题外话,我找个什么时间把kmp也加一下图解
z函数|exkmp
别担心
这个exkmp和kmp没毛点关系,请放心食用。
本文下标以1开始,为什么?因为1开始就不需要进行长度和下标的转换,长度即下标。
定义
给出模板串S和子串T,长度分别为n和m,对于每个ans[i](1<=i<=n),求出S[i...n]与T的最长公共前缀长度。
……我一脸懵逼
举个例子:

S=aabbabaaab
T=aabb
当i=0时,S[1...n]为aabbabaaab
与aabb的公共前缀是aabb,长度为4,即ans[1]=4
当i=1时,S[2...n]为abbabaaab
与aabb的公共前缀是a,长度为1,即ans[2]=1
当i=2时,S[3...n]为bbabaaab
与aabb的公共前缀是,长度为0,即ans[3]=0
.
.
.
当i=n-1时,S[n...n]为b
与aabb的公共前缀是,长度为0,即ans[4]=0
最终ans为4 1 0 0 1 0 2 3 1 0
大家可以自己计算并进行检验,这是第一步,搞懂这个算法求啥
exkmp与z函数区别
没区别
国外一般将计算该数组的算法称为 Z Algorithm,而国内则称其为 扩展 KMP。
暴力为王
暴力的算法复杂度为 O(n^2) ,非常巨大,所以我们要考虑优化,使用“转移”。
从入门到入土
我们为了简单,先简化一下条件:S=T,假如S与T完全相同,应该怎么做呢?
我们可以先发现ans[1]=n。这非常容易得到:
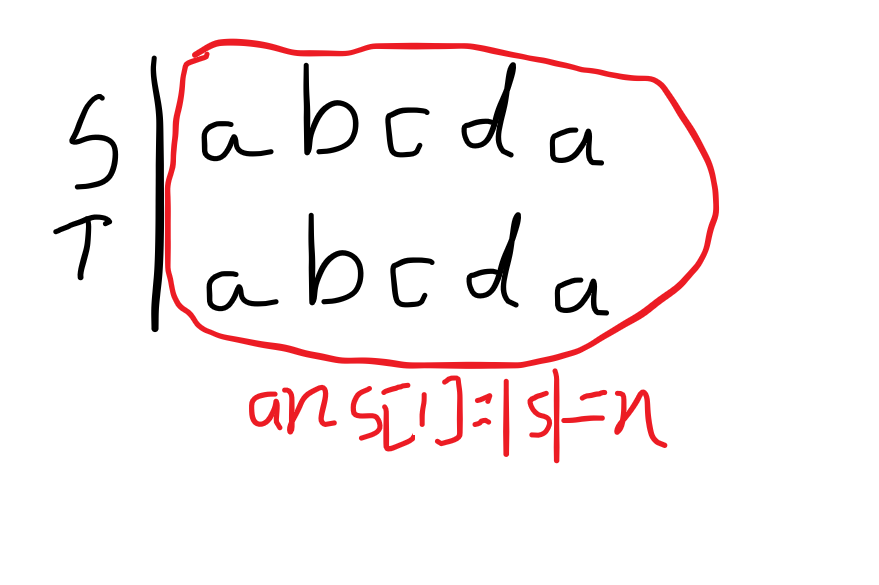
因为S=T,当求ans[1]时,S[1...n]是和S完全相等的,所以相等的长度就是n了,即ans[1]=n。
我们可以快速写出代码:
ans[1]=n
ans[2]?
ans[2]需要我们的暴力求解,为什么,因为如果我们不暴力求解,我们就无法通过某些奇怪的操作转移出后面的ans。
所以只能牺牲一下暴力ans[2]了。
代码很简单:
int now=0;
while(now+2<=n && S[now+1]==S[now+2]) now++;
ans[2]=now;
开始转移!!
