前言 在医学成像和遥感等一些细粒度领域,多模态基础模型的性能往往不尽人意。因此,许多研究者开始探索这些模型的少样本适应方法,逐渐衍生出三种主要技术途径:1)基于提示的方法;2)基于适配器的方法;3)基于外部知识的方法。尽管如此,这一迅速发展的领域产生了大量结果,但尚无全面的综述来系统地整理研究进展。因此,在这篇综述中,本文介绍并分析了多模态模型少样本适应方法的研究进展,总结了常用的数据集和实验设置,并比较了不同方法的结果。此外,从以下几个方面提出了三种可能的解决方案:1)自适应领域泛化;2)自适应模型选择;3)自适应知识利用。
本文转载自专知
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!

多模态(视觉-语言)模型,如CLIP,正逐渐取代传统的监督预训练模型(例如,基于ImageNet的预训练)成为新一代的视觉基础模型。这些模型通过从数十亿个互联网图像-文本对中学习,形成了强大且一致的语义表示,并可以在零样本的情况下应用于各种下游任务。人工智能正在越来越多地应用于广泛的关键行业,包括语音识别、图像识别、自动驾驶、智能制造、医学诊断、金融风险控制等。在用人工智能技术赋能各个领域的过程中,经常会遇到与碎片化和多样化需求相关的挑战。过去,模型通常具有较小的参数规模和有限的泛化能力。一个模型只能应对单一场景,导致成本高昂和泛化性能差。近年来,越来越多的研究者开始关注具有更强泛化能力的预训练基础模型。
自2018年以来,如BERT [1]、盘古 [2]、PaLM [3]、GPT4 [4]等基础模型的训练数据和参数规模呈指数级增长,导致在各种自然语言理解任务中的性能显著提高。与此同时,基础模型的发展也逐渐从单一模态(如文本、语音、视觉等)演变为多模态融合。越来越多的研究机构开始关注多模态预训练基础模型,如ViLBERT [5]、CLIP [6]、DeCLIP [7]、FILIP [8]、PyramidCLIP [9]、OFA [10]、BEiT-3 [11]、ERNIE-ViL [12]和Data2vec [13]。
2021年初,OpenAI发布了CLIP,这是一个大规模的多模态模型,用于对齐图像和文本,它使用数十亿互联网数据进行预训练,通过对比学习获得丰富的视觉语言知识。虽然预训练的CLIP模型可以在推理阶段通过使用文本特征作为分类权重来实现零样本预测,但这种方法通常只在诸如ImageNet之类的通用领域中表现出色,在处理某些细粒度领域的数据时表现不佳。这是因为这些模型在预训练阶段主要使用通用领域的数据,而在面对特定的下游任务时,数据分布往往与预训练数据不同。因此,有必要使用下游任务的特定数据对模型进行微调。