有兴趣可以了解下。限于篇幅,本节不多做介绍。在实际使用的时候,注意千万不要同时使用 HPA 和 VPA,以免造成异常。
使用 HPA 的时候,也尽量对 Deployment 这类对象进行操作,避免对 ReplicaSet 操作。毕竟 ReplicaSet 由 Deployment 管理着,一旦 Deployment 更新了,旧的ReplicaSet 会被新的 ReplicaSet 替换掉。
这节课到这里就结束了,如果你有什么想法或者疑问,欢迎你在留言区留言,我们一起讨论。