import os
import pandas as pd
# 修改工作路径到指定文件夹 os.chdir("D:/CourseAssignment/AI/CollectWebDate/") # 第一种连接方式 from sqlalchemy import create_engine engine = create_engine('mysql+pymysql://root:123456@localhost:3306/test?charset=utf8') sql = pd.read_sql('all_gzdata', engine, chunksize = 10000) # 第二种连接方式 import pymysql as pm con = pm.connect(host='localhost', user='root', password='123456',database='test',charset='utf8') data = pd.read_sql('select * from all_gzdata',con=con) con.close() #关闭连接 # 保存读取的数据 data.to_csv('./tmp/all_gzdata.csv', index=False, encoding='utf-8')
导入sql文件并将数据以csv格式保存到工作目录指定文件夹下
分析网页类型
对原始数据中用户点击的网页类型进行统计分析
import pandas as pd from sqlalchemy import create_engine engine = create_engine('mysql+pymysql://root:123456@localhost:3306/test?charset=utf8') sql = pd.read_sql('all_gzdata', engine, chunksize = 10000) # 分析网页类型 counts = [i['fullURLId'].value_counts() for i in sql] #逐块统计 counts = counts.copy() counts = pd.concat(counts).groupby(level=0).sum() # 合并统计结果,把相同的统计项合并(即按index分组并求和) counts = counts.reset_index() # 重新设置index,将原来的index作为counts的一列。 counts.columns = ['index', 'num'] # 重新设置列名,主要是第二列,默认为0 counts['type'] = counts['index'].str.extract('(\d{3})') # 提取前三个数字作为类别id counts_ = counts[['type', 'num']].groupby('type').sum() # 按类别合并 counts_.sort_values(by='num', ascending=False, inplace=True) # 降序排列 counts_['ratio'] = counts_.iloc[:,0] / counts_.iloc[:,0].sum() print(counts_)
num ratio type 101 411665 0.491570 199 201426 0.240523 107 182900 0.218401 301 18430 0.022007 102 17357 0.020726 106 3957 0.004725 103 1715 0.002048
因此,点击与咨询相关(网页类型为101)的记录占了49.16%,其他类型(网页类型为199)占比24%左右,知识相关(网页类型为107)占比22%左右。根据统计结果对用户点击的页面类型进行排名,然后进一步对咨询类别内部进行统计分析
# 因为只有107001一类,但是可以继续细分成三类:知识内容页、知识列表页、知识首页 def count107(i): #自定义统计函数 j = i[['fullURL']][i['fullURLId'].str.contains('107')].copy() # 找出类别包含107的网址 j['type'] = None # 添加空列 j['type'][j['fullURL'].str.contains('info/.+?/')]= '知识首页' j['type'][j['fullURL'].str.contains('info/.+?/.+?')]= '知识列表页' j['type'][j['fullURL'].str.contains('/\d+?_*\d+?\.html')]= '知识内容页' return j['type'].value_counts() # 注意:获取一次sql对象就需要重新访问一下数据库(!!!) #engine = create_engine('mysql+pymysql://root:123456@localhost:3306/test?charset=utf8') sql = pd.read_sql('all_gzdata', engine, chunksize = 10000) counts2 = [count107(i) for i in sql] # 逐块统计 counts2 = pd.concat(counts2).groupby(level=0).sum() # 合并统计结果 counts2
type 知识内容页 164243 知识列表页 9656 知识首页 9001 Name: count, dtype: int64
