chapter3
多任务处理
一般来说,多任务处理指的是同时进行几项独立活动的能力。在计算机技术中,多任务处理指的是同时执行几个独立的任务。在单处理器(单CPU)系统中,一次只能执行一个任务。多任务处理是通过在不同任务之间多路复用CPU的执行时间来实现的,即将CPU执行操作从一个任务切换到另一个任务。不同任务之间的执行切换机制称为上下文切换,将一个任务的执行环境更改为另一个任务的执行环境。如果切换速度足够快,就会给人一种同时执行所有任务的错觉。这种逻辑并行性称为“并发”。在有多个CPU或处理器内核的多处理器系统中,可在不同CPU上实时、并行执行多项任务。此外,每个处理器也可以通过同时执行不同的任务来实现多任务处理。多任务处理是所有操作系统的基础。总体上说,它也是并行编程的基础。
进程的概念
操作系统是一个多任务处理系统。在操作系统中,任务也称为进程。在实际应用中,任务和进程这两个术语可以互换使用。
进程的正式定义:进程是对映像的执行。
操作系统内核将一系列执行视为使用系统资源的单一实体。系统资源包括内存空间、I/O设备以及最重要的CPU时间。在操作系统内核中,每个进程用一个独特的数据结构表示,叫作进程控制块(PCB)或任务控制块(TCB)等。可以直接称它为PROC结构体。与包含某个人所有信息的个人记录一样,PROC结构体包含某个进程的所有信息。在实际操作系统中,PROC结构体可能包含许多字段,而且数量可能很庞大。首先,可以定义一个非常简单的PROC结构体来表示进程。
typedef struct proc{
struct proc *next; //next proc pointer
int *ksp; //saved sp: at byte offset 4
int pid; //process ID
int ppid; //parent process pid
int status; //PROC status=FREE|READY,etc.
int priority; //scheduling priority
int kstack[1024]; //process execution stack
}PROC;
在PROC结构体中,next是指向下一个PROC结构体的指针,用于在各种动态数据结构(如链表和队列)中维护PROC结构体。ksp字段是保存的堆栈指针。当某进程放弃使用CPU时,它会将执行上下文保存在堆栈中,并将堆栈指针保存在PROC.ksp中,以便以后恢复。在PROC结构体的其他字段中,pid是标识一个进程的进程ID编号,ppid是父进程ID编号,status是进程的当前状态,priority是进程调度优先级,kstack是进程执行时的堆栈。操作系统内核通常会在其数据区中定义有限数量的PROC结构体,表示为:
PROC proc[NPROC]; //NPROC a constant, e.g. 64
用来表示系统中的进程。在一个单CPU系统中,一次只能执行一个进程。操作系统内核通常会使用正在运行的或当前的全局变量PROC指针,指向当前正在执行的PROC。在有多个CPU的多处理器操作系统中,可在不同CPU上实时、并行执行多个进程。因此,在一个多处理器系统中正在运行的[NCPU]可能是一个指针数组,每个指针指向一个正在特定CPU上运行的进程。为简便起见,只考虑单CPU系统。
多任务处理系统
type.h文件:定义系统常数和表示进程的简单PROC结构体。在扩展MT系统时,应向PROC结构体添加更多的字段。
ts.s文件:ts.s在32位GCC汇编代码中可实现进程上下文切换。
queue.c文件:可实现队列和链表操作函数。enqueue()函数按优先级将PROC输入队列中。在优先级队列中,具有相同优先级的进程按先进先出(FIFO)的顺序排列。dequeue()函数可返回从队列或链表中删除的第一个元素。printList()函数可打印链表元素。
t.c文件:定义MT系统数据结构、系统初始化代码和进程管理函数。
多任务处理系统代码
MT系统的基本代码如下。
(1)虚拟CPU:MT系统在Linux下编译链接为
gcc -m32 t.c ts.s
然后运行a.out。整个MT系统在用户模式下作为Linux进程运行。在Linux进程中,创建了多个独立执行实体(叫作任务),并通过自己的调度算法将它们调度到Linux进程中运行。对于MT系统中的任务,Linux进程就像一个虚拟CPU。为避免混淆,将MT系统中的执行实体叫作任务或进程。
(2)init():当MT系统启动时,main()函数调用init()以初始化系统。init()初始化PROC结构体,并将它们输入freeList中。它还将readyQueue初始化为空。然后使用proc[0]创建P0,作为初始运行进程。P0的优先级最低,为0。所有其他任务的优先级都是1,因此它们将轮流从readyQueue运行。
(3)P0调用kfork()来创建优先级为1的子进程P1,并将其输入就绪队列中。然后P0调用tswitch(),将会切换任务以运行P1。
(4)tswitch():tswitch()函数实现进程上下文切换。它就像一个进程交换箱,一个进程进入时通常另一个进程会出现。tswitch()由3个独立的步骤组成,下面是详细的步骤说明。
(4a)tswitch()中的SAVE函数:当正在执行的某个任务调用tswitch()时,它会把返回地址保存在堆栈上,并在汇编代码中进入tswitch()。在tswitch()中,SAVE 函数将CPU寄存器保存到调用任务的堆栈中,并将堆栈指针保存到proc.ksp中。32位Intel x86 CPU有许多寄存器,但在用户模式下,只有eax、ebx、ecx、edx ,ebp、esi、edi和eflag对Linux进程可见,它是MT系统的虚拟CPU。因此,我们只需要保存和恢复虚拟CPU的这些寄存器。下面显示了在执行tswitch()的SAVE函数后,调用任务的堆栈内容和保存的堆栈指针,其中xxx表示调用tswitch()之前的堆栈内容。
proc.ksp
|
|xxx|retPC|eax|ebx|ecx|edx|ebp|esi|edi|eflag|
在基于Intel x86的32位PC中,每个CPU寄存器的宽度为4字节,堆栈操作始终以4字节为单位。因此,可以将PROC结构体中的每个PROC堆栈定义为一个整数数组。
(4b)scheduler():在执行了tswitch()中的SAVE函数之后,任务调用scheduler()来选择下一个正在运行的任务。在scheduler()中,如果调用任务仍然可以运行,则会调用enqueue()将自己按优先级放入readyQueue中。否则,它不会在readyQueue中,因此也就无法运行。然后,它会调用dequeue(),将从readyQueue中删除的第一个PROC作为新的运行任务返回。
(4c)tswitch()中的RESUME函数:当执行从scheduler()返回时,“运行”可能已经转而指向另一个任务的PROC。运行指向的那个PROC,就是当前正在运行的任务。tswitch()中的RESUME函数将CPU的堆栈指针设置为当前运行任务的已保存堆栈指针。然后弹出保存的寄存器,接着是弹出RET,使当前运行的任务返回到之前调用tswitch()的位置。
(5)kfork():kfork()函数创建一个子任务并将其输入readyQueue中。每个新创建的任务都从同一个body()函数开始执行。虽然新任务以前从未存在过,但可以假装它不仅存在过,而且运行过。它现在不运行是因为它调用了tswitch(),所以提前放弃了使用CPU。如果是这样的话,它的堆栈必须包含tswitch()中的SAVE函数保存的一个帧,而且它保存的ksp必须指向栈顶。由于新任务之前从未真正运行过,所以可以假设它的堆栈为空,而且当它调用tswitch()时,所有CPU寄存器内容都是0。因此,在kfork()中,按以下方法初始化新任务的堆栈。
proc.ksp
|
|< - all saved registers = 0 ->|
|body|eax|ecx|edx|ebx|ebp|esi|edi|eflags|
-1 -2 -3 -4 -5 -6 -7 -8 -9
这里的索引-i意味着SSIZE-i.这是通过kfork()中的以下代码段来实现的。
/************ task initial stack contents ************
kstack contains: |retPC|eax|ebx|ecx|edx|ebp|esi|edi|eflag|
-1 -2 -3 -4 -5 -6 -7 -8 -9
*****************************************************/
for(i=1; i<10; i++) //zero out kstack cells
p->kstack[SSIZE-i]=0;
p->kstack[SSIZE-1] = (int)body; //retPC -> body()
p->ksp = &(p->kstack[SSIZE-9]); //PROC.ksp -> saved eflag
当新任务开始运行时,它首先执行tswitch()中的RESUME函数,使它返回body()函数的输人地址。逻辑上,当执行首次进入body()函数时,任务堆栈为空。一旦执行开始,任务的堆栈就会增长和收缩。实际上,body()函数从不返回,因此在堆栈中不需要有一个返回地址。
(6)body():为便于说明,所有创建的任务都执行同一个body()函数。这说明了进程和程序之间的区别。多个进程可执行同一个程序代码,但是每个进程都只能在自己的上下文中执行。例如,body()中的所有(自动)局部变量都供进程专用,因为它们都是在每个进程堆栈中分配的。如果body()函数调用其他函数,则所有调用序列都会保存在每个进程堆栈中,等等。在body()中执行时,进程提示输入char = [f|s|q]命令,其中:
- f:kfork一个新的子进程来执行body()
- s:切换进程
- q:终止进程,并将进程以freeList中的FREE函数的形式返回
(7)空闲任务P0:P0的特殊之处在于它在所有任务中具有最低的优先级。在系统初始化之后,P0创建P1并切换到运行P1。当且仅当没有可运行任务时,P0将会再次运行。在这种情况下,P0会一直循环。当readyQueue变为非空时,它将切换到另一个任务。在基本MT系统中,如果所有其他进程都已终止,则P0将会再次运行。要想结束MT系统,用户可按下“Ctrl+C”组合键来终止Linux进程。
(8)运行多任务处理(MT)系统:在Linux下,输入:
gcc -m32 t.c s.s
编译链接MT系统并运行所得到的a.out。
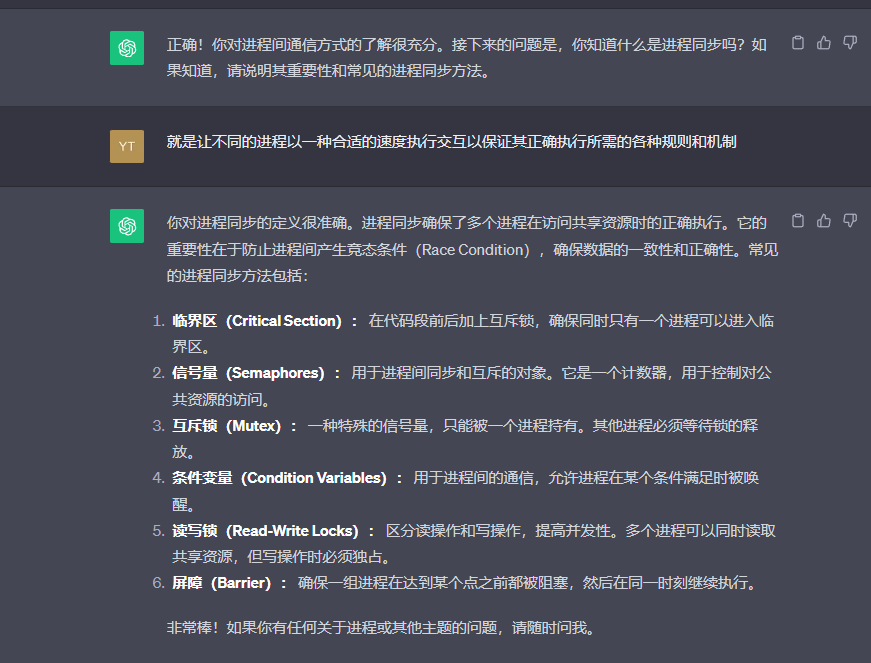
进程同步
一个操作系统包含许多并发进程,这些进程可以彼此交互。进程同步是指控制和协调进程交互以确保其正确执行所需的各项规则和机制。最简单的进程同步工具是休眠和唤醒操作。
睡眠模式
当某进程需要某些当前没有的东西时,例如申请独占一个存储区域、等待用户通过标准输入来输入字符等,它就会在某个事件值上进入休眠状态,该事件值表示休眠的原因。为实现休眠操作,可在PROC结构体中添加一个event字段,并实现ksieep(int event)函数,使进程进入休眠状态。
typedef struct proc{
struct proc *next; //next proc pointer
int *ksp; //saved sp: at byte offset 4
int pid; //process ID
int ppid; //parent process pid
int status; //PROC status=FREE|READY,etc.
int priority; //scheduling priority
int event; //event value to sleep on
int exitCode; //exit value
struct proc *child; //first child PROC pointer
struct proc *sibling; //sibling PROC pointer
struct proc *parent; //parent PROC pointer
int kstack[1024]; //process stack
}PROC;
ksleep()的算法如下。

