神经网络稀疏综述
1. 稀疏的概念
随着现代神经网络的规模不断提升,其消耗的内存,算力,能量都不断增加,这构成了在神经网络在实际应用中的瓶颈。如何尽可能的缩小网络同时又不损失其性能成为了一大神经网络方面的研究重点,目前常用的方法包括:剪枝,量化,网络结构搜索,知识蒸馏等。
我们现在讨论的神经网络稀疏与剪枝是紧密关联的,具体来说,剪枝即剪去神经网络中一些冗余的连接关系。由于神经元在神经网络中的连接在数学上表示为权重矩阵,因此剪枝的具体实现即将权重矩阵中一部分元素变为零元素。这些剪枝后具有大量零元素的矩阵被称为稀疏矩阵,反之绝大部分元素非零的矩阵被称为稠密矩阵。
最早的关于神经网络稀疏的讨论可以追溯到1990年,LeCun和同事们在AT&T贝尔实验室工作时便发表了论文提倡这种压缩网络的方法。2015年Han等人发表了一篇论文[1]提出了剪枝网络的三步方法论:1) 训练一个稠密网络 2) 以权重幅度代表其显著性,剪枝掉最不重要的权重 3)重新训练网络来微调这些剩下连接的权重。这项工作不仅在当时的深度学习模型上有效,甚至可以相比原模型达到更高的精度。
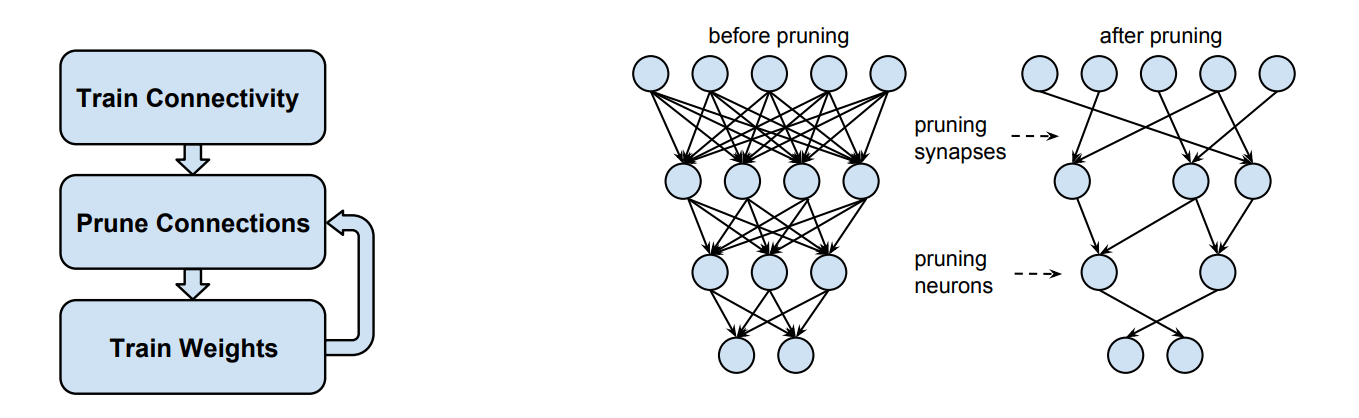
在ICLR2019上,Frankle和Carbin提出了彩票假设[2],他们的论文也是ICLR2019的best paper,该假设认为:任何随机初始化的稠密的前馈网络都包含具有如下性质的子网络——在独立进行训练时,初始化后的子网络在至多经过与原始网络相同的迭代次数后,能够达到跟原始网络相近的测试准确率。因此他们认为通过剪枝方法可以消除网络中超过90%的权重,大大减少存储需求并提升推理的计算性能同时不损失精度。与Han等人得到的结论不同,在彩票假设中,剪枝后的网络不是需要进行微调,而是将“中奖”的子网络重置为网络最初的权重后重新训练,最后得到的结果可以追上甚至超过原始的稠密网络。彩票假设最开始被认为非常疯狂,但现在已经被广泛接受——过参数化的稠密网络中包含了若干个稀疏的子网络,这些子网络性能各异,其中之一就是“中奖”的子网络,其性能超越了其他子网络,因此后续研究可以更加关注于如何有效的找到这一“中奖”的子网络。
这一领域后续又有大量的跟进工作,包括尝试在新的网络结构和数据集上验证彩票假设(原论文只在MNIST和CIFAR-10两个小数据集以及LeNet,Resnet-18,VGG-19这些早期网络模型上进行了实验),探索彩票假设提取出的“中奖”子网络的泛化性能,有没有更高效的获得“中奖”子网络的方式等。可以参考这篇文章。我们在这里不做进一步的讨论。