#计算各个部分的占比 res107 = pd.DataFrame(counts2) res107
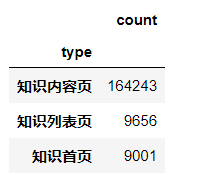
# res107.reset_index(inplace=True) res107.index.name= '107类型' #行名更改 res107
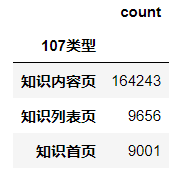
res107.rename(columns={'count':'num'}, inplace=True) #列名更改
res107
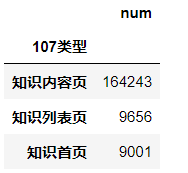
#计算百分比
res107['比例'] = res107['num'] / res107['num'].sum() res107.reset_index(inplace = True) print(res107)
107类型 num 比例 0 知识内容页 164243 0.897993 1 知识列表页 9656 0.052794 2 知识首页 9001 0.049213
初步分析可得用户都喜欢通过浏览问题方式找到自己需要的信息,而不是以提问的方式或者查看长篇内容的方式寻找信息。对原始数据的网址中带“?”的数据进行统计
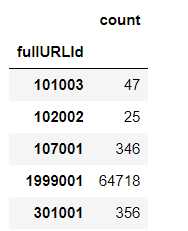
def countquestion(i): # 自定义统计函数 j = i[['fullURLId']][i['fullURL'].str.contains('\?')].copy() # 找出类别包含107的网址 return j engine = create_engine('mysql+pymysql://root:123456@localhost:3306/test?charset=utf8') sql = pd.read_sql('all_gzdata', engine, chunksize = 10000) counts3 = [countquestion(i)['fullURLId'].value_counts() for i in sql] counts3 = pd.concat(counts3).groupby(level=0).sum() counts3
fullURLId 101003 47 102002 25 107001 346 1999001 64718 301001 356 Name: count, dtype: int64
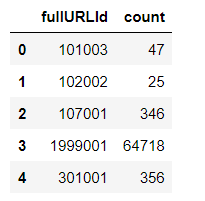
# 求各个类型的占比并保存数据 df1 = pd.DataFrame(counts3) df1
df1.reset_index(inplace = True)
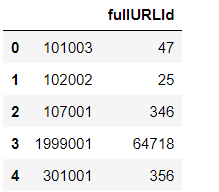
df1
#列名规范 df1.rename(columns={'fullURLId':''}, inplace=True) df1.rename(columns={'count':'fullURLId'}, inplace=True) df1
#百分比计算 df1['perc'] = df1['fullURLId']/df1['fullURLId'].sum()*100 df1.sort_values(by='fullURLId',ascending=False,inplace=True) df1.round(4)
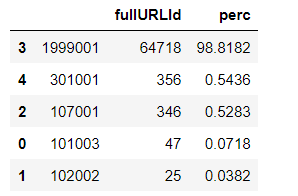
可得,网址中带“?”的记录一种有64718条,且不仅仅出现在其他类别中,同时也会出现在咨询内容页和知识内容页中,但在其他类型(1999001)中占比最高,可达98.82%。因此需要进一步分析其类型内部的规律
def page199(i): #自定义统计函数 j = i[['fullURL','pageTitle']][(i['fullURLId'].str.contains('199')) & (i['fullURL'].str.contains('\?'))] j['pageTitle'].fillna('空',inplace=True) j['type'] = '其他' # 添加空列 