由于休眠进程不在readyQueue中,所以它在被另一个进程唤醒之前不可运行。因此,在让自己进入休眠状态之后,进程调用tswitch()来放弃使用CPU。
唤醒操作
多个进程可能会进入休眠状态等待同一个事件,这是很自然的,因为这些进程可能都需要同一个资源,例如一台当前正处于繁忙状态的打印机。在这种情况下,所有这些进程都将休眠等待同一个事件值。当某个等待时间发生时,另一个执行实体(可能是某个进程或中断处理程序)将会调用kwakeup(event),唤醒正处于休眠状态等待该事件值的所有程序。如果没有任何程序休眠等待该程序,kwakeup()就不工作,即不执行任何操作。
kwakeup()的算法如下。

被唤醒的进程可能不会立即运行。它只是被放入readyQueue中,排队等待运行。当被唤醒的进程运行时,如果它在休眠之前正在试图获取资源,那么它必须尝试重新获取资源。因为该资源在它运行时可能不再可用。ksleep()和kwakeup()函数一般用于进程同步,但在特殊情况下也用于同步父进程和子进程。
进程终止
在操作系统中,进程可能终止或死亡,这是进程终止的通俗说法。进程能以两种方式终止:
- 正常终止:进程调用exit(value),发出_exit(value)系统调用来执行在操作系统内核中的kexit(value)。
- 异常终止:进程因某个信号而异常终止。
在这两种情况下,当进程终止时,最终都会在操作系统内核中调用kexit()。
kexit()算法

MT系统中的所有进程都以操作系统(OS)模拟内核模式运行。因此,它们没有任何用户模式上下文。首先来讨论kexit()的步骤2。在某些操作系统中,某个进程的执行环境可能依赖于其父进程的执行环境。例如,子进程的存储区可能在父进程的存储区内,因此除非父进程的所有子进程都已死亡,否则父进程不会死亡。在Unix/Linux中,进程只有非常松散的父子关系,它们的执行环境都是独立的。因此,在Unix/Linux中,进程可能随时死亡。如果有子进程的某个父进程首先死亡,那么所有子进程将不再有父进程,即成为孤儿进程。那么如何处理这些孤儿进程呢?如果没有其他进程存在,那么肯定有一个进程不会死亡。否则,父进程与子进程的关系很快就会瓦解。在所有类Unix系统中,进程P1(又叫作INIT进程)被选来扮演这个角色。当某个进程死亡时,它将其所有的孤儿子进程,不论死亡还是活跃,都送到P1中,即成为P1的子进程。同样,我们也要将MT系统中的P1指定为这类进程。因此,如果还有其他进程存在,P1就不应该消失。剩下的问题是如何有效地实现kexit()的步骤2。为了让一个濒死进程处理孤儿子进程,该进程必须能够确定它是否有子进程,如果有,则必须快速找到所有的子进程。如果进程的数量很少,例如像MT系统一样只有几个进程,通过搜索所有PROC结构体可以有效地回答这两个问题。例如,要确定某个进程是否有任何子进程,只需在PROC中搜索任何非空闲进程,并且搜索到的进程的ppid与前面进程的pid匹配即可。如果进程的数量很大,例如有数百甚至数千个进程,这种简单的搜索方案就会慢得让人难以忍受。因此,大多数大型操作系统内核通过维护进程家族树来跟踪进程关系。
进程家族树
通常,进程家族树通过个PROC结构中的一对子进程和兄弟进程指针以二叉树的形式实现,如:
PROC *child,*sibling,*parent;
其中,child指向进程的第一个子进程,sibling指向同一个父进程的其他子进程。为方便起见,每个PROC还使用一个parent指针指向其父进程。例如,下图左侧所示的进程树可以实现为右侧所示的二叉树,其中每个垂直链接都是child指针,每个水平链接都是sibling指针。清晰起见,图中没有显示parent指针和空指针。
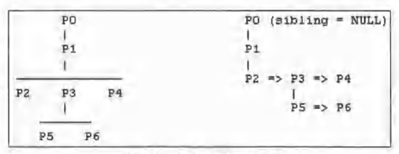
使用进程树,更容易找到进程的子进程。首先,跟随child指针到第一个子进程。然后,跟随sibling指针遍历兄弟进程。要想把所有子进程都送到P1中,只需要把子进程链表分出来,然后把它附加到P1的子进程链表中(还要修改它们的ppid和parent指针)。
每个PROC都有一个退出代码(exitCode)字段,是进程终止时的进程退出值(exitValue)。在PROC.exitCode中记录exitValue之后,进程状态更改为ZOMBIE,但不释放PROC结构体。然后,进程调用kwakeup(event)来唤醒其父进程,其中事件必须是父进程和子进程使用的相同唯一值,例如父进程的PROC结构体地址或父进程的pid。如果它将任何孤儿进程送到P1中,也会唤醒P1。濒死进程的最后操作是进程最后一次调用tswitch()。在这之后,进程基本上死亡了,但还有一个空壳,以僵尸进程的形式存在,它通过等待操作被父进程埋葬(释放)。
等待子进程终止
在任何时候,进程都可以调用内核函数
pid = kwait(int *status)
等待僵尸子进程。如果成功,则返回的pid是僵尸子进程的pid,而status包含僵尸子进程的退出代码。此外,kwait()还会将僵尸子进程释放回freeList以便重用。
kwait的算法如下。

