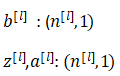什么是浅层神经网络
- logistic回归是将若干个特征先进行线性表达,再加上sigmod非线性化,得到结果
![]()
- 浅层神经网络计算又多加了一层隐藏层,得到输出值后重复了一遍计算流程,[1] 上标表示第几层
神经网络的向量化表示
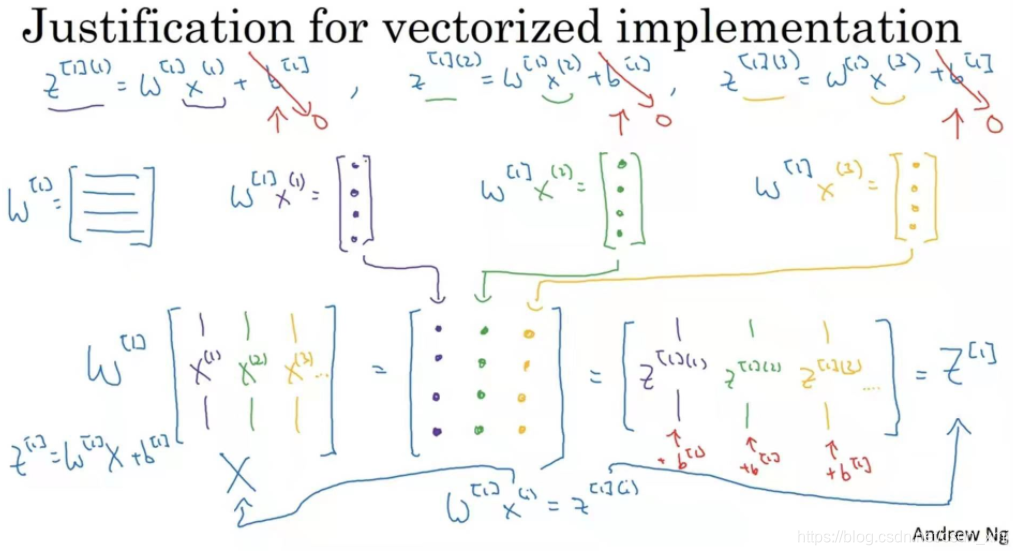
样本为列向量堆叠 : n_x * m
w维度 :n(l) * n (l-1) ,在logistic回归上,则为 1 * nl-1。(此处的w不需要转置)
b维度 :n_l * 1 广播机制传递到每一个样本对应的值上,横向传播,纵向和一层中每一个神经元一对一相加
z和a维度 :n(l) * m
激活函数的选择
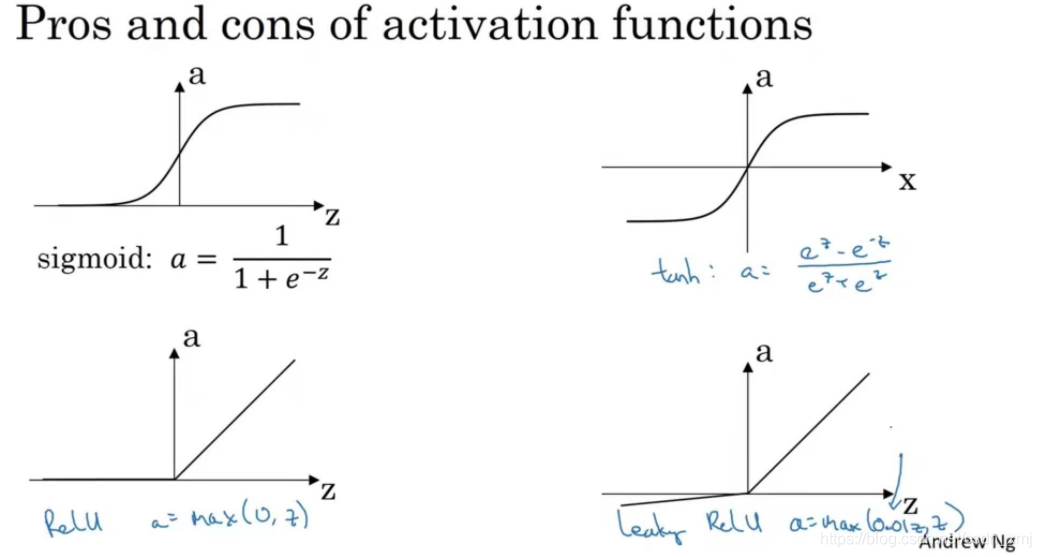
- sigmod函数
可以把输出限定值到(0,1),sigmoid函数除非用在二元分类的输出层,不然绝对不要用,或者几乎从来不用,因为当x过大或者过小时,其梯度非常小
- tanh函数
可以把函数限定到(-1,1),几乎在所有场合都比sigmod更优越,并且有类似数据中心化的效果,使数据平均值接近0,这实际让下一层的学习更方便一点。但是sigma函数和tanh函数都有一个缺点,如果z非常大或非常小时,那么导数的梯度(函数的斜率)可能就很小,接近0,这样会拖慢梯度下降算法。
- Relu函数
只要z为正,导数就是1;当z为负时,斜率为0。在选择激活函数时有一些经验法则,如果你的输出是0和1(二元分类),那么sigma函数很适合作为输出层的激活函数,然后其他所有单元都用ReLU函数,这是今天大多数人都在用的。ReLU的缺点是当z为负时,导数为0,但还有一个版本,带泄露的ReLU。
- Leaky ReLU函数(泄漏的ReLU)
Why do you need non-linear activation functions?
如果没有激活函数,那么神经网络只是把输入线性组合再输出(假设激活函数为g(z)=z,经过推导我们发现a^[2]仍是输入变量x的线性组合)。事实证明,如果你使用线性激活函数或者没有激活函数,那么无论你的激活函数有多少层,一直在做的只是计算线性激活函数,效果与一层的神经网络并没有什么区别。
Random Initialization
如果直接将参数全部初始化为0,那么各个特征计算出来的值均相同,反向传播时的值也均相同,这种情况下多个隐藏单元失去意义。
避免方法:随机初始化
W_1 = np.random.randn((2,2))*0.01 #随机初始化
b_1 = np.zero((2,1))
W_2 = np.random.randn((1,2))*0.01
b_2 = 0
深层神经网络
本质
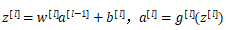
w^l链接了前一层和当前层,nl * n(l-1)