j['type'][j['pageTitle'].str.contains('法律快车-律师助手')]= '法律快车-律师助手' j['type'][j['pageTitle'].str.contains('咨询发布成功')]= '咨询发布成功' j['type'][j['pageTitle'].str.contains('免费发布法律咨询' )] = '免费发布法律咨询' j['type'][j['pageTitle'].str.contains('法律快搜')] = '快搜' j['type'][j['pageTitle'].str.contains('法律快车法律经验')] = '法律快车法律经验' j['type'][j['pageTitle'].str.contains('法律快车法律咨询')] = '法律快车法律咨询' j['type'][(j['pageTitle'].str.contains('_法律快车')) | (j['pageTitle'].str.contains('-法律快车'))] = '法律快车' j['type'][j['pageTitle'].str.contains('空')] = '空' return j # 注意:获取一次sql对象就需要重新访问一下数据库 engine = create_engine('mysql+pymysql://root:123456@localhost:3306/test?charset=utf8') sql = pd.read_sql('all_gzdata', engine, chunksize = 10000)# 分块读取数据库信息 #sql = pd.read_sql_query('select * from all_gzdata limit 10000', con=engine) counts4 = [page199(i) for i in sql] # 逐块统计 counts4 = pd.concat(counts4) d1 = counts4['type'].value_counts() d1
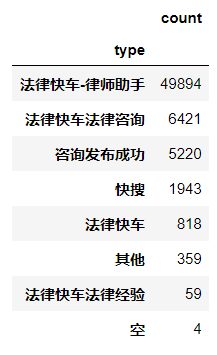
type 法律快车-律师助手 49894 法律快车法律咨询 6421 咨询发布成功 5220 快搜 1943 法律快车 818 其他 359 法律快车法律经验 59 空 4 Name: count, dtype: int64
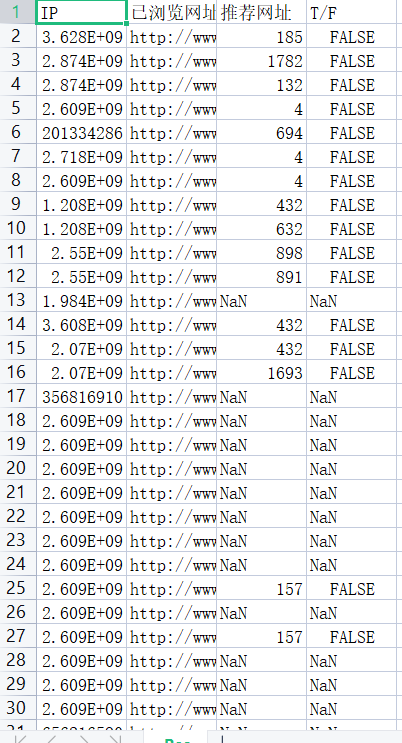
由此可得,在1999001类型中,标题为“快车—律师助手”这类信息占比为77.09%,这类页面是律师的登录页面。访问记录中有一部分用户并没有点击具体的页面,这类网页以“.html”后缀结尾,且大部分时目录网页,这样的用户可以称为“瞎逛”,漫无目的,总共有165654条记录,统计过程如下
d2 = counts4[counts4['type']=='其他'] d2

df1_ = pd.DataFrame(d1)
df1_
# 求各个部分的占比并保存数据 df1_ = pd.DataFrame(d1) df1_['perc'] = df1_['count']/df1_['count'].sum()*100 df1_.sort_values(by='type',ascending=False,inplace=True) df1_

def xiaguang(i): #自定义统计函数 j = i.loc[(i['fullURL'].str.contains('\.html'))==False, ['fullURL','fullURLId','pageTitle']] return j # 注意获取一次sql对象就需要重新访问一下数据库 engine = create_engine('mysql+pymysql://root:123456@localhost:3306/test?charset=utf8') sql = pd.read_sql('all_gzdata', engine, chunksize = 10000)# 分块读取数据库信息 counts5 = [xiaguang(i) for i in sql] counts5 = pd.concat(counts5) xg1 = counts5['fullURLId'].value_counts() xg1
fullURLId 1999001 117124 107001 17843 102002 12021 101001 5603 106001 3957 102001 2129 102003 1235 301001 1018 101009 854 102007 538 102008 404 101008 378 102004 361 102005 271 102009 214 102006 184 101004 125 101006 107 101005 63 Name: count, dtype: int64
# 求各个部分的占比 xg_ = pd.DataFrame(xg1) xg_.reset_index(inplace=True) xg_.columns= ['index', 'num'] xg_['perc'] = xg_['num']/xg_['num'].sum()*100 xg_.sort_values(by='num',ascending=False,inplace=True) xg_['type'] = xg_['index'].str.extract('(\d{3})') #提取前三个数字作为类别id xgs_ = xg_[['type', 'num']].groupby('type').sum() #按类别合并 xgs_.sort_values(by='num', ascending=False,inplace=True) #降序排列 xgs_['percentage'] = xgs_['num']/xgs_['num'].sum()*100 print(xgs_.round(4))
num percentage type 199 117124 71.2307 107 17843 10.8515 102 17357 10.5559 101 7130 4.3362 106 3957 2.4065 301 1018 0.6191