在kwait算法中,如果没有子进程,则进程会返回-1,表示错误。否则,它将搜索僵尸子进程。如果它找到僵尸子进程,就会收集僵尸子进程的pid和退出代码,将僵尸进程释放到freeList并返回僵尸子进程的pid。否则,它将在自己的PROC地址上休眠,等待子进程终止。由于每个PROC地址都是一个唯一值,所有子进程也都知道这个值,所以等待的父进程可以在自己的PROC地址上休眠,等待子进程稍后唤醒它。相应地,当进程终止时,它必须发出:
kwakeup(running->parent);
以唤醒父进程。若不用父进程地址,也可使用父进程pid进行验证。在kwait()算法中,进程唤醒后,当它再次执行while循环时,将会找到死亡的子进程。注意,每个kwait()调用只处理一个僵尸子进程(如有)。如果某个进程有多个子进程,那么它可能需要多次调用kwait()来处理所有死亡的子进程。或者,某进程可以先终止,而不需要等待任何死亡子进程。当某进程死亡时,它所有的子进程都成了P1的子进程。在真实系统中,P1在无限循环中执行,多次等待死亡的子进程,包括接收的孤儿进程。因此,在类Unix系统中,INIT进程P1扮演着许多角色。
- 它是除P0之外所有进程的祖先。具体来说,它是所有用户进程的始祖,因为所有登录进程都是P1的子进程。
- 它就像孤儿院的院长,所有孤儿都会送到它这里,并叫它爸爸。
- 它又像是太平间管理员,因为它要不停地寻找僵尸进程,以埋葬它们死亡的空壳。
所以,在类Unix系统中,如果INIT进程P1死亡或被卡住,系统将停止工作,因为用户无法再次登录,系统内很快就会堆满腐烂的尸体。(INIT进程非常重要)
MT系统中的进程管理
实现MT系统的进程管理函数需要包含以下四个要素。
- 用二叉树的形式实现进程家族树
- 实现ksleep()和kwakeup()进程同步函数
- 实现kexit()和kwait()进程管理函数
- 添加“w”命令来测试和演示等待操作
Unix/Linux中的进程
进程来源
当操作系统启动时,操作系统内核的启动代码会强行创建一个PID=0的初始进程,即通过分配PROC结构体(通常是proc[0])进行创建,初始化PROC内容,并让运行指向proc[0]。然后,系统执行初始进程P0。大多数操作系统都以这种方式开始运行第一个进程。P0继续初始化系统,包括系统硬件和内核数据结构。然后,它挂载一个根文件系统,使系统可以使用文件。在初始化系统之后,P0复刻出一个子进程P1,并把进程切换为以用户模式运行P1。
INIT和守护进程
当进程P1开始运行时,它将其执行映像更改为INIT程序。因此,P1通常被称为INIT进程,因为它的执行映像是init程序。P1开始复刻出许多子进程。P1的大部分子进程都是用来提供系统服务的。它们在后台运行,不与任何用户交互。这样的进程称为守护进程。守护进程的例子如下。
syslogd:log daemon process
inetd:Internet service daemon process
httpd:HTTP server daemon process
etc.
登录进程
除了守护进程之外,P1还复刻了许多LOGIN进程,每个终端上一个,用于用户登录。每个LOGIN进程打开三个与自己的终端相关联的文件流。这三个文件流是用于标准输人的stdin、用于标准输出的stdout和用于标准错误消息的stderr。每个文件流都是指向进程堆区中FILE结构体的指针。每个FILE结构体记录一个文件描述符(数字),stdin的文件描述符是0,stdout的是1,stderr的是2。然后,每个LOGIN进程向stdout显示一个
login:
以等待用户登录。用户账户保存在/etc/passwd和/etc/shadow文件中。每个用户账户在表单的/etc/passwd文件中都有一行对应的记录,
name:x:gid:uid:description:home:program
其中name为用户登录名,x表示登录时检查密码,gid为用户组ID, uid为用户ID, home为用户主目录,program为用户登录后执行的初始程序。其他用户信息保存在/etc/shadow文件中。shadow文件的每一行都包含加密的用户密码,后面是可选的过期限制信息,如过期日期和时间等。当用户尝试使用登录名和密码登录时,Linux将检查/etc/passwd文件和/etc/shadow文件,以验证用户的身份。
sh进程
当用户成功登录时,LOGIN进程会获取用户的gid和uid,从而成为用户的进程。它将目录更改为用户的主目录并执行列出的程序,通常是命令解释程序sh。现在,用户进程执行sh,因此用户进程通常称为sh进程。它提示用户执行命令。一些特殊命令,如cd(更改目录)、退出、注销等,由sh自己直接执行。其他大多数命令是各种bin目录(如/bin、/sbin ,/usr/bin,/usr/local/bin等)中的可执行文件。对于每个(可执行文件)命令,sh会复刻一个子进程,并等待子进程终止。子进程将其执行映像更改为命令文件并执行命令程序。子进程在终止时会唤醒父进程sh,父进程会收集子进程终止状态,释放子进程PROC结构体并提示执行另一个命令等。除简单的命令之外,sh还支持I/O重定向和通过管道连接的多个命令。
进程的执行模式
在Unix/Linux中,进程以两种不同的模式执行,即内核模式和用户模式,简称Kmode和Umode。在每种执行模式下,一个进程有一个执行映像,如下图所示。

在图中,索引i表示这些是进程i的映像。通常,进程在Umode下的映像都不相同。但是,在Kmode下,它们的Kcode、Kdata和Kheap都相同,这些都是操作系统内核的内容,但是每个进程都有自己的Kstack。
在进程的生命周期中,会在Kmode和Umode之间发生多次迁移。每个进程都在Kmode下产生并开始执行。事实上,它在Kmode下执行所有相关操作,包括终止。在Kmode模式下,通过将CPU的状态寄存器从K模式更改为U模式,可轻松切换到Umode。但是,一旦进入Umode,就不能随意更改CPU的状态了,原因很明显。Umode进程只能通过以下三种方式进入Kmode:
(1)中断:中断是外部设备发送给CPU的信号,请求CPU服务。当在Umode下执行时,CPU中断是启用的,因此它将响应任何中断。在中断发生时,CPU将进入Kmode来处理中断,这将导致进程进入Kmode。
(2)陷阱:陷阱是错误条件,例如无效地址、非法指令.除以0等,这些错误条件被CPU识别为异常,使得CPU进人Kmode来处理错误。在Unix/Linux中,内核陷阱处理程序将陷阱原因转换为信号编号,并将信号传递给进程。对于大多数信号,进程的默认操作是终止。
(3)系统调用:系统调用(简称syscall)是一种允许Umode进程进入Kmode以执行内核函数的机制。当某进程执行完内核函数后,它将期望结果和一个返回值返回到Umode,该值通常为0(表示成功)或-1(表示错误)。如果发生错误,外部全局变量errno(在errno.h中)会包含一个ERROR代码,用于标识错误。用户可使用库函数
perror("error message");
来打印某个错误消息,该消息后面跟着一个描述错误的字符串。
每当一个进程进入Kmode时,它可能不会立即返回到Umode。在某些情况下,它可能根本不会返回到Umode。例如,_exit() syscall和大多数陷阱会导致进程在内核中终止,这样它永远都不会再返回到Umode。当某进程即将退出Kmode时,操作系统内核可能会切换进程以运行另一个具有更高优先级的进程。
进程管理的系统调用
与进程管理相关的以下系统调用有:
fork(),wait(),exec(),exit()
每个都是发出实际系统调用的库函数:
int syscall(int a, int b, int c, int d);
其中,第一个参数a表示系统调用号,b、c、d表示对应核函数的参数。在基于Intel x86的Linux中,系统调用是由汇编指令INT 0x80实现的,使得CPU进入Linux内核来执行由系统调用号a标识的核函数。
fork()
fork的用法为: int pid = fork();
fork()创建子进程并返回子进程的pid,如果失败则返回-1。下面是fork()操作图示。

fork()成功之后,父进程和子进程都执行它们自己的Umode映像,紧跟着fork()之后的映像是完全相同的。从程序代码角度来看,借助返回的pid是判断当前正在执行进程的唯一方法。因此,程序代码应写成:
int pid = fork();
if(pid){
//parent executes this part
}
else{
//child executes this part
}
下图为fork()的代码示例