为了通过微调提高模型的泛化性能,研究人员首先提出了基于提示的微调适应方法(例如,CoOp [14]),该方法将CLIP文本端的固定文本输入视为可学习的向量,然后使用少量样本进行微调,以适应下游任务。另一种常用于增强少样本适应能力的方法是基于适配器的微调,如CLIP-Adapter [15]。这种方法涉及在预训练模型中添加简单的适配器结构,然后使用少量样本数据微调适配器参数,使基础模型适应下游任务。此外,引入基础语言模型或外部知识(如知识图谱,例如,CuPL [16])的方法可以帮助模型更好地处理未见样本,增强其语义理解和鲁棒性,从而提高其在少样本适应任务中的性能。上述三种方法已广泛用于各种下游适应任务,但缺乏一个全面的综述来系统地整理这些方法。因此,我们详细阐述并比较这些方法,并探索它们的未来发展方向,以进一步提高预训练模型的性能和泛化能力。本文的贡献如下:
• 我们全面回顾和整理了多模态少样本适应方法,并将现有方法分类为基于提示的微调适应方法、基于适配器的微调适应方法、基于外部知识的适应方法以及其他方法。在基于提示的微调适应方法中,我们进一步将其细分为文本提示微调、视觉提示微调、多模态提示和多任务提示方法。关于基于适配器的微调适应方法,我们将其分类为单模态适配器微调和多模态适配器微调。在使用外部知识的方法中,我们区分了带有外部知识的预训练方法和利用外部知识的下游适应方法。
• 我们回顾了11个常用数据集,用于评估多模态基础模型的下游泛化性能。我们提供了四种实验设置的详细描述,以验证多模态基础模型在少样本条件下的适应性能。展示了四种不同设置的实验结果,并对这些结果进行了比较分析。我们强调了不同类型方法能有效提高多模态基础模型泛化性能的原因。
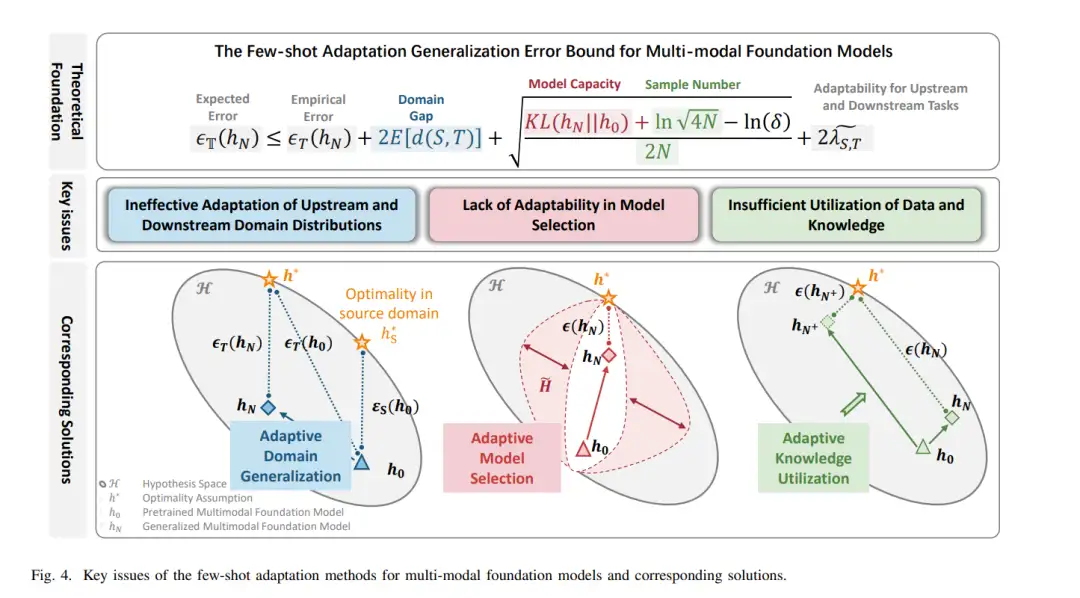
• 我们讨论了现有多模态基础模型的少样本适应方法的共同缺点,并分析了域适应问题。从统计机器学习理论中跨域泛化的误差界限出发,我们推导了多模态基础模型的少样本适应误差界限,揭示了现有方法面临的主要挑战是上游和下游域分布的无效适应、模型选择的适应性不足以及数据和知识利用不足。
I. 多模态基础模型的预训练
近年来,大规模预训练模型已受到学术界和工业界的广泛关注。最初,基础模型预训练的相关工作主要集中在自然语言处理领域,在这个领域,如BERT [1]和GPT [17]这样的自监着学习语言模型展现出比传统方法更好的自然语言理解和生成能力。在计算机视觉领域,范式也从监督预训练转变为自监督预训练。自监督预训练的视觉模型性能显著提高,从最初基于数据增强的模型(如SimCLR [18]和MoCo [19])演变到最近基于随机掩蔽方法的模型(如MAE [20]和BEiT [21])。