可以看出,小部分网页类型是与知识、咨询相关的,大部分网页类型是与地区、律师和事务所相关的,这类用户可能是找律师服务的,也可能是“瞎逛”的。记录这一些与分析目标无关数据的规则,有利于对数据进行清洗。
分析网页点击次数
统计原始数据用户浏览网页次数的情况
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/test?charset=utf8') sql = pd.read_sql('all_gzdata', engine, chunksize = 10000) #统计点击次数 click_count = [i['realIP'].value_counts() for i in sql] #分块统计各个IP的出现次数 count6 = pd.concat(click_count).groupby(level = 0).sum() #合并统计结果,level=0表示按index分组 count_df = pd.DataFrame(count6) #Series转为DataFrame count6=count_df count6[1]=1 # 添加1列全为1 count6

count6.rename(columns={'count':'click_count'}, inplace=True)
count6

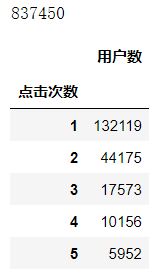
realIP_sum=count6['click_count'].sum() print(realIP_sum) count6= count6.groupby('click_count').sum()##统计各个“不同点击次数”分别出现的次数# 也可以使用counts1_['realIP'].value_counts()功能 count6.head() count6.columns=[u'用户数'] count6.index.name = u'点击次数' count6.head()
count6[u'用户百分比'] = count6[u'用户数']/count6[u'用户数'].sum()*100 count6[u'点击记录百分比'] = count6[u'用户数']*count6.index/realIP_sum*100 count6.sort_index(inplace = True) click_count=count6.iloc[:7,] click_count=click_count.T click_count

click_count.insert(0,u'总计',[count6[u'用户数'].sum(),100,100]) click_count[u'7次以上'] = click_count.iloc[:,0]- click_count.iloc[:,1:].sum(1) click_count.to_excel('D:/CourseAssignment/AI/CollectWebDate/tmp/2_2_2clickTimes.xlsx') click_count

统计结果分析,浏览一次的用户最多,占所有用户的58%左右。进一步分析浏览次数为一次的用户
# 获取浏览一次的所有数据 first_click = count_df[count_df['click_count']==1] # [i['realIP'].value_counts() for i in sql] del first_click[1] first_click.columns = [u'点击次数'] first_click
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/test?charset=utf8') sql = pd.read_sql('all_gzdata', engine, chunksize = 10000) # g = [pd.merge(f,i[['fullURLId','fullURL','realIP']],right_on = 'realIP',left_index=True,how ='left') for i in sql] get_first_click = [i[['fullURLId','fullURL','realIP']] for i in sql] get_first_click = pd.concat(get_first_click) display_first_click = pd.merge(first_click,get_first_click,right_on = 'realIP',left_index=True,how ='left') display_first_click.head()