该程序由sh的子进程运行。在示例代码中,getpid()和getppid()是系统调用。getpid()返回调用进程的PID,getppid()返回父进程的PID。
- 第(1)行复刻一个子进程。
- 第(2)行打印正在执行进程的PID和新复刻子进程的PID。
- 第(3)行打印子进程的PID,应与第(2)行中子进程的PID相同,以及其父进程的PID,应与第(2)行中进程的PID相同。
进程执行顺序
在fork()完成后,子进程与父进程和系统中所有其他进程竞争CPU运行时间。接下来运行哪个进程取决于它们的调度优先级,优先级呈动态变化。下面是演示进程可能的各种执行顺序的代码示例。

在示例代码中,父进程复刻出一个子进程。在fork()完成后,接下来运行哪个进程取决于它们的优先级。子进程可能会先运行和终止,但也可能后运行和终止。如果进程执行非常长的代码,它们可能会轮流运行,因此它们的输出可能会交错显示在屏幕上。为了查看不同进程的执行顺序,可以进行以下测试。
(1)取消第(1)行注释,让父进程休眠1秒钟。然后,子进程先运行完成。
(2)取消第(2)行注释,但不取消第(1)行注释,让子进程休眠2秒钟。然后,父进程先运行完成。如果父进程先终止,子进程的ppid将会更改为1或其他PID号。
(3)取消第(1)行和第(2)行注释。得到的结果应与第(2)种情况相同。
除了sleep(seconds)可以让调用进程延迟几秒之外,Unix/Linux还提供以下系统调用,可能会影响进程的执行顺序。
- nice(int inc):nice()将进程优先级值增大一个指定值,这会降低进程调度优先级(优先级值越大,意味着优先级越低)。如果有优先级更高的进程,将会触发进程切换,首先运行优先级更高的进程。在非抢占式内核中,进程切换可能不会立即发生。它只在执行进程即将退出Kmode并返回Umode时发生。
- sched_yield(void):sched_yield()使调用进程放弃CPU,允许优先级更高的其他进程先运行。但是,如果调用进程仍然具有最高优先级,它将继续运行。
进程终止
执行程序映像的进程可能以两种方式终止。
(1)正常终止:每个C程序的main()函数都是由C启动代码crt0.o调用的。如果程序执行成功,main()最终会返回到crt0.o,调用库函数exit(0)来终止进程。首先,exit(value)函数会执行一些清理工作,如刷新stdout、关闭I/O流等。然后,它发出一个_exit(value)系统调用,使进入操作系统内核的进程终止。退出值0通常表示正常终止。如果需要,进程可直接从程序内的任何位置调用exit(value),不必返回到crt0.o。再直接一点,进程可能会发出_exit(value)系统调用立即执行终止,不必先进行清理工作。当内核中的某个进程终止时,它会将_exit(value)系统调用中的值记录为进程PROC结构体中的退出状态,并通知它的父进程并使该进程成为僵尸进程。父进程可通过系统调用找到僵尸子进程,获得其pid和退出状态
pid = wait(int *status);
它还会清空僵尸子进程PROC结构体,使该结构可被另一个进程重用。
(2)异常终止:在执行某程序时,进程可能会遇到错误,如非法指令、越权、除零等,这些错误会被CPU识别为异常。当某进程遇到异常时,它会阱入操作系统内核。内核的异常处理程序将陷阱错误类型转换为一个幻数,称为信号,将信号传递给进程,使进程终止。在这种情况下,进程非正常终止,僵尸进程的退出状态是信号编号。除了陷阱错误,信号也可能来自硬件或其他进程。例如,按下“Ctrl+C”组合键会产生一个硬件中断信号,它会向该终端上的所有进程发送信号2中断信号,使进程终止。或者,用户可以使用命令
kill -s signal_number pid # signal_number=1 to 31
向通过pid识别的目标进程发送信号。对于大多数信号数值,进程的默认操作是终止。
在这两种情况下,当进程终止时,最终都会在操作系统内核中调用kexit()函数。唯一的区别是Unix/Linux内核将擦除终止进程的用户模式映像。
在Linux中,每个PROC都有一个2字节的退出代码(exitCode)字段,用于记录进程退出状态。如果进程正常终止,exitCode的高位字节是_exit(exitValue)系统调用中的exitValue。低位字节是导致异常终止的信号数值。因为一个进程只能死亡一次,所以只有一个字节有意义。
等待子进程终止
在任何时候,一个进程都可以使用
int pid = wait(int *status);
系统调用,等待僵尸子进程。如果成功,则wait()会返回僵尸子进程的PID,而且status包含僵尸子进程的exitCode。此外,wait()还会释放僵尸子进程,以供重新使用。wait()系统调用将调用内核中的kwait()函数。下面是演示等待和退出系统调用的示例代码。


在运行示例代码时,子进程终止状态为0x6400,其中高位字节是子进程的退出值100。
为什么wait()要等待任何僵尸子进程?
在复刻若干登录进程后,P1等待任何僵尸子进程。一旦用户从终端注销,P1一定会立即响应以复刻该终端上的另一个登录进程。由于P1不知道哪个登录进程会先终止,所以它必须等待任何僵尸登录子进程,而不是等待某个特定的进程。或者,某进程可以使用系统调用
int pid = waitpid(int pid, int *status, int options);
等待由pid参数指定的具有多个选项的特定僵尸子进程。例如,wait(&status)等于waitpid(-i,&status,0)。
Linux中的subreaper进程
进程可以用系统调用将自己定义为subreaper:
prctl(PR_SET_CHILD_SUBREAPER);
这样,init进程P1将不再是孤儿进程的父进程。相反,标记为subreaper的最近活跃祖先进程将成为新的父进程。如果没有活跃的subreaper进程,孤儿进程仍然像往常一样进入INIT进程。实现该机制的原因如下:许多用户空间服务管理器(如upstart、systemd等)需要跟踪它们启动的服务。这类服务通常通过两次复刻来创建守护进程,但会让中间子进程立即退出,从而将孙子进程升级为P1的子进程。该方案的缺点是服务管理器不能再从服务守护进程接收SIGCHLD(death_of_child)信号,也不能等待任何僵尸子进程。当P1清理重定父级的进程时,将会丢失关于子进程的所有信息。使用subreaper机制,服务管理器可以将自己标记为“sub-init”,并且现在可以作为启动服务创建的所有孤儿进程的父进程。这也减少了P1的工作量,它不必处理系统中所有的孤儿进程。在Ubuntu-15.10和后续版本中,每个用户init进程均标记为subreaper。它在Umode下运行,属于用户。
使用sh命令:
ps fxau | grep USERNAME | grep "/sbin/upstart"
可以显示subreaper进程的PID和信息。相反,它是用户所有孤儿进程的父进程,而不是P1。下面是subreaper进程代码示例。