总结,我们在这一节讨论了剪枝这一重要的神经网络压缩方法的来源及其后续发展,并介绍了重要的彩票假设。通过剪枝方法剪去的网络连接在权重矩阵上表现为零元素,而高度剪枝后的网络权重矩阵内包含了大量的零元素,从而成为所谓的稀疏矩阵。从硬件的角度来看,利用这种稀疏矩阵的特性,我们可以大大减少其存储的消耗,并提升计算能效。接下来我们将讨论稀疏具体可以采取的几种方式。
2. 稀疏的方式
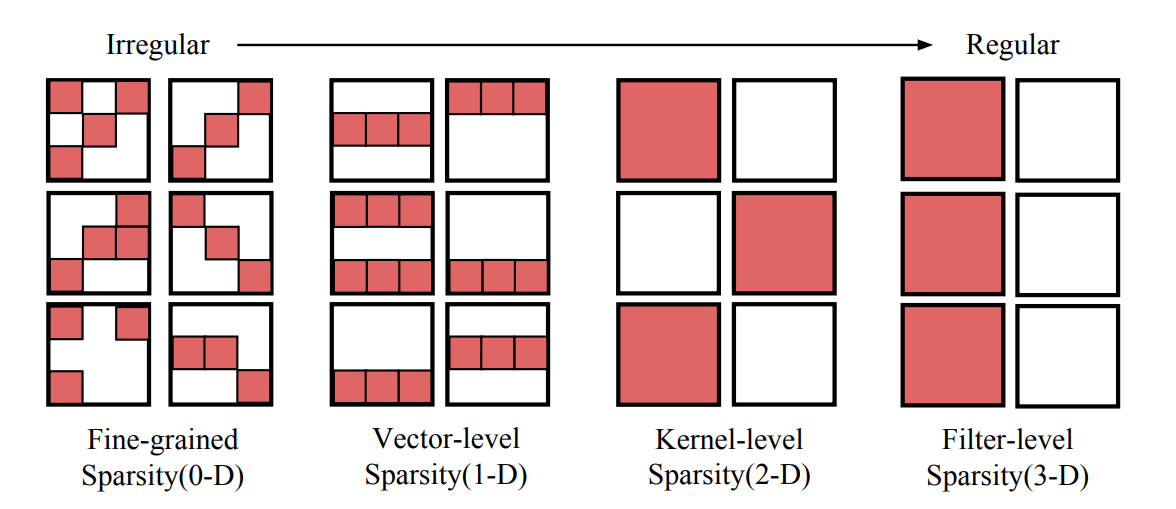
参考NeurIPS2021上Sun等人的分类方式[3],稀疏的方式首先可以按照结构化与非结构化进行区分为结构化稀疏和非结构化稀疏,结构化稀疏可以进一步区分为粗粒度结构化稀疏和细粒度结构化稀疏。如下图所示,(a)(b)(c)分别为非结构稀疏,粗粒度结构化稀疏和细粒度解构稀疏。
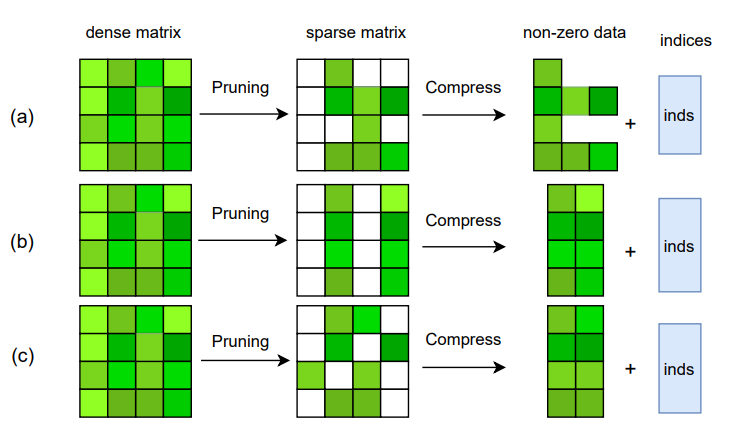
在介绍剪枝时我们提到一种朴素的方法就是剪去重要性比较低的权重,如果将权重的幅值视作重要性,那么就是将绝对值小于某一阈值的权重元素改为零。不管采用具体何种替换权重元素为零的方式,我们是没有先验的考虑这些权重元素的分布需要满足某种规律的,我们可能会删除权重矩阵中任意位置任意数量的元素——只要它们满足算法中的删除条件。
但非结构稀疏对于硬件实现并不友好,不确定的稀疏结构提高了硬件结构处理稀疏的复杂性,导致开销的增大,效率的降低。为了能够降低加速稀疏结构的硬件结构复杂度,提升计算性能,可以采用结构化稀疏方案。结构化稀疏方案即人工先验的设计好稀疏结构,例如保留多少权重,保留的权重在矩阵中的空间位置等。由于提前知道了非零权重的分布规律,硬件结构可以直接按照分布规律进行设计,简化了其设计复杂度。
结构化稀疏可以进一步划分为粗粒度结构化稀疏方案和细粒度结构化稀疏方案,粗粒度结构化稀疏方案一般会以较粗的粒度进行权重元素的删除(归零),例如以通道/块/条为单位进行结构化稀疏,可以理解成都是以某种连续的几何区域进行权重的删除,这种删除权重的连续几何区域面积越大,我们可以认为其粒度越粗。Mao等人在论文中针对CNN的稀疏粒度和网络最终的精确性的关联性进行了研究,并在AlexNet,VGG-16,GoogLeNet,ResNet-50,DenseNet-121等网络上进行了实验,从最终的实验结果来看,整体上网络的精度和稀疏粒度之间呈反相关性,在相等的稀疏度下,细粒度稀疏普遍能具有最佳的精度,其次是以条为单位几何区域进行元素删除的向量级稀疏,最后是以块为单位几何区域进行元素删除的核级稀疏[4]。
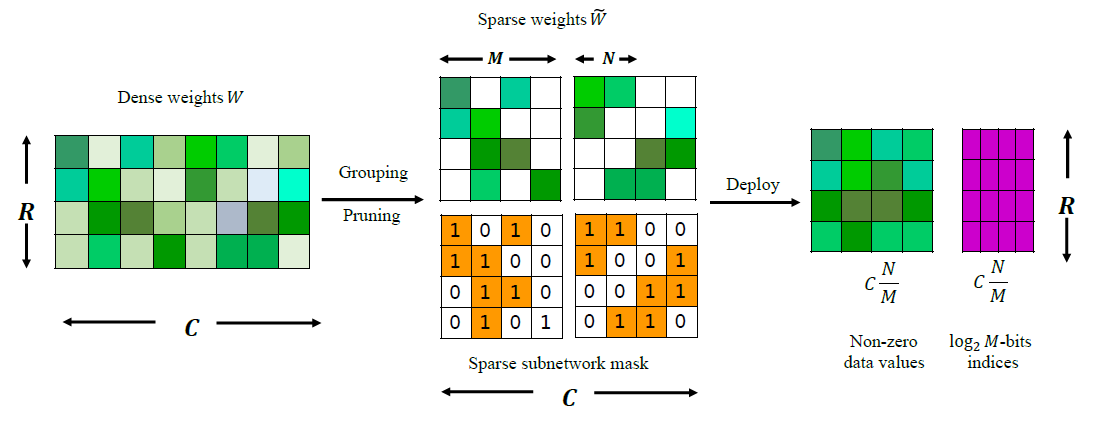