# 浏览一次的用户的网页类型ID分析 analyze_id = display_first_click['fullURLId'].value_counts() analyze_id = pd.DataFrame(analyze_id) analyze_id
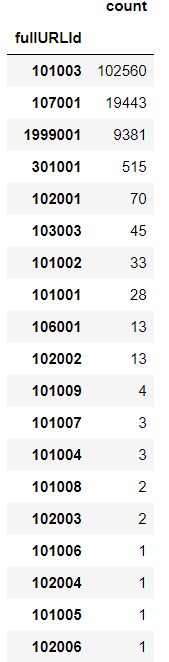
# 浏览一次的用户的网页类型ID分析 analyze_id.rename(columns={'fullURLId':u'个数'},inplace=True) analyze_id.index.name = u'网页类型ID' analyze_id[u'百分比'] = analyze_id['count']/analyze_id['count'].sum()*100 print(analyze_id)
count 百分比 网页类型ID 101003 102560 77.626988 107001 19443 14.716279 1999001 9381 7.100417 301001 515 0.389800 102001 70 0.052983 103003 45 0.034060 101002 33 0.024977 101001 28 0.021193 106001 13 0.009840 102002 13 0.009840 101009 4 0.003028 101007 3 0.002271 101004 3 0.002271 101008 2 0.001514 102003 2 0.001514 101006 1 0.000757 102004 1 0.000757 101005 1 0.000757 102006 1 0.000757
result_analyze_id=analyze_id[analyze_id['count']>100] result_analyze_id.loc[u'其他','count'] = analyze_id[analyze_id['count']<=100]['count'].sum() result_analyze_id.loc[u'其他',u'百分比'] = analyze_id[analyze_id['count']<100][u'百分比'].sum() result_analyze_id # 浏览一次的用户中浏览的网页类型ID
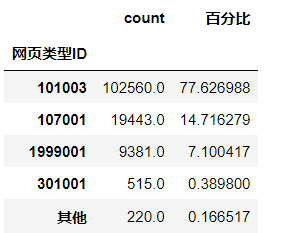
由结果可得,问题咨询页占比为64.9%,知识页占比为12.3%,这些记录均是通过搜索引擎进入的。由此可得两种可能性:
1、用户为流失用户,在问题咨询与知识页面上没有找到相关的需要。
2、用户找到其需要的信息,因此直接退出。
综合这些情况,将点击一次的用户行为定义为网页的跳出率。为了降低网页的跳出率,就需要对这些网页进行针对用户的个性化推荐,以帮助用户发现其感兴趣的网页或者需要的网页。统计浏览次数为一次的用户浏览的网页的总浏览次数。
# 点击1次用户浏览网页统计(点击数大于100次的) satistics_user_onetime = pd.DataFrame(display_first_click['fullURL'].value_counts()) satistics_user_onetime.index.name = u'网址' satistics_user_onetime.columns = [u'点击数'] satistics_user_onetime

pre_web_user_onetime = satistics_user_onetime[satistics_user_onetime[u'点击数'] > 100] pre_web_user_onetime.loc[u'其他',u'点击数'] = satistics_user_onetime[satistics_user_onetime[u'点击数']<=100][u'点击数'].sum() pre_web_user_onetime[u'百分比'] = pre_web_user_onetime[u'点击数']/satistics_user_onetime[u'点击数'].sum() pre_web_user_onetime
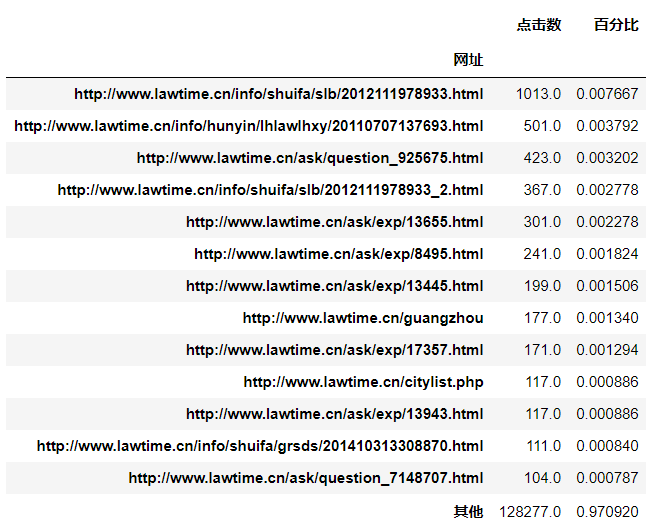
在本次数据探索中发现知识类网页的浏览次数在全部类型的网页中占比最高。当对原始数据进行探索分析时,发现存在与分析目标无关的数据和不符合建模输入要求的数据,即构建模型需要预处理的数据,需要对此类数据进行数据清洗、去重等操作,以此让数据满足构建推荐系统模型的输入要求
数据中存在大量仅浏览一次就跳出的用户,浏览次数在两次及以上的用户的浏览记录更适合推荐,而浏览次数仅一次的用户的浏览记录会进入推荐模型会影响推荐模型的效果,因此需要筛去浏览次数不满两次的用户
将数据集按8:2的比例划分为训练集和测试集
推荐系统是解决信息过载的有效手段,也是电子商务服务提供商提供个性化服务的重要信息工具
基于物品的协同过滤系统的一般处理过程,分析用户与物品的数据集,通过用户对物品的浏览与否(喜好)找到相似的物品,然后根据用户的历史喜好,推荐相似的物品给目标用户。在建立推荐系统时,模型的数据量越大越能消除数据中的随机性,得到的推荐结果越好。其弊端在于数据量越大模型建立以及模型计算耗时越久