在上面的程序中,进程(9620)首先将自己标记为subreaper。然后,它复刻出一个子进程(9621),并使用while循环等待僵尸子进程,直到结束。该子进程复刻出自己的一个子进程,是第一个进程的孙子进程(9622)。当程序运行时,子进程(9621)或孙子进程(9622)可以先终止。如果孙子进程先终止,它的父进程会保持不变(9621)。但如果子进程先终止而且没有任何活跃的祖先进程被标记为subreaper,孙子进程将会成为P1的子进程。因为第一个进程(9620)是subreaper,如果孙子进程的父进程先死亡,它会将孙子进程作为孤儿进程来收养。输出表明,当孙子进程开始运行时,它的父进程是9621,但是在退出时更改为9620,因为原来的父进程已经死亡。输出还表明,subreaper进程9620已将9621和9622作为僵尸子进程收养了。如果用户杀死每个用户的init进程,就相当于用户注销。在这种情况下,P1将复刻出另一个用户init进程,要求用户再次登录。
exec():更改进程执行映像
进程可以使用exec()将其Umode映像更改为不同的(可执行)文件。exec()库函数有几个成员:
int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg, .., char *const envp[]);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
以上函数都是针对系统调用进行封装的库函数,准备参数并最终发出系统调用
int execve(const char *filename, char *const argv[], char *const envp[]);
在execve()系统调用中,第一个参数文件名与当前工作目录(CWD)或绝对路径名有关。参数argv[]是一个以NULL结尾的字符串指针数组,每个指针指向一个命令行参数字符串。按照惯例,argv[0]是程序名,其他argv[ ]项是程序的命令行参数。例如,对于命令行:
a.out one two three
下面显示了argv[]的布局。
0 1 2 3 4
argv[ ] = [ . | . | . | . | NULL ]
| | | |
"a.out""one" "two" "three"
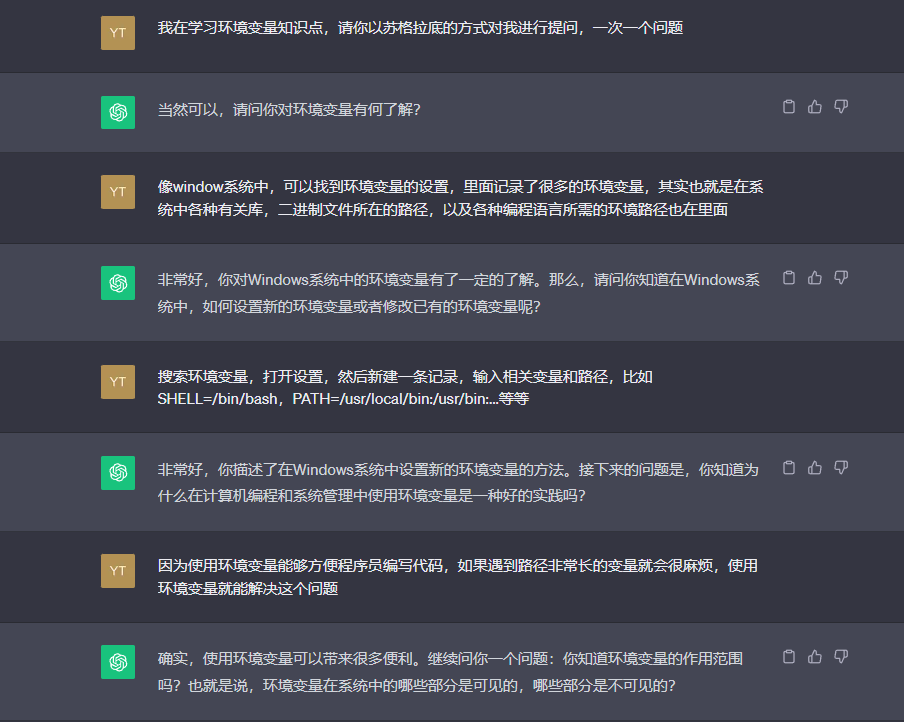
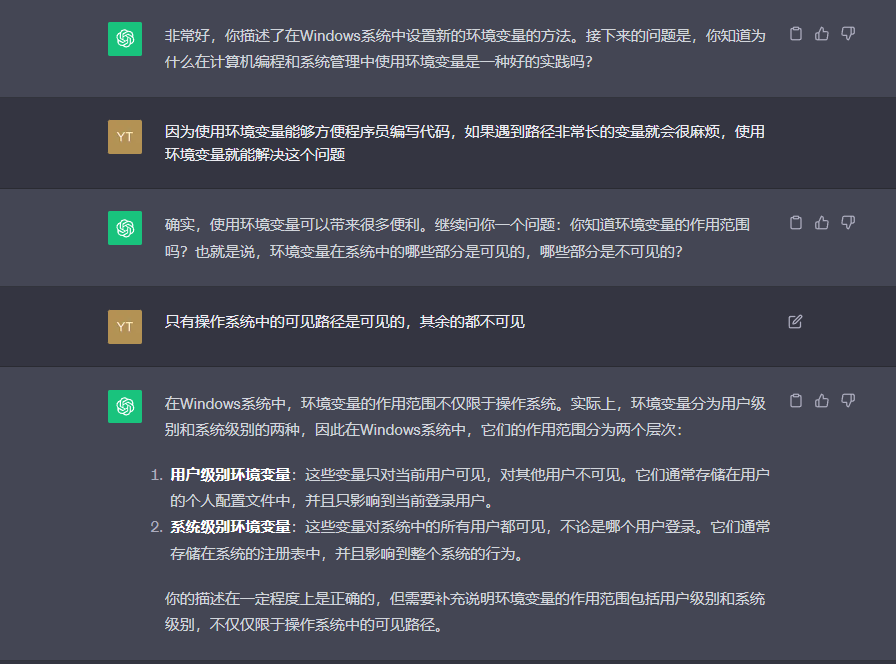
环境变量
环境变量是为当前sh定义的变量,由子sh或进程继承。当sh启动时,环境变量即在登录配置文件和.bashrc脚本文件中设置。它们定义了后续程序的执行环境。各环境变量定义为:
关键字=字符串
在sh会话中,用户可使用env或printenv命令查看环境变量。下面列出了一些重要的环境变量:
SHELL=/bin/bash
TERM=xterm
USER=kcw
PATH=/usr/local/bin:/usr/bin:/bin:/usr/local/games:/usr/games:./
HOME=/home/kcw
- SHELL:指定将解释任何用户命令的sh。
- TERM:指定运行sh时要模拟的终端类型。
- USER:当前登录用户。
- PATH:系统在查找命令时将检查的目录列表。
- HOME:用户的主目录。在Linux中,所有用户主目录都在/home中。
在sh会话中,可以将环境变量设置为新的(字符串)值,如:
HOME=/home/newhome
可通过EXPORT命令传递给后代sh,如:
export HOME
也可以将它们设置为空字符串来取消设置。在某个进程中,环境变量通过env[]参数传递给C程序,该参数是一个以NULL结尾的字符串指针数组,每个指针指向一个环境变量。
环境变量定义了后续程序的执行环境。例如,当sh看到一个命令时,它会在PATH环境变量的目录中搜索可执行命令(文件)。大多数全屏文本编辑器必须知道它们所运行的终端类型,该类型是在TERM环境变量中设置的。如果没有TERM信息,文本编辑器可能会出错。因此,命令行参数和环境变量都必须传递给正在执行的程序。这是所有C语言程序中main()函数的基础,可以写成:
int main(int argc, char *argv[], char *env[])
I/O重定向
文件流和文件描述符
sh进程有三个用于终端I/O的文件流:stdin(标准输人)、stdout(标准输出)和stderr(标准错误)。每个流都是指向执行映像堆区中FILE结构体的一个指针,如下图所示。