然而,预训练的语言模型无法接收视觉输入,导致它们无法将语言理解的优势扩展到多模态下游任务(如视觉问答VQA)。另一方面,用于视觉预训练的监督信号通常仅限于数据增强和随机掩蔽,这阻止了它们在开放世界中学习更丰富的语义表征。因此,我们最近见证了大规模预训练多模态模型的迅速发展,这些模型结合了视觉和语言模态,如表I所示。
II. 多模态基础模型的少样本适应方法
为了有效提高模型在特定领域的泛化性能,有必要使用有限的样本对多模态基础模型进行微调,使其具有更广泛的应用。这些方法可以定义为多模态基础模型的少样本适应方法。本章将分为四个部分,提供现有多模态基础模型方法的详细概述,即:基于提示的微调适应方法、基于适配器的微调适应方法、基于外部知识的适应方法,以及其他方法。
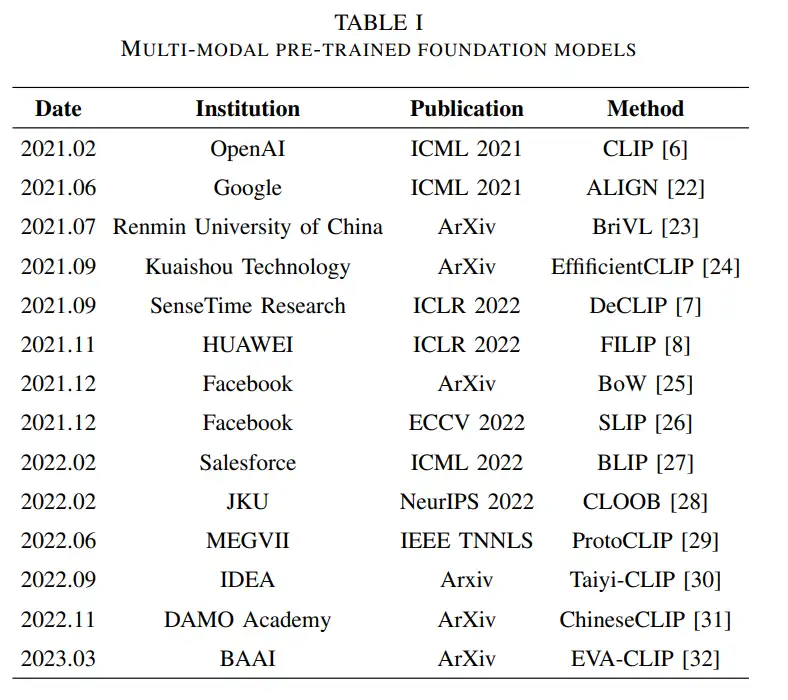
A. 基于提示的微调适应方法
- 文本提示基微调适应:在自然语言处理领域,基于提示的微调适应[34]–[38]是解决大型语言模型少样本泛化问题的经典方法。它涉及将文本输入的一部分作为可学习向量,并使用下游任务数据对其参数进行微调,使模型能够适应特定的下游任务。这种方法的优势在于它避免了文本提示的手动设计,有效地通过仅对模型输入的特定部分进行微调来减轻过拟合风险。受此启发,一些研究人员也开始为多模态基础模型设计基于提示的微调适应方法。CoOp [14]首次将提示学习的思想纳入多模态预训练基础模型的下游任务适应中。它使用可学习的词嵌入来自动构建上下文提示,而不是为每个任务手动设计提示模板。如图1所示,单个类别标签{object}被转换为综合文本提示“[V]1, [V]2, ..., [V]m, {object}”。其中,[V]i代表可调整的词向量。然后计算分类损失以使用下游任务数据微调这些词向量,使模型能够自主获取适应下游任务的文本输入。随后,Zhou等人[39]引入了条件性上下文优化(CoCoOp),该方法构建了一个元网络来学习图像的特征。这些特征然后与提示向量结合以增强CoOp在新类别数据上的泛化性能。为了有效利用预训练模型的零样本能力,Huang等人[40]提出了无监督提示学习(UPL)。它选择高置信度的零样本预测结果作为伪标签来监督提示向量的学习。类似地,Prompt-aligned Gradient(ProGrad)[41]使用零样本预测结果来约束模型梯度更新的方向,从而避免少样本模型与泛化知识之间的冲突,并减轻过拟合问题。然而,由于视觉信息的丰富多样性,学习仅一个文本提示难以匹配复杂的视觉数据。为解决这一问题,Chen等人[42]提出了使用最优传输的提示学习(PLOT)。