我们设目前要求的是k。为了通过转移求出ans[k],我们要知道目前已求解部分中覆盖最远的地方,我们希望这个最远的已求解部分可以覆盖我们的ans[k]部分,这样我们就可以转移出来了。

如图,k是我们要求的,p0是已覆盖最远位置的起点,p1是已覆盖最远位置的终点,即p1=p0+ans[p0]-1。就是说,我们要求的ans[k]就在ans[p0]中。
我们给S平移p0位,即:
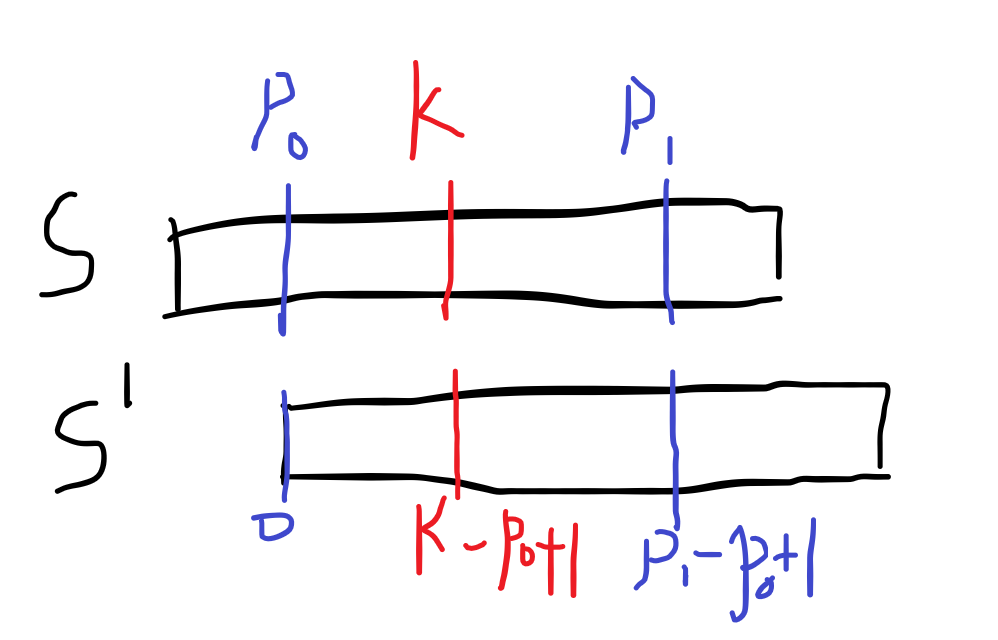
那么因为S[0...(p1-p0+1)]=S[p0...p1](这是定义),即下图中绿色部分相等:
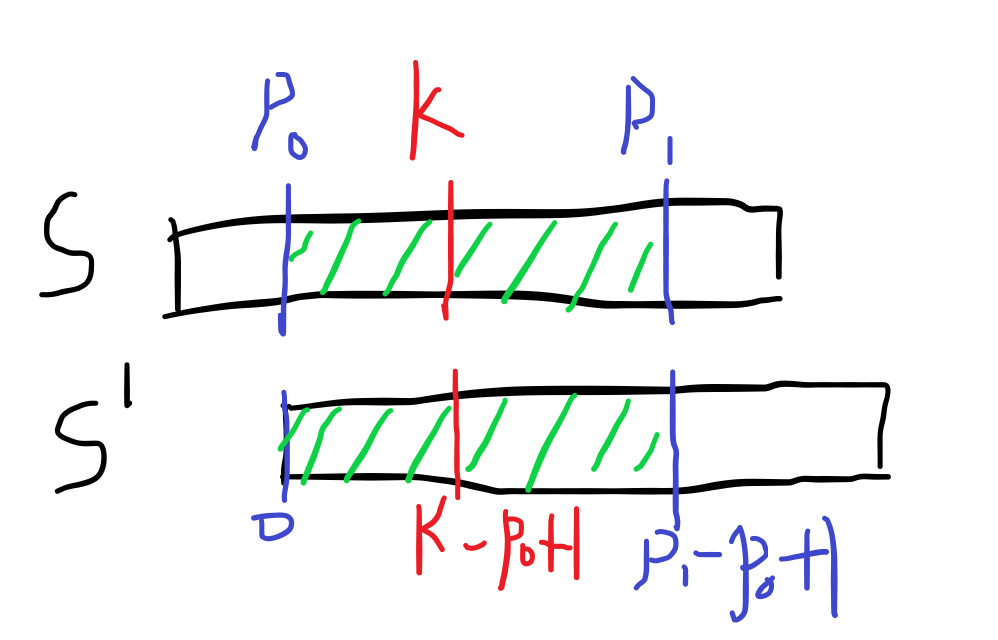
所以,下图中的蓝色部分相等,紫色部分也相等,对应的部分都相等ヾ(≧▽≦*)o:
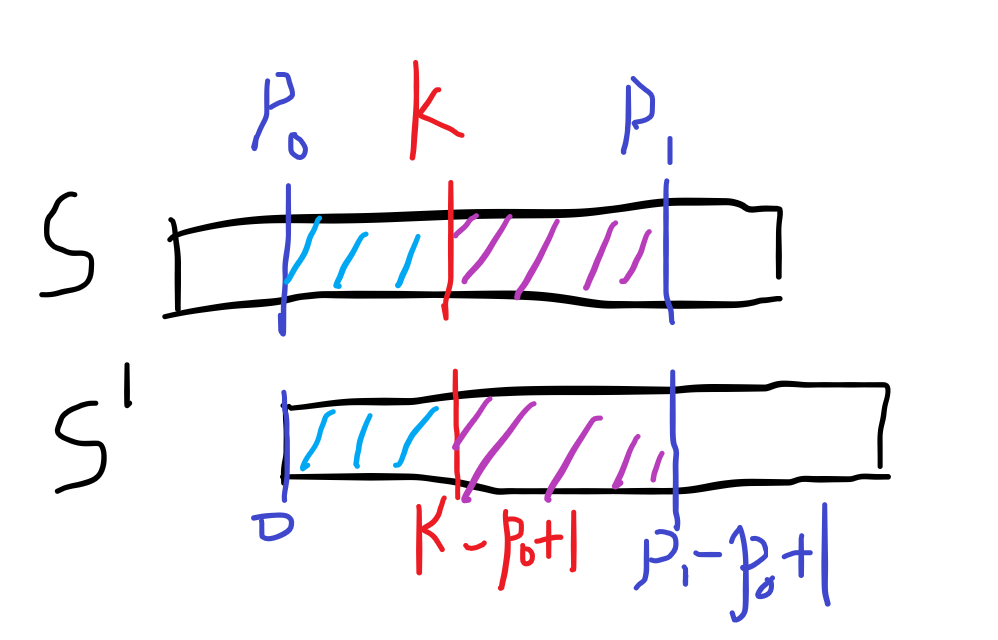
欸,那么也就是设有长度\(l\), \(S[(k-p_0+1)\dots (k-p_0+1)+l]\) 也会等于 \(S[k...k+l]\) ?即下图褐色部分相同:
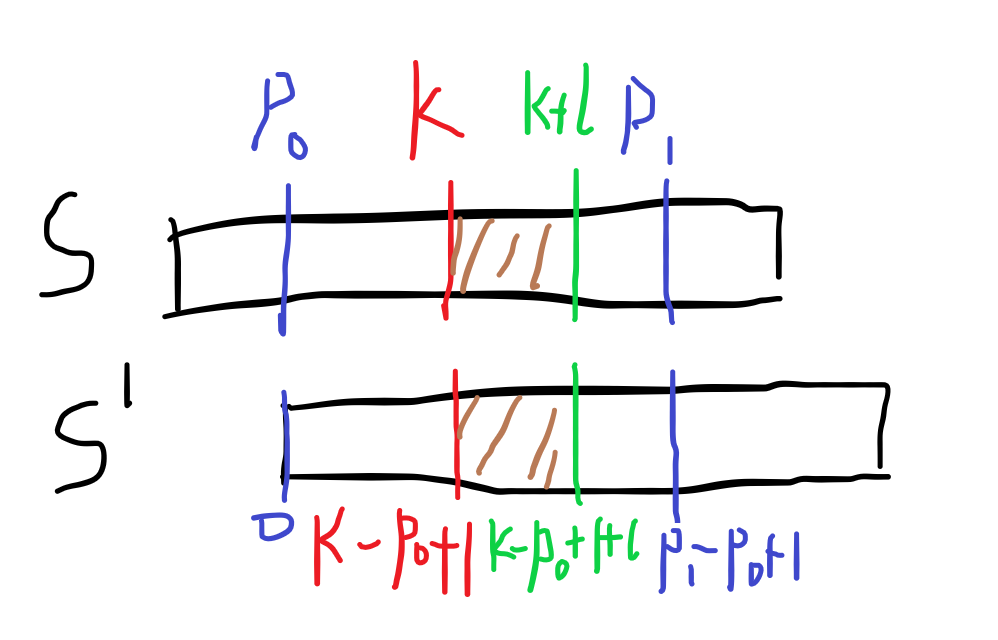
假如l就是ans[k-p0+1],这个区间不就是它们的最长公共前缀吗?