每个文件流对应Linux内核中的一个打开文件。每个打开文件都用一个文件描述符(数字)表示。stdin、stdout、stderr的文件描述符分别为0、1、2。当某个进程复刻出一个子进程时,该子进程会继承父进程的所有打开文件。因此,子进程也具有与父进程相同的文件流和文件描述符。
文件流I/O和系统调用
当进程执行库函数
scanf("%s", &item);
它会试图从stdin文件输入一个(字符串)项,指向FILE结构体。如果FILE结构体的fbuf[]为空,它会向Linux内核发出read系统调用,从文件描述符0中读取数据,映射到终端(/dev/ttyX)或伪终端(/dev/pts/#)键盘上。
重定向标准输入
如果用一个新打开的文件来替换文件描述符0,那么输入将来自该文件而不是原始输入设备。因此,如果执行以下代码:
#include <fcntl.h> //contains O_RDONLY, O_WRONLY, O_APPEND, etc
close(0); //syscall to close file descriptor 0
int fd=open("filename", O_RDONLY); //open filename for READ,
//fd replace 0
close(0)系统调用会关闭文件描述符0,使0成为未使用的文件描述符。open()系统调用会打开一个文件,并使用最小的未使用描述符数值作为文件描述符。在这种情况下,打开文件的文件描述符为0。因此,原来的文件描述符0会被新打开的文件取代。或者也可以使用:
int fd = open("filename", O_RDONLY); //get a fd first
close(0); //zero out fd[0]
dup(fd); //duplicate fd to 0
系统调用dup(fd)将fd复制到数值最小的未使用文件描述符中,允许fd和0都能访问同一个打开的文件。此外,系统调用
dup2(fd1, fd2)
将fd1复制到fd2中,如果fd2已经打开,则先关闭它。因此,Unix/Linux提供了几种方法来替换/复制文件描述符。完成上述任何一项操作之后,文件描述符0将被替换或复制到打开文件中,以便每个scanf()调用都将从打开的文件中获取输入。
重定向标准输出
当进程执行库函数
printf("format=%s\n", items);
它试图将数据写入stdout文件FILE结构体中的fbuf[],这是缓冲行。如果fbuf[]有一个完整的行,它会发出一个write系统调用,将数据从fbuf[]写入文件描述符1,映射到终端屏幕上。要想将标准输出重定向到一个文件,需执行以下操作。
close(1);
open("filename", O_WRONLY|O_CREAT, 0644);
更改文件描述符1,指向打开的文件名。然后,stdout的输出将会转到该文件而不是屏幕。同样,也可以将stderr重定向到一个文件。当某进程(在内核中)终止时,它会关闭所有打开的文件。
管道
- 管道:用于进程交换数据的单向进程间通信通道,有一个读取端和一个写入端。可以从管道的读取端读取写入管道写入端的数据。
- 双向管道:数据可以双向传输的管道。
- 命名管道:不相关进程之间的FIFO通信管道。
读取和写入管道通常是同步、阻塞操作,一些系统支持管道的非阻塞、异步读/写操作。为方便分析,将管道视为一组相关进程之间的有限尺寸FIFO通信通道。管道的读、写进程按以下方式同步。
当读进程从管道上读取数据时,如果管道上有数据,读进程会根据需要读取(不超过管道大小)并返回读取的字节数。如果管道没有数据,但仍有写进程,读进程会等待数据。当写进程将数据写入管道时,它会唤醒等待的读进程,使它们继续读取。如果管道没有数据也没有写进程,读进程返回0。如果管道仍然有写进程,读进程会等待数据,因此0返回值只能意味着管道没有数据也没有写进程。在这种情况下,读进程会停止从管道读取。当写进程写入管道时,如果管道有空间,它会根据需要尽可能多地写入,直至管道写满,即没有更多空间。如果管道没有空间,但仍有读进程,写进程会等待空间。当读进程从管道读取数据来释放更多空间时,它会唤醒等待的写进程,让它们继续写入。但是,如果管道不再有读进程,写进程必须将这种情况视为管道中断错误,并中止写入。
Unix/Linux中的管道编程
在Unix/Linux中,一系列相关系统调用为管道提供支持。系统调用
int pd[2]; //array of 2 integers
int r = pipe(pd); //return value r=0 if OK, -1 if failed
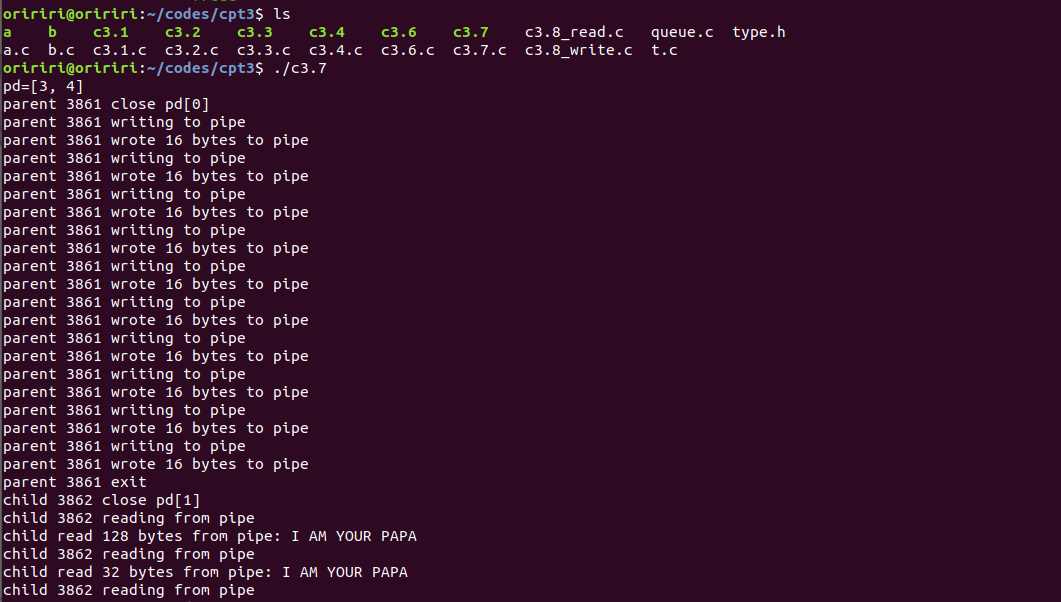
在内核中创建一个管道并在pd[2]中返回两个文件描述符,其中pd[0]用于从管道中读取,pd[1]用于向管道中写入。然而,管道并非为单进程而创建。例如,在创建管道之后,如果进程试图从管道中读取1个字节,它将永远不会从读取的系统调用中返回。因为当进程试图从管道中读取数据时,管道中尚无数据,但是有一个写进程,所以它会等待数据。但是写进程是进程本身。所以进程在等待自己,可以说是把自己锁起来了。相反,如果进程试图写入的大小超过管道大小(大多数情况下为4KB),则当管道写满时,进程将再次等待自己。因此,进程只能是管道上的一个读进程或者一个写进程,但不能同时是读进程和写进程。管道的正确使用方式如下。
在创建管道后,进程复刻一个子进程来共享管道。在复刻过程中,子进程继承父进程的所有打开文件描述符。因此,子进程也有pd[0](用于从管道中读取数据)和 pd[1](用于向管道中写入数据)。用户必须将其中一个进程指定为管道的写进程,并将另一个进程指定为管道的读进程。只要指定每个进程只扮演一个角色,指定的顺序并不重要。假设父进程被指定为写进程,子进程被指定为读进程。各进程必须关闭它不需要的管道描述符,即写进程必须关闭pd[0],读进程必须关闭pd[1]。然后,父进程可向管道写入数据,子进程可从管道读取数据。下图是管道操作的系统模型。
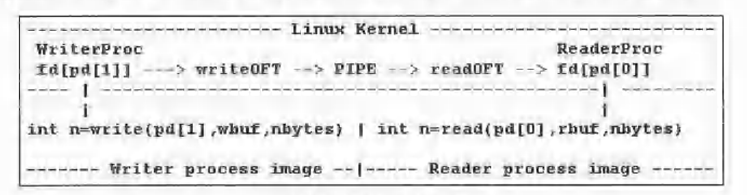
在模型左侧,一个写进程发出
write(pd[1], wbuf, nbytes)
系统调用,进入操作系统内核。它使用文件描述符pd[1]通过writeOFT来访问管道。它执行write_pipe(),向管道的缓冲区写入数据,并在必要时等待空间。
在模型右侧,一个读进程发出
read(pd[0], rbuf, nbytes)
系统调用,进入操作系统内核。它使用文件描述符pd[0]通过readOFT来访问管道。它执行read_pipe(),从管道的缓冲区读取数据,并在必要时等待数据。
当写进程没有更多数据要写时,它可以先终止,在这种情况下,只要管道仍然有数据,读进程就可以继续读取。但是,如果读进程先终止,写进程须将这种情况视为管道中断错误,并随之终止。
管道中断状况并不具有对称性。这是一种只有读进程没有写进程的通信通道。实际上,管道并未中断,因为只要管道有数据,读进程就仍可继续读取。下面是管道操作示例代码。

