1. 连续动作空间VS离散动作空间
【离散动作空间】Q表格、SARSA、on-policy以及off-policy、Q-learing
https://blog.csdn.net/zbp_12138/article/details/106837306
【连续动作空间】
用神经网络的方法来求解
https://blog.csdn.net/zbp_12138/article/details/106854557
2. on-policy与off-policy对比

on-policy优化的实际上是它实际执行的策略,用下一步一定会执行的动作action来优化Q表格,所以on-policy其实只存在一种策略 ,用同一种策略去选取和优化
off-policy实际上有两种不同的策略,期望得到最佳的目标策略和大胆探索的行为策略
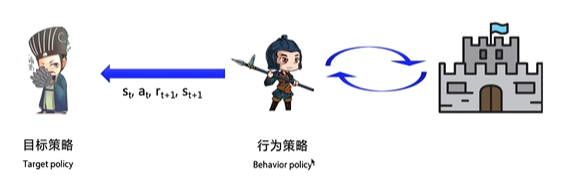
off-policy通过行为策略,把所有可能的策略输入目标策略,这里输入给目标策略的数据里不需要at + 1
,因为目标策略不需要管下一步要往哪里走,它只选择收益最大的策略行为策略就像是一位天不怕地不怕的战士,可以在环境里面尝试所有的动作,并将得到的经验交给目标策略学习。
所以目标策略就像是一个在后方指挥的军师,它可以根据经验学习到最优的策略
3. DDPG相关论文实现
DDQN+DDPG)Deep_Reinforcement_Learning_for_Computation_and_Communication_Resource_Allocation_in_Multiaccess_MEC_Assisted_Railway_IoT_Networks.
file:///D:/01%20%E6%96%87%E7%8C%AE%E5%9D%9A%E6%9E%9C%E4%BA%91%E5%90%8C%E6%AD%A5/%E5%BC%80%E9%A2%98%E6%96%B9%E5%90%91_%E8%AE%BA%E6%96%87%E7%A0%94%E8%AF%BB_%E8%B0%83%E7%A0%94/00%20%E6%9A%82%E5%AE%9A%E6%96%B9%E5%90%91_6G+%E7%A9%BA%E5%A4%A9%E5%9C%B0%E4%B8%80%E4%BD%93%E5%8C%96%E7%BD%91%E7%BB%9C+%E7%94%B5%E5%8A%9B%E7%89%A9%E8%81%94%E7%BD%91(%E4%B8%BB%E8%A6%81%E9%83%A8%E5%88%86)/03%E4%BB%BB%E5%8A%A1%E5%8D%B8%E8%BD%BD%E7%9B%B8%E5%85%B3/DDPG(%E6%B7%B1%E5%BA%A6%E7%A1%AE%E5%AE%9A%E6%80%A7%E6%A2%AF%E5%BA%A6)+%E5%8D%B8%E8%BD%BD+DRL/%EF%BC%88DDQN+DDPG%EF%BC%89Deep_Reinforcement_Learning_for_Computation_and_Communication_Resource_Allocation_in_Multiaccess_MEC_Assisted_Railway_IoT_Networks%20zh.pdf
4. MADDPG相关资料
https://zhengbopei.blog.csdn.net/article/details/107440531?spm=1001.2014.3001.5502