又因为定义,得知下图褐色①与褐色②相等,上面得出褐色②和褐色③相等,进而得出褐色①和褐色③相等(等量代换)。
又因为褐色④和褐色①相等(都是同一个位置的还能不相等?!),所以褐色③和褐色④相等:

那么不就得出来了吗?褐色③的ans就是褐色②的ans,即 \(ans[k]=ans[k-p_0+1]\)
所以我们就计算出来了吗?并没有。
意料之外
当我们的l在p1之外,那么就会出现:
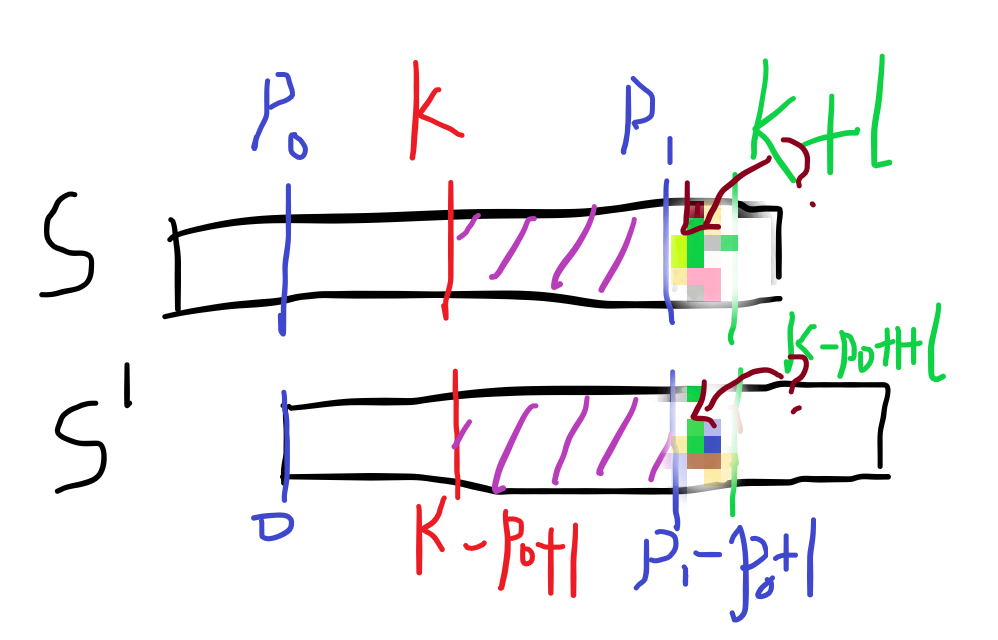
尽管紫色部分是相等的,可我们却不知道马赛克部分是否相等,如果相等就比转移后结果大,如果不相等就是转移后结果,所以我们无从可知,只能暴力ヽ(*。>Д<)o゜
可是如果如此暴力,复杂度又会退化为O(n^n),所以我们可以考虑优化:
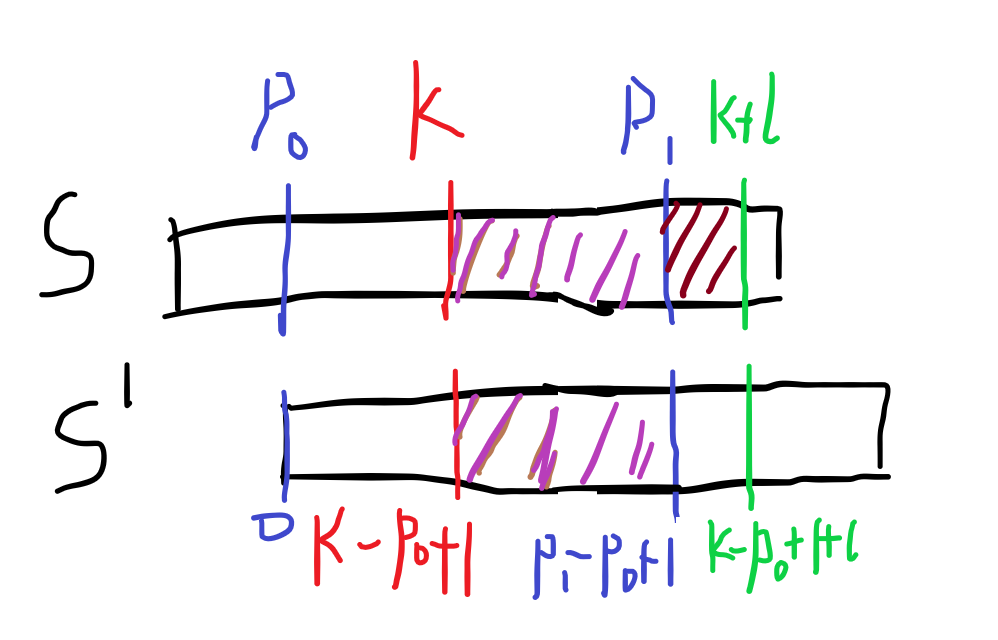
上图中我们已经得知紫色部分相等,只需暴力 深红色 部分即可。所以我们比对从 \(p_1-k\) 开始。
now=max(0,p1-k); // 因为紫色部分相等,我们选择不遍历这部分,可以省下一些时间,但如果紫色部分不存在,就会出现负下标,在此判断防止负下标的出现
while(now+k<=n && S[now+1]==S[now+k]) now++;
ans[k]=now;
p0=k;
p1=k+ans[k]-1;
Code
#include<cstdio>
#include<cstring>
#include<iostream>
using namespace std;
char S[1010];
int ans[1010];
int n;
int p0,p1;
int main() {
scanf("%s",S+1);
n=strlen(S+1);
ans[1]=n;
int now=0;
while(now+2<=n && S[now+1]==S[now+2]) now++;