由于细粒度稀疏能够使得网络具有更好的精度,后续的研究者致力于如何实现细粒度结构化稀疏,Nvidia在2020年推出安培架构的A100显卡中引入的稀疏向量核心[5]为细粒度结构化稀疏提供了硬件基础,在此基础上Sun等人[3:1]和ICLR2021上的Zhou等人[6]都对N:M细粒度结构化稀疏方法进行了研究,所谓N:M细粒度结构化稀疏即在M个连续的权重值中固定有N个非零值,其余元素均为零值,例如下图中N=2,M=4的N:M稀疏(2:4稀疏)。N:M稀疏的权重矩阵可以进行压缩存储,仅保留所有的非零元素,再辅以一个indices矩阵指示非零元素在原矩阵中的空间位置。从实验结果上来看,采用N:M细粒度结构化稀疏方案的模型在权重存储量和计算量大减的同时取得了比肩甚至超过稠密的原网络的推理精度。
此外还有一层考虑是采用全局稀疏还是层级稀疏。全局稀疏即对整个网络结构都应用一样的稀疏策略,例如对于N:M细粒度结构化稀疏来说就是整个网络采用固定的N和M,层级稀疏则意味着对网络的不同层级应用不同的稀疏策略或者稀疏度。在Sun等人[3:2]的实验中,他们对比了固定采用2:16稀疏的全局稀疏和采用N:16层级稀疏(N根据不同层次的情况进行调整),最终的结果是层级稀疏具有超过全局稀疏的表现,这实际上也是可以理解的,网络浅层和网络深层处理的信息层次就有偏差,以CNN为例,浅层往往提取的是局部图形细节信息,深层往往提取到的是更全局化的语义信息,因此两者受到稀疏度的影响自然会有所不同。
A100上的硬件固定为2:4稀疏模式[5:1],具体硬件实现上,如下图所示,在Sparse Tensor Core中通过上述的indices矩阵控制多路选通器挑选的非零权重元素对应的激活矩阵元素进行向量点积从而得到结果矩阵的元素值,固定的稀疏比例大大简化了多路复用器的硬件设计。但固定的2:4稀疏也对算法造成了一些限制,在部分层次上可以应用更小的N:M来实现更高的稀疏度(比如2:8,1:16)从高提升压缩率进一步节省容量;在部分层次上需要引用更高的N:M来确保推理精度不会产生严重的损失,即之前讨论的全局稀疏和层级稀疏的问题。
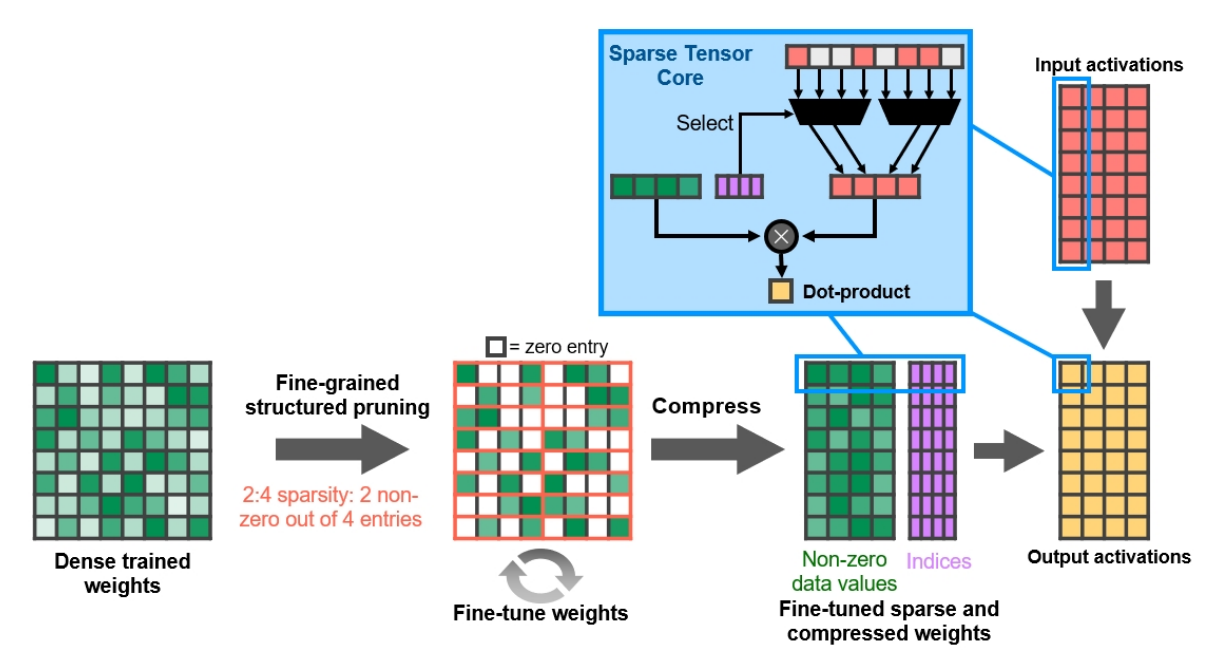
总结,这节我们介绍了非结构化稀疏,粗粒度结构化稀疏和细粒度结构化稀疏三种稀疏方案,以及对比了全局稀疏和层级稀疏。总体来说,细粒度稀疏可以在相同稀疏度下取得比粗粒度稀疏取得更好的推理精度,而结构化稀疏相比非结构化稀疏更加硬件友好,便于加速硬件实现。层级稀疏方案可以为不同层级匹配不同的稀疏度,相比整个网络全部采用相同稀疏度的全局稀疏方案,层级稀疏可以取得更优的性能,但硬件实现上也会更复杂。目前主流的Nvidia A100显卡使用是2:4细粒度结构化全局稀疏方案。需要注意的是我们上面讨论的所有稀疏都围绕权重矩阵展开,因为剪枝方法最开始关注的就是如何剪去网络中的连接关系,这种连接关系就体现为权重。但我们知道网络的运算是由权重和激活两者参与的运算,因此下一节我们将讨论激活稀疏。