管道命令处理
在Unix/Linux中,命令行
cmd1 | cmd2
包含一个管道符号“|”。sh将通过一个进程运行cmd1,并通过另一个进程运行cmd2,它们通过一个管道连接在一起,因此cmd1的输出变成cmd2的输入。
连接管道写进程与管道读进程
(1)当sh获取命令行cmd1|cmd2时,会复刻出一个子进程sh,并等待子进程sh照常终止。
(2)子进程sh:浏览命令行中是否有|符号。在这种情况下,
cmd1 | cmd2
有一个管道符号|。将命令行划分为头部=cmd1,尾部=cmd2
(3)然后,子进程sh执行以下代码段:
int pd[2];
pipe(pd); //creates a PIPE
pid = fork(); //fork a child(to share the PIPE)
if(pid){ //parent as pipe WRITER
close(pd[0]); //WRITER MUST close pd[0]
close(1); //close 1
dup(pd[1]); //replace 1 with pd[1]
close(pd[1]); //close pd[1]
exec(head); //change image to cmd1
}
else{ //child as pipe READER
close(pd[1]); //READER MUST close pd[1]
close(0);
dup(pd[0]) //replace 0 with pd[0]
close(pd[0]); //close pd[0]
exec(tail); //change image to cmd2
}
管道写进程重定向其fd=i到pd[i],管道读进程重定向其fd=0到pd[0]。这样,这两个进程就可以通过管道连接起来了。
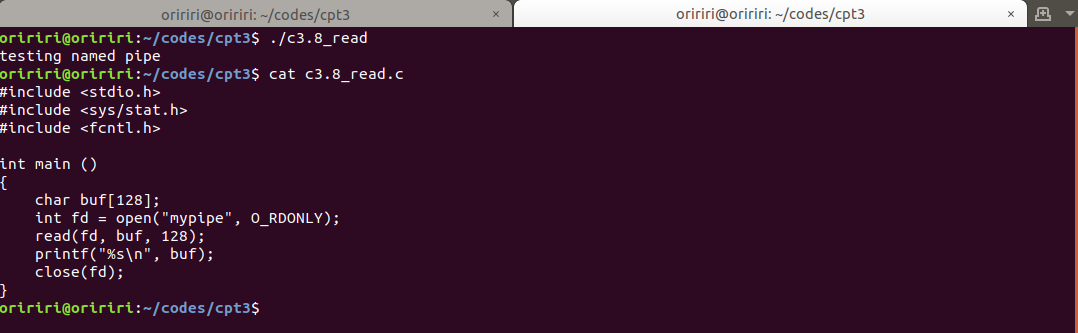
命名管道
命名管道又叫作FIFO。它们有“名称”,并在文件系统中以特殊文件的形式存在。它们会一直存在下去,直至用rm或unlink将其删除。它们可与非相关进程一起使用,并不局限于管道创建进程的子进程。
命名管道示例
(1)在sh中,通过mknod命令创建一个命名管道:
mknod mypipe p
(2)或者在C程序中,发出mknod()系统调用:
int r = mknod("mypipe", S_IFIFO, 0);
步骤(1)或(2)都可以在当前目录中创建一个名为mypipe的特殊文件。输入:
ls -l mypipe
将显示为:
prw-r-r- 1 root root 0 time mypipe
其中文件类型p表示它是管道,链接数=1,大小=0。
(3)进程可像访问普通文件一样访问命名管道。但是,对命名管道的写入和读取是由Linux内核同步的。
下图显示了写进程和读进程通过sh命令在命名管道上的交互状态。从图中可以看出,如果没有读进程从管道上读取数据,写进程就会停止。如果管道上没有数据,读进程就会停止。

除sh命令外,C语言程序中创建的进程也可以使用命名管道。下图是C语言程序中命名管道操作示例代码。

GPT提问环节
进程
环境变量
在学习中遇到的一些问题
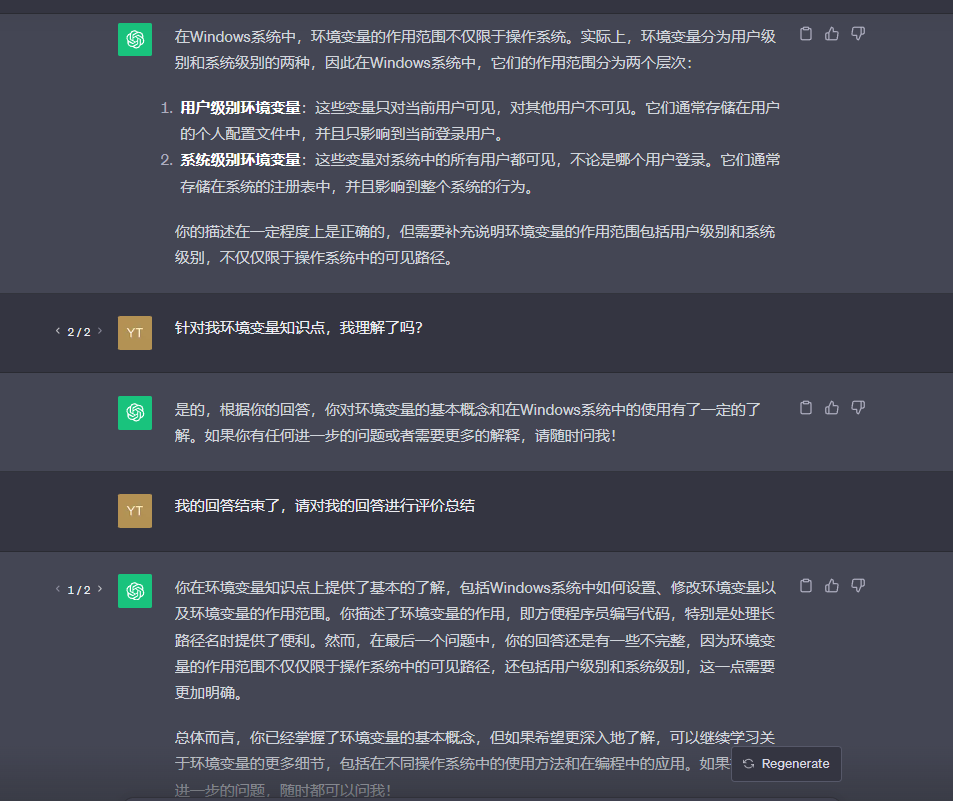
问题1:在安装好openssl后我删除了桌面的安装包,再次使用命令openssl prime -help,命令失效,如下图。