ans[2]=now;
p0=2;
p1=2+ans[2]-1;
for(int k=3; k<=n; k++) {
if(k+ans[k-p0+1]-1<p1) ans[k]=ans[k-p0+1];
else {
now=max(0,p1-k);
while(now+k<=n && S[now+1]==S[now+k]) now++;
ans[k]=now;
p0=k;
p1=k+ans[k]-1;
}
}
for(int i=1; i<=n; i++) {
printf("%d ",ans[i]);
}
}
为什么是 k+ans[k-p0+1]-1<p1 而不是 k+ans[k-p0+1]-1<=p1
当ans[k-p0+1]=0 时,p0和p1在同一点上,就有:
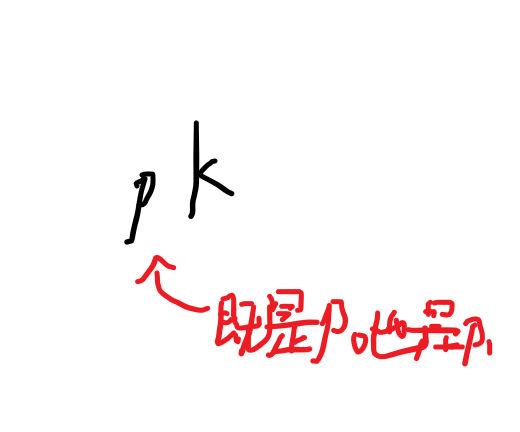
那么如果我们单纯判读 k+ans[k-p0+1]-1<=p1 ,p1就无法覆盖k,从而得出错误结果。
但如果我们舍弃一点复杂度,用 k+ans[k-p0+1]-1<p1 ,就不会出现无法覆盖的情况。
回归原题目, \(S\neq T\)
其实也差不多解决了。我们还是用之前的ans,因为这是拓展kmp,所以说我们再建一个exans ,表示S[i..n]与T的最长公共前缀的长度。
exans的第一位还是要暴力,理由同上:
int now=0;
while(now+1<=m && S[now+1]==T[now+1]) now++;
exans[1]=now;
还记得这张图吗:
模仿求ans的过程,只不过p0p1表示exans已求解部分中覆盖最远的地方,即:
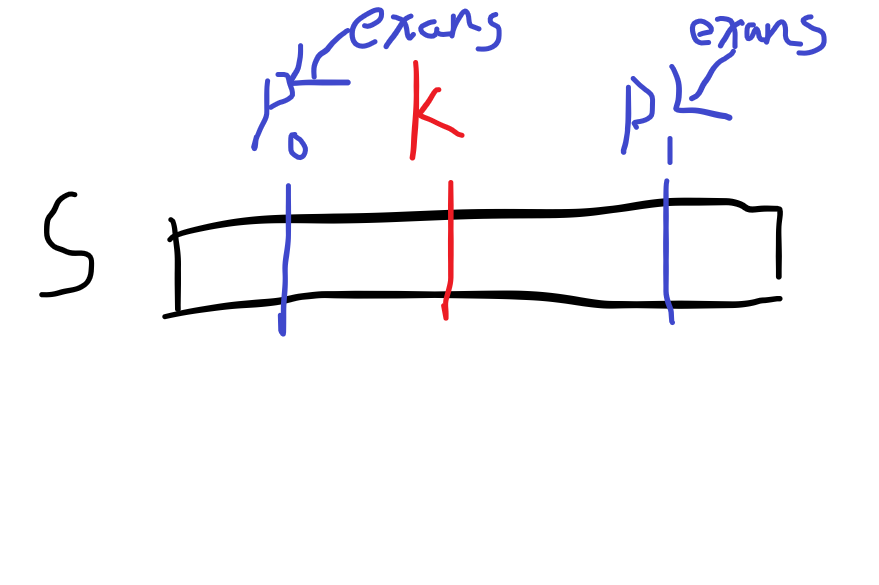
在平移p0位时,我们对应的是T:

此外均相同,故可以直接复制求ans的代码了:
#include<cstdio>
#include<cstring>