3. 激活稀疏
相比权重稀疏(剪枝),激活稀疏是动态且依赖于输入的,这使得实现激活稀疏具有更高的难度。类比权重稀疏的概念,我们知道激活稀疏关注的问题是如何删除激活矩阵中不重要的非零元素,从而使得激活矩阵变得更加稀疏,提升存储效率和推理性能。在ICML2020上,Kurtz等人[7]对CNN的激活稀疏进行了观察,首先由于CNN中普遍采用的ReLU激活函数,激活矩阵中自然的引入了稀疏性,但ReLU函数形成的稀疏激活矩阵仍然可能存在冗余,因此他们提出可以在预训练好的网络中引用FATReLU激活函数,设置一个变化的阈值来动态的提升激活矩阵的稀疏度,FATReLU激活函数定义如下:
实验结果显示这一方法可以在不降低推理精度的情况下进一步提升激活稀疏度,从而实现更小的存储占用和更高的推理性能。Kurtz等人的方法产生的激活矩阵是非结构化稀疏的,这会增大硬件设计的复杂度,在ECCV2022上,Ruth等人[8]在Kurtz等人的基础上进一步研究了如何实现N:M的细粒度结构化激活稀疏。结合使用N:M权重稀疏和激活稀疏的情况下,能够在少量降低精度的基础上减少50%到80%以上的计算量(N:M从2:4取到2:16,在ResNet-18,ResNet-50,ImageNet数据集上进行了实验)。
硬件上也有研究在关注同时使用权重和激活的双向稀疏的方案,numenta的Kevin等人[9]提出一种k-WTA的方法来实现激活稀疏,具体方法为对稠密的激活矩阵的元素进行排序,仅保留前k个幅值最大的元素,其他元素归零。由于是细粒度的方案,需要通过Indices选择非零的对应权重矩阵元素与激活矩阵元素进行运算。权重稀疏则采用了一种粗粒度结构化稀疏方案。
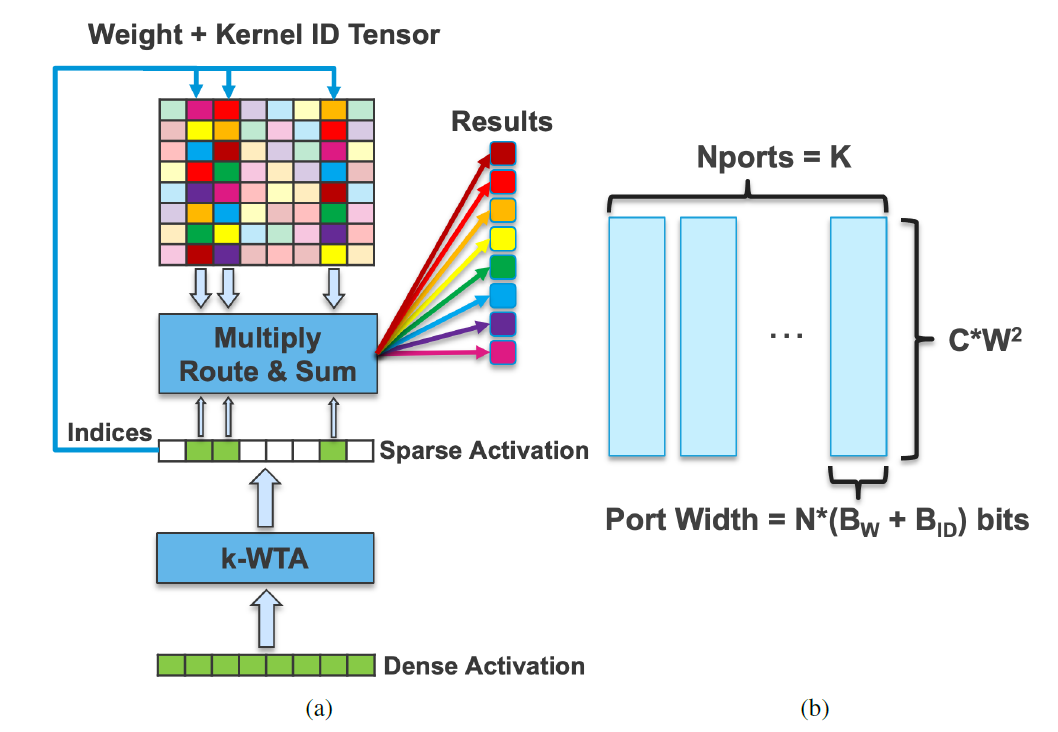
在ISCA2021上,Wang等人[10]等人提出的双向稀疏Tensor Core则针对激活和权重矩阵双细粒度非结构稀疏的情况下,通过bitmap压缩编码和外积计算模式完成双向稀疏矩阵的计算。
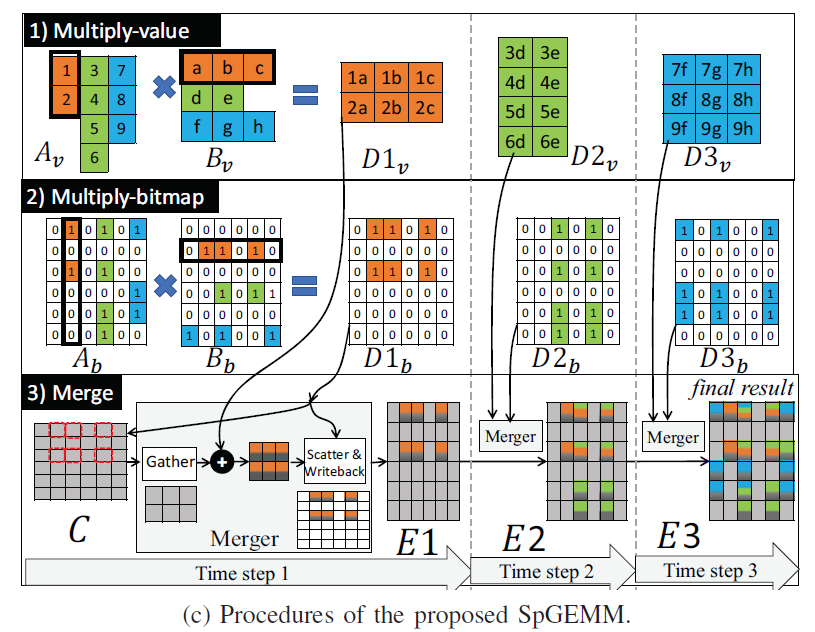
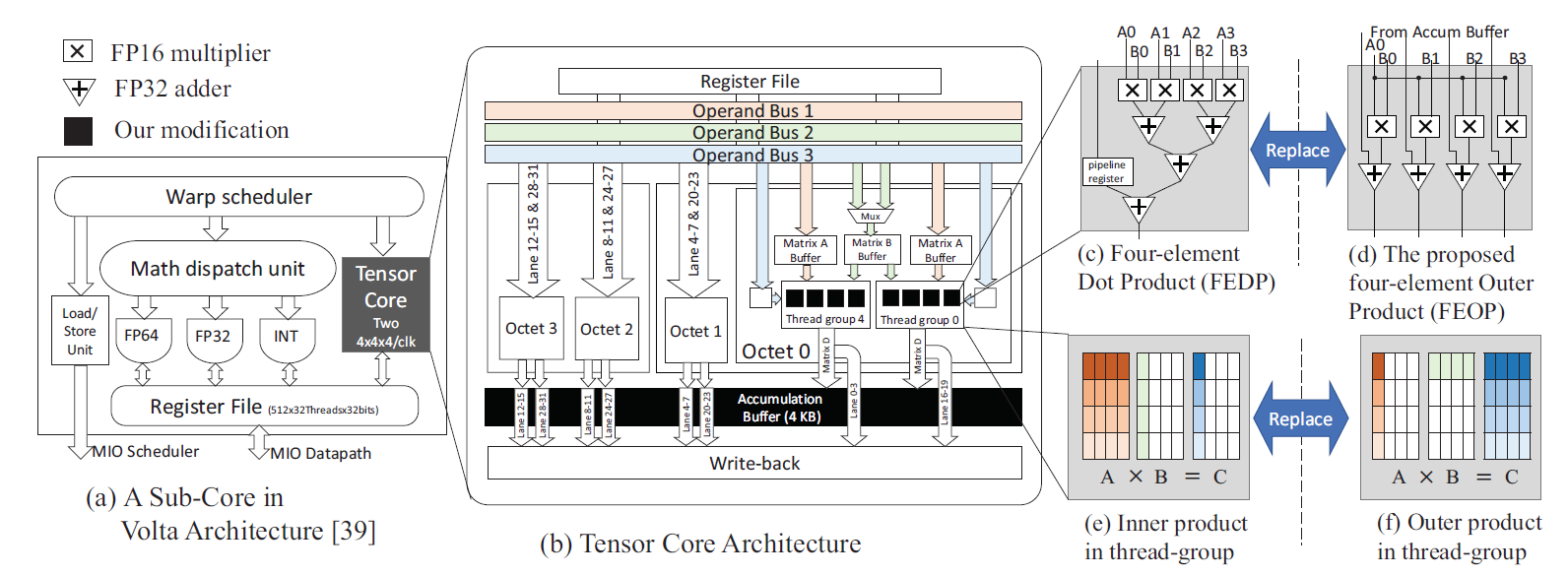
对比目前已有的Nvidia伏特架构中的Tensor Core,Wang等人只将原有的四元素内积单元替换为了四元素外积单元,做出了尽可能少的硬件修改。除了双向稀疏矩阵乘法之外,他们也研究了所提出的硬件方案在通过im2col方法加速卷积运算时的性能表现。