通过询问GPT后,按照GPT的方法再次使用命令生效。
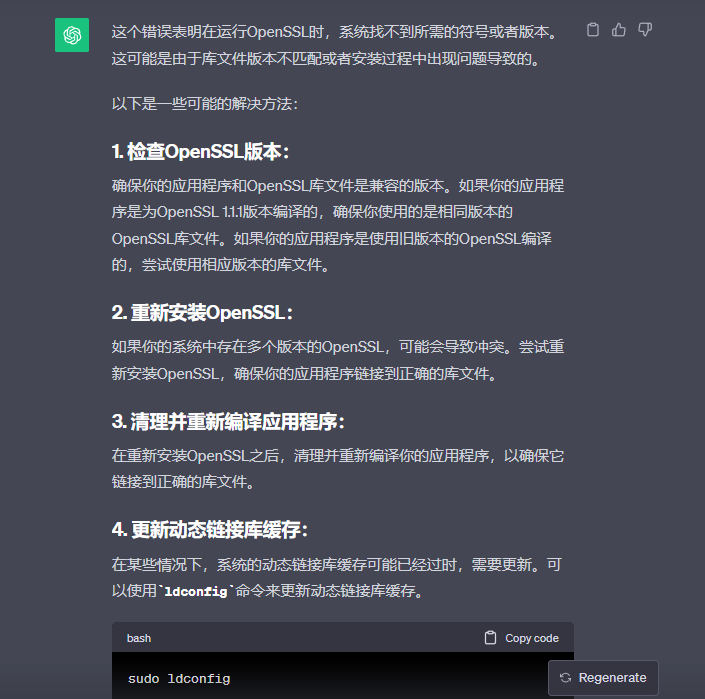
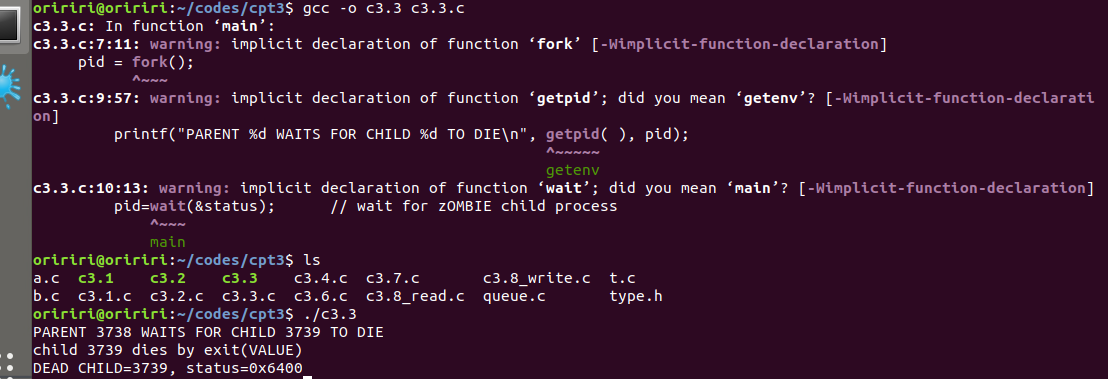
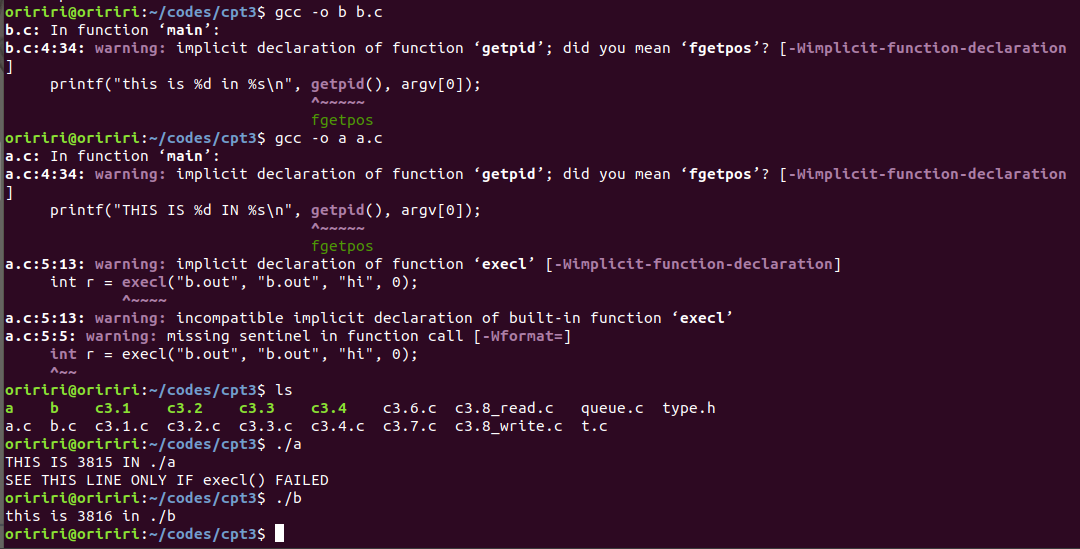
问题2:在进行教材上的代码操作时,编译代码出现报错如下图。
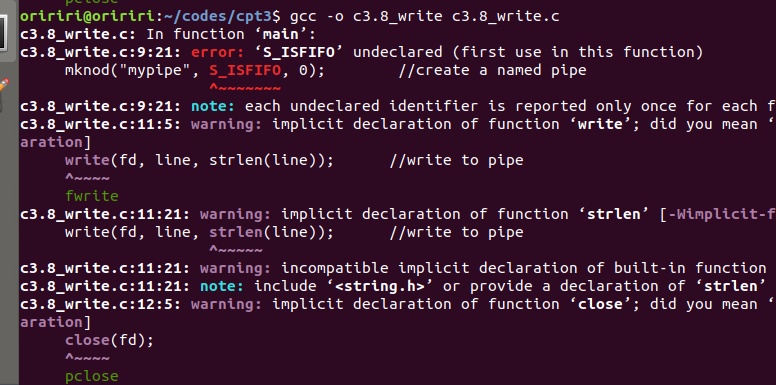
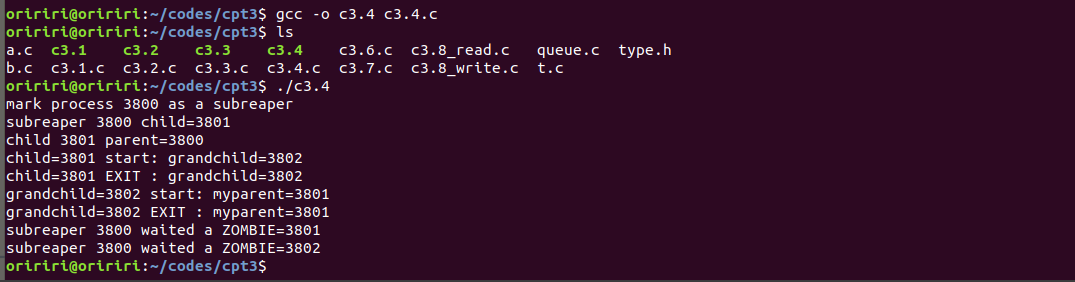
询问GPT后GPT给出了详细的解释,按照GPT给出的方法重新编写代码后再次编译就成功了。
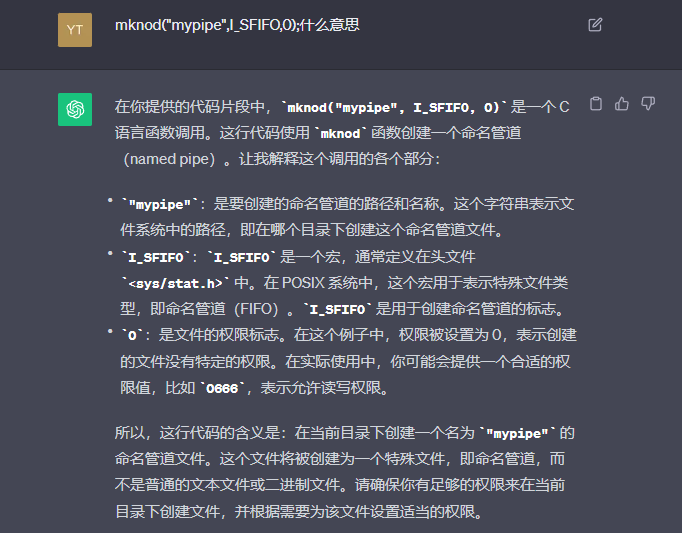
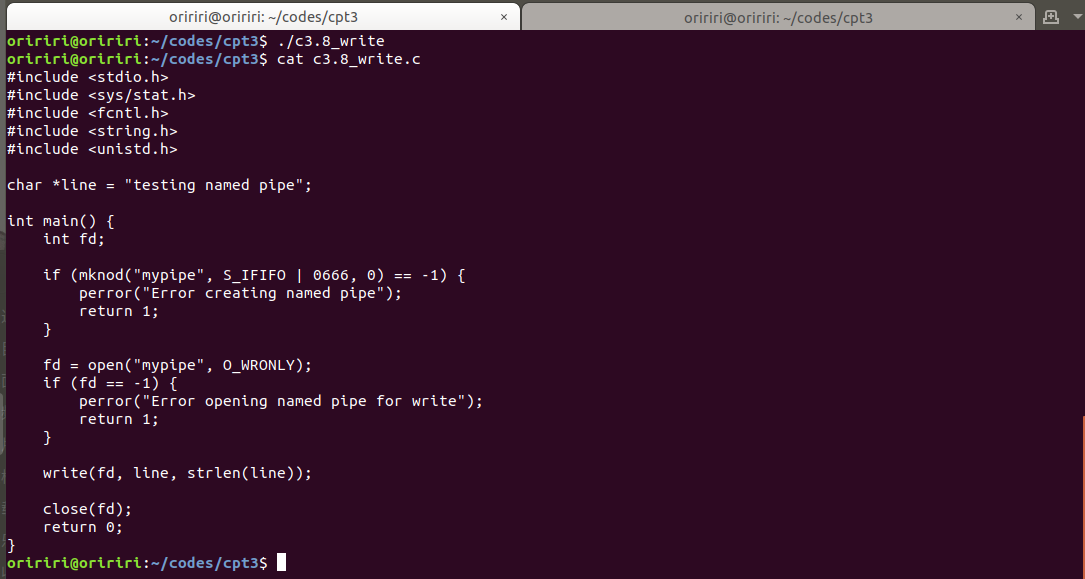
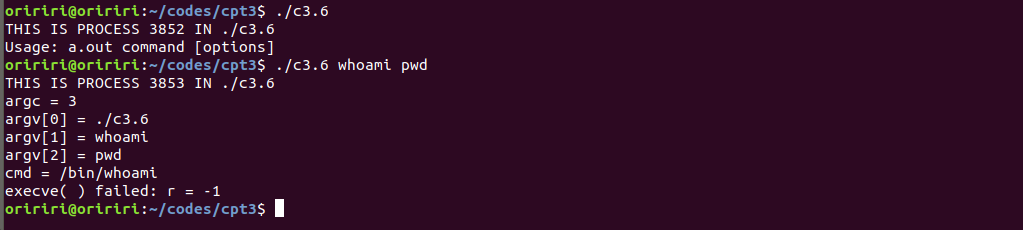
问题3:运行教材上的示例代码出现问题,如下图。
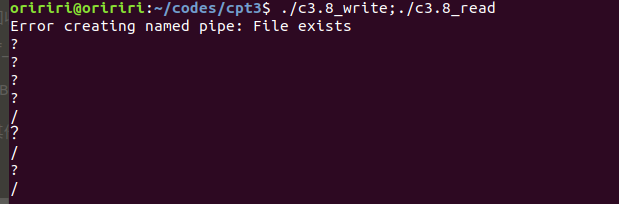
询问GPT后我找到了问题所在,管道写和读操作需要分别在两个终端中运行才能实现。
代码实践

c3.8_read.c
c3.8_write.c
管道读
管道写