基于物品的协同过滤算法的优缺点
1、优点:可以离线完成相似步骤,降低了在线计算量,提高了推荐效率;并利用用户的历史行为给用户做推荐解释,结果容易让客户信服。
2、缺点:现在的协同算法没有充分利用到用户间的差别,使计算得到的相似度不够准确,导致影响了推荐精度;此外,用户的兴趣是随着时间不断变化的,算法可能对用户新点击兴趣的敏感性较低,缺少一定的实时推荐,从而影响推荐质量。同时,基于物品的协同过滤适用于物品数明显小于用户数的情形,如果物品数很多,会导致计算物品相似度矩阵代价巨大。
将数据集中的数据转换成0-1二元型数据,使用ItemCF算法对数据进行模型,并给出预测推荐结果
import os import re import pandas as pd import pymysql as pm from random import sample from sqlalchemy import create_engine # 修改工作路径到指定文件夹 os.chdir("D:/CourseAssignment/AI/CollectWebDate/") # 读取数据 con = pm.connect(host='localhost',user='root',password='123456',database='test',charset='utf8',port=3306) data = pd.read_sql('select * from all_gzdata',con=con) con.close() # 关闭连接 #engine = create_engine('mysql+pymysql://root:123456@localhost:3306/test?charset=utf8') #data = pd.read_sql('all_gzdata', engine, chunksize = 10000) #data = pd.read_csv('./data/all_gzdata.csv') #print(data.loc[:,'fullURLId']) # 取出107类型数据 index107 = [re.search('107',str(i))!=None for i in data.loc[:,'fullURLId']] data_107 = data.loc[index107,:] # 在107类型中筛选出婚姻类数据 index = [re.search('hunyin',str(i))!=None for i in data_107.loc[:,'fullURL']] data_hunyin = data_107.loc[index,:] # 提取所需字段(realIP、fullURL) info = data_hunyin.loc[:,['realIP','fullURL']] # 去除网址中“?”及其后面内容 da = [re.sub('\?.*','',str(i)) for i in info.loc[:,'fullURL']] info.loc[:,'fullURL'] = da # 将info中‘fullURL’那列换成da # 去除无html网址 index = [re.search('\.html',str(i))!=None for i in info.loc[:,'fullURL']] index.count(True) # True 或者 1 , False 或者 0 info1 = info.loc[index,:]
# 找出翻页和非翻页网址 index = [re.search('/\d+_\d+\.html',i)!=None for i in info1.loc[:,'fullURL']] index1 = [i==False for i in index] info1_1 = info1.loc[index,:] # 带翻页网址 info1_2 = info1.loc[index1,:] # 无翻页网址 # 将翻页网址还原 da = [re.sub('_\d+\.html','.html',str(i)) for i in info1_1.loc[:,'fullURL']] info1_1.loc[:,'fullURL'] = da # 翻页与非翻页网址合并 frames = [info1_1,info1_2] info2 = pd.concat(frames) # 或者 info2 = pd.concat([info1_1,info1_2],axis = 0) # 默认为0,即行合并 # 去重(realIP和fullURL两列相同) info3 = info2.drop_duplicates() # 将IP转换成字符型数据 info3.iloc[:,0] = [str(index) for index in info3.iloc[:,0]] info3.iloc[:,1] = [str(index) for index in info3.iloc[:,1]] len(info3)
# 筛选满足一定浏览次数的IP IP_count = info3['realIP'].value_counts() # 