本小节我们介绍了激活稀疏上算法和硬件的研究情况。由于激活稀疏是动态且依赖于输入的,其处理难度胜于权重稀疏。算法上由于采用了ReLU激活函数,CNN等网络结构天然具有稀疏性,通过改造激活函数可以进一步提升激活矩阵的稀疏度,从而提升计算性能。此外权重稀疏上使用的N:M稀疏方法也可以在激活稀疏上有所应用。同时利用权重稀疏和激活稀疏的硬件结构在设计上更加具有难度,但也可以获得更大的稀疏度,从而获得更好的性能表现。我们上述讨论的例子都主要围绕CNN架构,Transformer架构是近几年兴起的一种新的网络架构,并在自然语言处理,计算机视觉,多模态等领域展现了极为强大的性能,下一节我们将讨论Transformer中的稀疏。
4. Transformer的稀疏
Transformer主要由注意力层和前馈层组成,其中注意力层的计算规则为:
其中\(QK^T/\sqrt{d_k}\)为注意力分数,\(softmax(QK^T/\sqrt{d_k})\)为注意力权重。OpenAI的Child等人[11]研究发现,在实际的网络中注意力权重存在明显的冗余,对其进行分解后可以将自注意力机制原有的\(\mathcal{O}(n^2)\)计算复杂度降低到\(\mathcal{O}(n\sqrt{n})\),从而使得硬件平台在同等存储容量和算力的情况下可以建模更长的序列,这项研究为后续探索自注意力的稀疏提供了基础。
在ICLR2020上,Zhao等人[12]进一步研究发现保留少量注意力权重参与注意力运算可以在几乎不影响模型性能的同时大大增大注意力权重的稀疏度,具体来说,在计算完注意力分数\(P=QK^T/\sqrt{d_k}\)后,在送入softmax函数之前,可以对注意力分数进行排序,对于注意力权重矩阵,每行仅保留前\(k\)大的元素,剩余的元素全部取为负无穷,即:
之后将\(\mathcal{M}(P,k)_{ij}\)再送入softmax函数进行计算,此时负无穷的元素经过运算后全部为零,仅有前\(k\)大的注意力权重得到了保留,之后再用注意力权重与\(V\)进行运算即可,即:
他们在机器翻译,图像分割,语言模型等任务上测试了模型的效果,结果显示在模型性能与前面的sota可以比肩的同时,模型的速度得到了显著的提升。上述计算的结构图如下图所示:
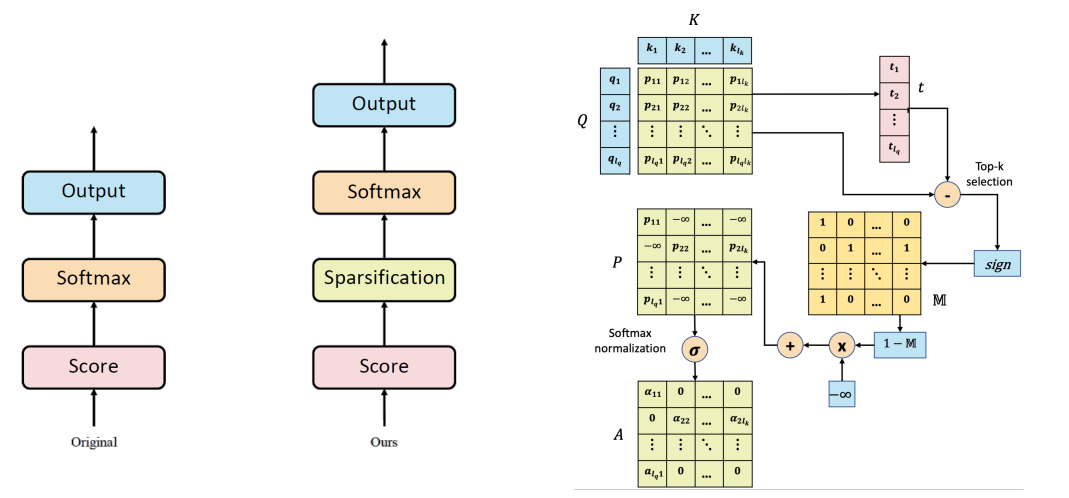
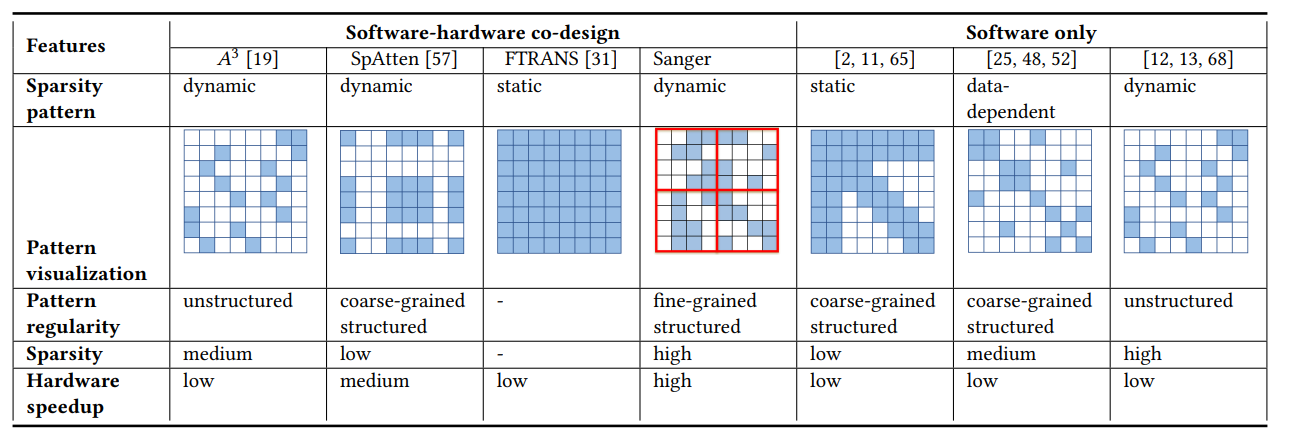
针对注意力权重的稀疏性,硬件上学者们也在探索对应的加速器设计方法,例如在MICRO2021上,Lu等人[13]通过软硬件协同,将注意力权重以细粒度结构化稀疏的方式进行了处理,从而得到了高的稀疏度和高的加速比。
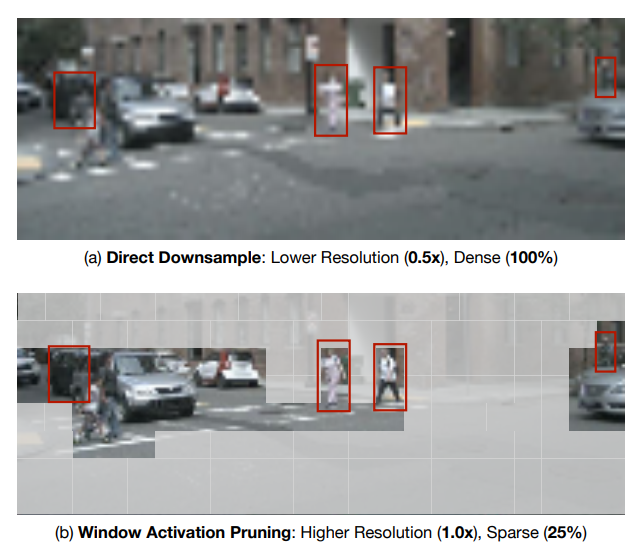