它用于学习多个不同的文本提示,其中不同的文本提示被视为图像位置的描述,使用最优传输理论来匹配文本提示与局部图像特征。Lu等人[43]引入了提示分布学习(ProDA),以学习提示分布并从这些分布中采样不同的文本提示。此外,为了充分利用多任务数据之间的相关性,Ding等人[44]提出了用于提示调整的软上下文共享(SoftCPT),该方法设计了一个任务共享元网络,将预定义任务名称和可学习的元提示作为输入,以借助多任务数据微调提示。
- 视觉提示基微调适应:上述所有方法仅微调CLIP的文本部分,而CLIP作为多模态模型,视觉和文本两方面同等重要。仅微调文本提示无法改善视觉编码器提取特征的能力,提取的视觉特征可能与下游任务的目标特征不匹配。因此,受到文本提示微调适应的启发,一系列视觉提示微调适应方法应运而生。现有的视觉提示微调适应方法主要包括令牌级微调适应和像素级微调适应。视觉提示调整(VPT)[45]引入了以令牌形式的可学习视觉提示。类感知视觉提示调整(CAVPT)[46]在此基础上进一步包括一个交叉注意模块,使视觉提示更加关注下游任务的目标。与基于令牌的方法相反,Bahng等人[47]建议直接在图像周围以填充格式添加像素级视觉提示,以增强视觉提示。Wu等人[48]进一步提出了增强视觉提示(EVP),通过缩放和填充而不是直接在原始图像周围填充。
- 多模态提示基微调适应:除了单独学习文本和视觉提示外,还可以同时学习多模态提示,以更好地对齐文本和视觉特征。文本和视觉特征具有固有的差异,为了在学习多模态提示时加强它们之间的联系,多模态提示学习(MAPLE)[49]使用copula函数将文本提示转换为视觉提示。统一提示调整(UPT)[50]首先学习一个通用提示,然后将其分解为文本和视觉提示。另一方面,多任务视觉语言提示调整(MVLPT)[51]引入了多任务学习的概念,使用跨任务知识微调文本和视觉提示。
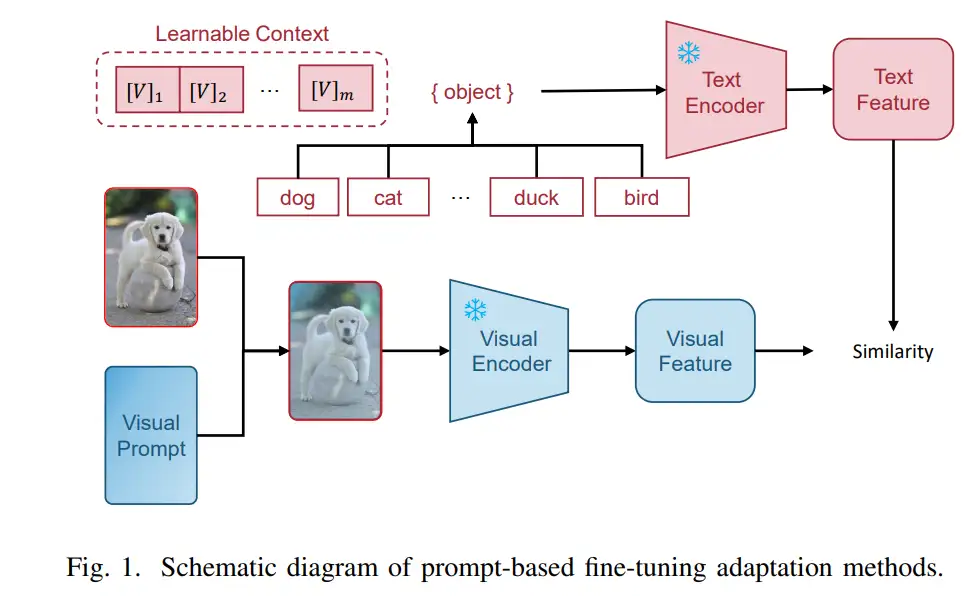
B. 基于适配器的微调适应方法
1. 单模态适配器基微调适应:在自然语言处理(NLP)领域,适配器的概念最初由谷歌团队于2019年引入,用于微调大型语言模型[52]。在下游任务训练中,该方法冻结原始语言模型的参数,仅更新作为适配器模块添加的少量参数。由于其参数效率高、设计灵活性和高鲁棒性等优点,这种方法近年来在NLP领域受到了广泛的研究关注[53]。最近,基于适配器的方法也被应用于计算机视觉领域的视觉变换器(ViTs)中。Jie等人[54]通过引入卷积旁路(Convpass)解决了ViTs中适配器结构缺乏归纳偏置的问题。此外,他们提出了因子调整(FacT,引用为[55]),以进一步提高参数效率的迁移学习效率,以满足实际应用中的存储约束。