找出IP集合 IP = list(IP_count.index) count = list(IP_count.values) # 统计每个IP的浏览次数,并存放进IP_count数据框中,第一列为IP,第二列为浏览次数 IP_count = pd.DataFrame({'IP':IP,'count':count}) # 3.3筛选出浏览网址在n次以上的IP集合 n = 2 index = IP_count.loc[:,'count']>n IP_index = IP_count.loc[index,'IP']
# 划分IP集合为训练集和测试集 index_tr = sample(range(0,len(IP_index)),int(len(IP_index)*0.8)) # 或者np.random.sample index_te = [i for i in range(0,len(IP_index)) if i not in index_tr] IP_tr = IP_index[index_tr] IP_te = IP_index[index_te] # 将对应数据集划分为训练集和测试集 index_tr = [i in list(IP_tr) for i in info3.loc[:,'realIP']] index_te = [i in list(IP_te) for i in info3.loc[:,'realIP']] data_tr = info3.loc[index_tr,:] data_te = info3.loc[index_te,:] print(len(data_tr)) IP_tr = data_tr.iloc[:,0] # 训练集IP url_tr = data_tr.iloc[:,1] # 训练集网址 IP_tr = list(set(IP_tr)) # 去重处理 url_tr = list(set(url_tr)) # 去重处理 len(url_tr)

import pandas as pd # 利用训练集数据构建模型 UI_matrix_tr = pd.DataFrame(0,index=IP_tr,columns=url_tr) # 求用户-物品矩阵 for i in data_tr.index: UI_matrix_tr.loc[data_tr.loc[i,'realIP'],data_tr.loc[i,'fullURL']] = 1 sum(UI_matrix_tr.sum(axis=1)) # 求物品相似度矩阵(因计算量较大,需要耗费的时间较久) Item_matrix_tr = pd.DataFrame(0,index=url_tr,columns=url_tr) for i in Item_matrix_tr.index: for j in Item_matrix_tr.index: a = sum(UI_matrix_tr.loc[:,[i,j]].sum(axis=1)==2) b = sum(UI_matrix_tr.loc[:,[i,j]].sum(axis=1)!=0) Item_matrix_tr.loc[i,j] = a/b # 将物品相似度矩阵对角线处理为零 for i in Item_matrix_tr.index: Item_matrix_tr.loc[i,i]=0 # 利用测试集数据对模型评价 IP_te = data_te.iloc[:,0] url_te = data_te.iloc[:,1] IP_te = list(set(IP_te)) url_te = list(set(url_te)) # 测试集数据用户物品矩阵 UI_matrix_te = pd.DataFrame(0,index=IP_te,columns=url_te) for i in data_te.index: UI_matrix_te.loc[data_te.loc[i,'realIP'],data_te.loc[i,'fullURL']] = 1 # 对测试集IP进行推荐 Res = pd.DataFrame('NaN',index=data_te.index, columns=['IP','已浏览网址','推荐网址','T/F']) Res.loc[:,'IP']=list(data_te.iloc[:,0]) Res.loc[:,'已浏览网址']=list(data_te.iloc[:,1]) # 开始推荐 for i in Res.index: if Res.loc[i,'已浏览网址'] in list(Item_matrix_tr.index): Res.loc[i,'推荐网址'] = Item_matrix_tr.loc[Res.loc[i,'已浏览网址'], :].argmax() if Res.loc[i,'推荐网址'] in url_te: Res.loc[i,'T/F']=UI_matrix_te.loc[Res.loc[i,'IP'], Res.loc[i,'推荐网址']]==1 else: Res.loc[i,'T/F'] = False # 保存推荐结果 Res.to_csv('./tmp/Res.csv',index=False,encoding='utf8')