总体来说,由于注意力运算的特殊性,相比传统的静态权重剪枝,注意力权重类似于激活,也是动态且依赖于输入的,如何充分的利用好注意力权重稀疏仍然是一个待研究解决的问题。除了注意力权重的稀疏外,在CVPR2023上,Chen等人[14]研究了在Vision Transformer中进行激活剪枝的方法,通过以窗口为单位进行激活剪枝,可以获得更高分辨率的有效激活值,从而同时提升模型性能与降低计算开销,其方法的基本思想如下图所示:
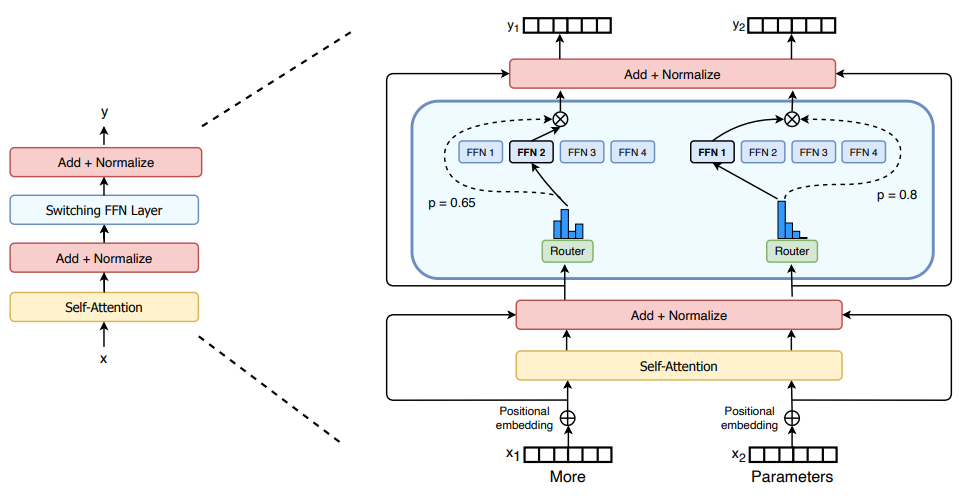
此外,由于大模型技术的快速发展,为了降低硬件开销,研究者们一直在积极推动混合专家模型(MoE)的发展,例如谷歌研究团队在2022年发表的Swith Transformer[15],具体来说,混合专家模型理论认为在目前这些能够执行多种任务的大模型中存在若干个”专家“子模型,这些子模型各自在不同的任务中起到了关键的作用。这种思想可以说和我们之前提到的彩票假设不谋而合。因此在进行模型推理时,我们可以通过路由算法,将任务交给具体的某个擅长此类任务的”专家“子模型,而其他的子模型可以不参与运算。从某种角度来说,这是一种比我们上面讨论的更高维度的稀疏方法,不仅是从权重矩阵和激活矩阵的冗余元素考虑问题,而是直接以子模型为粒度进行稀疏,从结果上来说同样可以实现维持模型整体性能的同时,大大降低运行模型的硬件开销。
本小节中我们介绍了Transformer模型里的注意力权重稀疏与激活稀疏,由于其独特的计算方式,注意力权重与之前讨论的静态权重不同,而是和激活类似,是动态且依赖于输入的。此外我们也简单介绍了Transformer中的激活剪枝,以及混合专家模型。
5. 总结
我们对稀疏的总结到此告一段落,如何利用好稀疏,以实现更高的理论算力一直是存内计算领域的研究重点之一,作为一个该领域的研究者,我暂时还没有发现一篇好的文章对稀疏性的来龙去脉做一个较为完整的概况,因此花费了一些时间来撰写此文。从文章中我们发现稀疏是一个需要软硬件协同发力才能解决好的问题,例如算法上研究了N:M细粒度结构化稀疏以便于硬件加速的实现。随着AI模型的能力越来越强劲,其所需要的算力水平也急速增长,为了应对这一挑战,算法和硬件的学者们需要携手共同努力。
引用
文章重点参考了"稀疏神经网络系列"和"The Case for Sparsity in Neural Networks",感谢这两位作者。
"Learning both Weights and Connections for Efficient Neural Networks" https://doi.org/10.48550/arXiv.1506.02626 ↩︎
