PPA, Performance, Power, Area 是衡量一颗芯片的基本指标,这三大指标中Power 是最诡诈的,它不像Performance 跟Area 是可相对精确计算的,而Power 在芯片回来之前都只能估算,至于估算值跟实际值相差几何,也是一个说不清道不明的东西,主要原因在于:
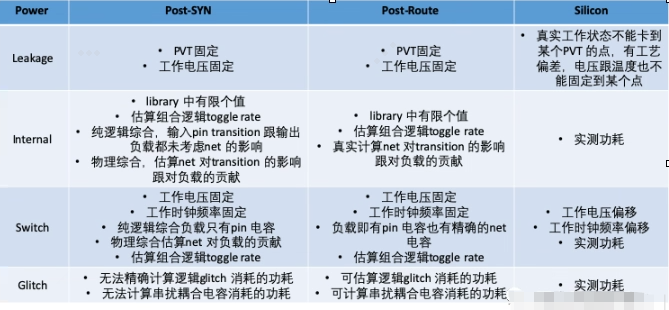
- leakage power, 不论是综合还是PostRoute, 计算leakage 都是从某个固定PVT library 中查表,然而实际芯片并不能确定地工作于某个固定的电压值,一方面是供电电源无法保证完全没有偏差,另一方面是IR-drop 的影响;更不能保证工作温度一定卡到某个摄氏度;工艺偏差在timing 上有各种模型进行模拟,然而在power 上并没有;leakage 的计算可回顾数字IC低功耗设计中的leakage power 分析。
- internal power, 除了固定的PVT 之外,toggle rate 也只是估算,通常工具只能从波形里读取时序逻辑、blackbox 等的翻转信息,至于组合逻辑的toggle rate 大都是估算得到的。
- Switch power, 除了无法精确得到toggle rate 的信息之外,实际芯片的工作电压跟工作时钟频率都会有偏差;动态功耗的计算可回顾数字IC低功耗设计的动态功耗分析部分。
- Glitch power, 目前大部分power 分析工具可以估算逻辑Glitch 引起的功耗,然而要计算逻辑Glitch 必须要反标net delay, 不论是cell Delay 还是net Delay 在估算时都只在某个固定的PVT 跟RC corner, 如此计算得到的值势必跟实测值有差别。
- 其他,如I/O, 如package, 如Analog, 其功耗模型的准确性。
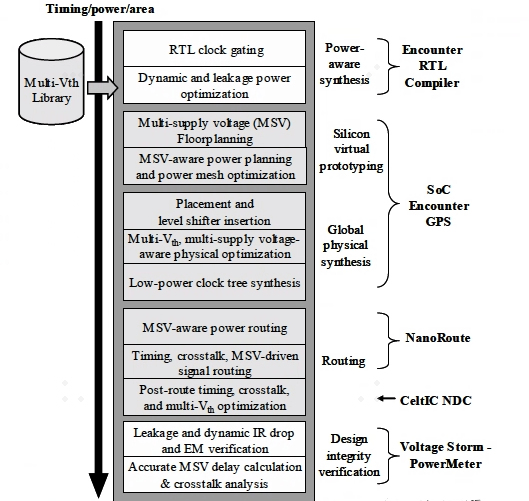
《 Closing the Power Gap Between ASIC & Custom, Tools and Techniques for Low Power Design 》通篇有理有据介绍了综合到postroute的功耗gap,除了工艺老了一点,其他都很好。取书中一张图,涵盖了综合到Postroute 的每一步。

先回顾一下功耗的三大部分Leakage, Internal, Switch 都跟哪些因素有关?
- Leakage Power: 跟工作电压VDD, 阈值电压Vth, 管子宽长比及输入pin 的状态有关;
- Internal Power: 跟Arc/pin 上有效的toggle rate, SDPD, 输入pin 的transition 及输出负载有关;
- Switch power: 跟工作电压,工作时钟频率,Toggle rate 及输出负载有关。

再看,从综合到PostRoute 在设计上发生了哪些变化?
- 纯逻辑综合:没有线长的概念,没有长线的buffer, 没有clock tree, 没有hold buffer, clock 是ideal 的,通常需要过约从而导致使用更大面积跟功耗的cell,没有net 电容,没有串扰信息;
- 物理综合:工具相对精确的估算线长并做buffering, 如果是Ispatial ECF flow 可以build clock tree, 没有hold buffer, clock 是ideal 的,不需要过约,有net 电容,没有串扰信息;
- P&R: 真实的绕线,真实的clock tree, 修过hold, clock 是propagated, 用signoff 约束,有net 电容,有串扰信息;

每一部分设计上的改变对功耗影响有多大,取决于设计特性跟工艺:
- 比如,对于Port 多Density 低的设计,会有许多长线,所以长线上的buffer 会有许多;
- 比如,只有一个clock 跟几千个寄存器的设计和有几千个clock 跟几十万个寄存器的设计相比,clock tree 的结构长短区别会很大,clock tree 功耗占比自然也不同;
- 比如,.18 跟5nm 相比,net 电容在整个设计中的比重完全不同,有没有net 电容对5nm 而言至关重要;
- 比如,congestion 特别严重的设计,cell 会被推散,crosstalk 也可能更严重。
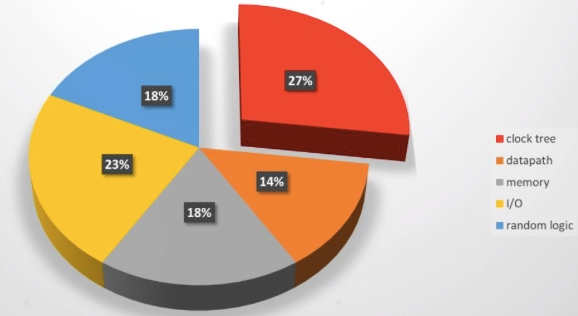
等等不一而足,所以在讨论从综合到PostRoute 的功耗差异时,需要有明确的前提,需要根据不同类型的设计具体问题具体分析,只能在某个小范围内归纳总结,很难找到一个通用法则。
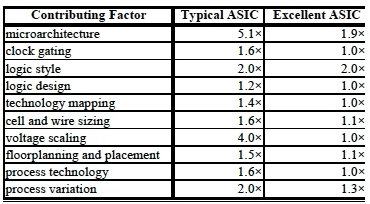
最后再聊聊动态功耗优化,想要再强调一次为什么带波形优化动态功耗最好从物理综合开始?之前的讨论可回顾《论功耗:动态功耗优化》。如果不考虑多电压域,目前在实现端行之有效的动态功耗优化办法无非是:clock gating, MB merge, 带仿真波形。
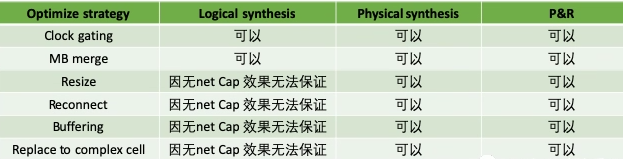
而带仿真波形的优化手段无非是Resize, Reconnect, Buffering, Cell replace, 而不论哪种方法都依赖于负载电容,在40nm之后如果在优化时只看pin 电容而看不到net 电容,综合后的结果跟PostRoute 的结果有巨大差异的概率非常大,所以如果要带着波形去做动态功耗优化,就请从物理综合开始。