#include<iostream>
using namespace std;
char S[1010],T[1010];
int ans[1010],exans[1010];
int n,m;
int p0,p1;
void qAns() {
ans[1]=m;
int now=0;
while(now+2<=m && T[now+1]==T[now+2]) now++;
ans[2]=now;
p0=2;
p1=2+ans[2]-1;
for(int k=3; k<=m; k++) {
if(k+ans[k-p0+1]-1<p1) ans[k]=ans[k-p0+1];
else {
now=max(0,p1-k);
while(now+k<=m && T[now+1]==T[now+k]) now++;
ans[k]=now;
p0=k;
p1=k+ans[k]-1;
}
}
}
void qExans() {
int now=0;
while(now+1<=m && S[now+1]==T[now+1]) now++;
exans[1]=now;
p0=1;
p1=p0+exans[p0]-1;
for(int k=2; k<=n; k++) {
if(k+ans[k-p0+1]-1<p1) exans[k]=ans[k-p0+1];
else {
now=max(0,p1-k);
while(now+k<=n && T[now+1]==S[now+k]) now++;
exans[k]=now;
p0=k;
p1=k+exans[k]-1;
}
}
}
int main() {
scanf("%s %s",S+1,T+1);
n=strlen(S+1);
m=strlen(T+1);
qAns();
qExans();
for(int i=1; i<=n; i++) {
printf("%d ",exans[i]);
}
}