2. 多模态适配器基微调适应:上述基于适配器的方法都适用于自然语言处理或计算机视觉中的单模态基础模型。近年来,基于适配器的方法也被扩展到多模态基础模型中,以增强下游泛化能力。Gao等人[15]引入了CLIP-Adapter,该适配器在冻结骨干网络后添加了一个全连接层适配器来学习额外知识。然后,它基于残差连接将这些知识与零样本预测结果合并,如图2所示。基于这些发展,张等人引入了Tip-Adapter[56]。该方法基于下游少样本训练数据构建分类器,并以线性加权方式将其预测与原始零样本分类器的结果结合,以增强模型的预测性能。SVL-Adapter[57]在适配器之前融合了一个预训练的自监督视觉编码器,以提取更鲁棒的视觉特征。然而,上述方法仅使用跨模态对比损失,没有考虑少样本数据集的视觉特定对比损失。为解决这一问题,彭等人[58]提出了语义引导的视觉适应(SgVA-CLIP),通过隐式知识蒸馏引导视觉适配器的参数更新,以确保图像-文本关系的一致性。为了增强适配器的跨模态交互能力,CALIP[59]利用注意力图融合文本和图像特征,并在融合前后插入两个可微调的线性层。此外,跨模态适配器(CMA)[60]和多模态视频适配器(MV-Adapter)[61]通过在两种模态之间共享适配器权重实现跨模态交互。这些方法考虑了单模态和多模态场景,但没有充分整合每种模态的优势。为解决这一问题,陆等人[62]提出了UniAdapter,以统一单模态和多模态适配器。
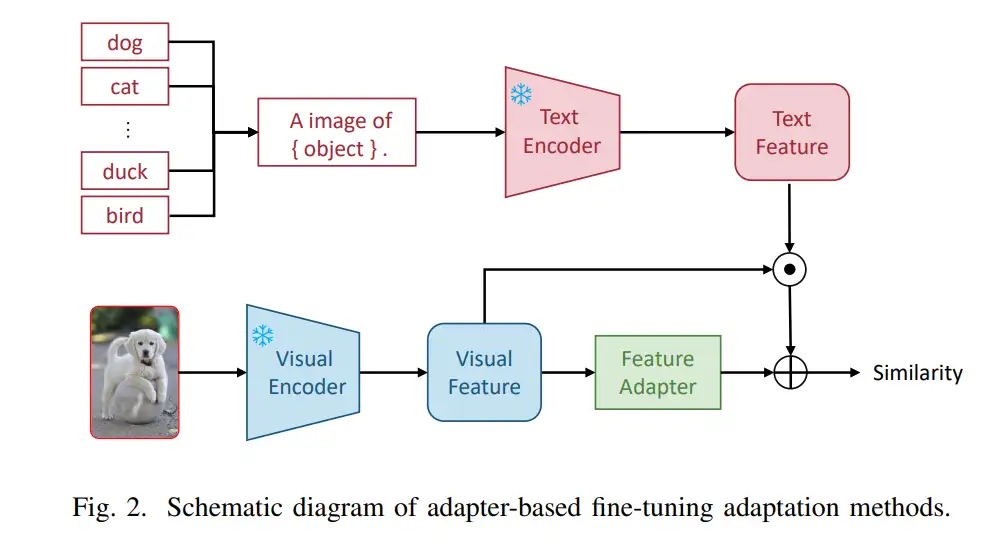
C. 基于外部知识的适应方法1. 基于外部知识的预训练方法:预训练基础模型通过从互联网上大量数据中挖掘相关信息,具有学习通用表征的能力。然而,在这些数据驱动的模型中,知识通常是隐性的,没有明确链接到人类对世界的理解或常识性知识。近年来,数据和知识驱动的预训练方法不断涌现,研究人员开始探索将更全面的外部知识,如知识图谱,融入基础模型中。这种整合旨在使这些模型更加鲁棒、可靠和可解释。ERNIE[63]融合了一个知识编码器,用于实体知识提取和异构信息融合。K-BERT[64]检索与模型输入相关的外部知识,并构建具有丰富上下文知识的句子树作为模型输入。近年来,一些工作也开始为多模态基础模型的预训练注入知识。例如,ERNIE-ViL[65]整合了来自场景图的知识,KM-BART[66]通过创建额外的预训练任务来模拟一般视觉知识,K-LITE[67]融合了包括WordNet和维基百科定义在内的各种外部知识源。
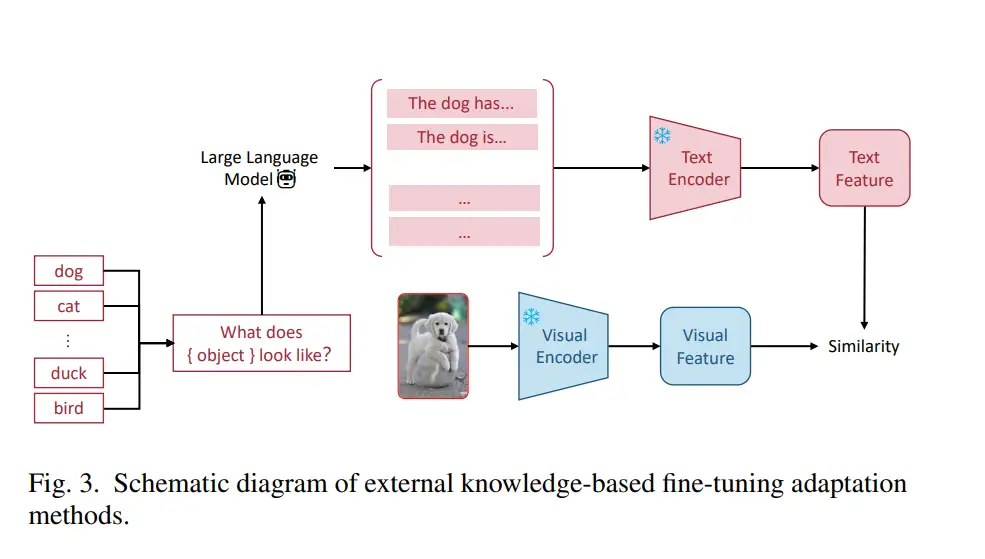