"The lottery ticket hypothesis: Finding sparse, trainable neural networks."https://doi.org/10.48550/arXiv.1803.03635 ↩︎
Sun, Wei, et al. "DominoSearch: Find layer-wise fine-grained N: M sparse schemes from dense neural networks." Advances in Neural Information Processing Systems 34 (2021): 20721-20732. ↩︎ ↩︎ ↩︎
H. Mao et al., "Exploring the Granularity of Sparsity in Convolutional Neural Networks," 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 2017, pp. 1927-1934, doi: 10.1109/CVPRW.2017.241. ↩︎
"Ronny Krashinsky and Olivier Giroux et al. Nvidia Ampere Sparse Tensor Core. URL: https://developer.nvidia.com/blog/nvidia-ampere-architecture-in-depth/." ↩︎ ↩︎
"Learning N:M Fine-grained Structured Sparse Neural Networks From Scratch" https://arxiv.org/abs/2102.04010 ↩︎
Kurtz, M., Kopinsky, J., Gelashvili, R., Matveev, A., Carr, J., Goin, M., Leiserson, W.M., Nell, B., Shavit, N., & Alistarh, D. (2020). Inducing and Exploiting Activation Sparsity for Fast Neural Network Inference. ↩︎
Ruth Akiva-Hochman, Shahaf E. Finder, Javier S. Turek, Eran Treister: Searching for N:M Fine-grained Sparsity of Weights and Activations in Neural Networks. ECCV Workshops (7) 2022: 130-143 ↩︎