2. 基于外部知识的下游适应方法:上述方法在预训练阶段引入外部知识。然而,在数据样本有限的下游少样本适应场景中,也有必要增强外部知识以确保模型的性能。最常见的方法之一是通过查询大型语言模型为每个类别生成更丰富的文本描述。图3展示了这种方法的示例。通过语言模型定制提示(CuPL)[16]是第一个将外部知识融入多模态基础模型下游泛化过程的方法。CuPL通过向GPT-3提问生成每个类别的多个描述性陈述,丰富类别的语义,从而提高零样本分类性能。然而,CuPL使用GPT-3生成的句子可能存在描述性差和可靠性问题。为解决这些问题,Menon等人[68]进一步完善了基于GPT-3的知识增强过程。他们提示GPT-3以短语形式生成语义属性描述,增强了模型的可解释性。为了在可解释性和性能之间取得平衡,语言引导瓶颈(LaBo)[69]使用GPT-3生成大量候选特征描述符空间,同时考虑特征相对于其他类别的区分性和当前类别的覆盖率。它筛选出最佳子描述符空间以进行分类决策,从而揭示模型的决策逻辑。ELEVATER[70]还融合了来自GPT-3、WordNet和维基词典等来源的定义。实验结果表明,外部知识可以增强多模态基础模型的下游泛化性能。然而,不同知识来源有不同的侧重点和特性。例如,WordNet具有相对丰富和准确的知识,但覆盖率较低,而GPT-3具有更广泛的知识覆盖范围,但可能缺乏可靠性。此外,与上述使用外部知识增强文本语义的方法不同,SuS-X[71]专注于增强多模态模型的视觉样本。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
LSKA注意力 | 重新思考和设计大卷积核注意力,性能优于ConvNeXt、SWin、RepLKNet以及VAN
CVPR 2023 | TinyMIM:微软亚洲研究院用知识蒸馏改进小型ViT
ICCV2023|涨点神器!目标检测蒸馏学习新方法,浙大、海康威视等提出
ICCV 2023 Oral | 突破性图像融合与分割研究:全时多模态基准与多交互特征学习
HDRUNet | 深圳先进院董超团队提出带降噪与反量化功能的单帧HDR重建算法
南科大提出ORCTrack | 解决DeepSORT等跟踪方法的遮挡问题,即插即用真的很香
1800亿参数,世界顶级开源大模型Falcon官宣!碾压LLaMA 2,性能直逼GPT-4
SAM-Med2D:打破自然图像与医学图像的领域鸿沟,医疗版 SAM 开源了!
GhostSR|针对图像超分的特征冗余,华为诺亚&北大联合提出GhostSR
Meta推出像素级动作追踪模型,简易版在线可玩 | GitHub 1.4K星
CSUNet | 完美缝合Transformer和CNN,性能达到UNet家族的巅峰!