"Two Sparsities Are Better Than One: Unlocking the Performance Benefits of Sparse-Sparse Networks" https://doi.org/10.48550/arXiv.2112.13896 ↩︎
Y. Wang, C. Zhang, Z. Xie, C. Guo, Y. Liu and J. Leng, "Dual-side Sparse Tensor Core," 2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA), Valencia, Spain, 2021, pp. 1083-1095, doi: 10.1109/ISCA52012.2021.00088. ↩︎
“Generating Long Sequences with Sparse Transformers” https://doi.org/10.48550/arXiv.1904.10509 ↩︎
"Explicit Sparse Transformer: Concentrated Attention Through Explicit Selection" https://doi.org/10.48550/arXiv.1912.11637 ↩︎
Liqiang Lu, Yicheng Jin, Hangrui Bi, Zizhang Luo, Peng Li, Tao Wang, and Yun Liang. 2021. Sanger: A Co-Design Framework for Enabling Sparse Attention using Reconfigurable Architecture. In MICRO-54: 54th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO '21). Association for Computing Machinery, New York, NY, USA, 977–991. https://doi.org/10.1145/3466752.3480125 ↩︎
"SparseViT: Revisiting Activation Sparsity for Efficient High-Resolution Vision Transformer" https://doi.org/10.48550/arXiv.2303.17605 ↩︎
"Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity" https://doi.org/10.48550/arXiv.2101.03961 ↩︎