用一个简单的特征预测结果
这是一种根据自变量(X)的值来预测因变量(Y)的方法。假设两个变量时线性相关的。因此,我们试图找到一个线性函数,使得它能够尽可能准确地根据特征或自变量(x)来预测响应值(y)。
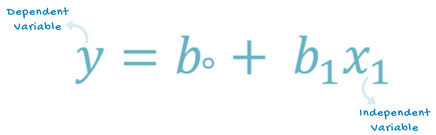
怎样找到最佳拟合曲线?
在这个线性回归模型中,我们试图通过寻找“最佳拟合线”——即回归线,来使预测误差最小化。我们尝试最小化观测值(真实值)与预测值(来自模型)之间的距离(长度)
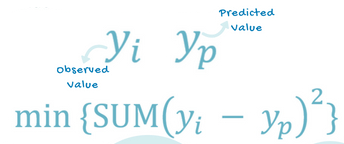
在这个回归任务中,我们将根据学生的学习小时数来预测他们预期得到的百分比成绩。

Step 1:预处理数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
dataset = pd.read_csv('studentscores.csv')
X = dataset.iloc[ : , : 1 ].values
Y = dataset.iloc[ : , 1 ].values
from sklearn.cross_validation import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split( X, Y, test_size = 1/4, random_state = 0)
注意,如果你使用的是sklearn的最新版本,你可能需要改成from sklearn.model_selection import train_test_split,因为cross_validation模块已经被弃用了
我们将按照前面数据预处理章节执行相同的步骤
- 引入python库
- 导入数据集
- 检查丢失数据
- 分割数据集
- 特征缩放将由我们用于简单线性回归模型的库来处理。
Step 2:通过训练集拟合线性回归模型
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
regressor = regressor.fit(X_train, Y_train)
为了拟合数据集到模型,我们将使用sklearn.linear_model库的LinearRegression类。然后新建一个LinearRegression类的对象regressor。现在使用LinearRegression类的fit()方法拟合regressor对象到数据集
Step 3:预测结果
Y_pred = regressor.predict(X_test)
现在我们将预测我们测试集的观测值。我们将保留输出到一个向量Y_pred中。为了预测结果,我们使用上一步训练好的regressor,使用LinearRegression类中的predict()方法
Step 4:可视化
最后一步是可视化我们的结果。我们将使用matplotlib.pyplot库来制作训练集和测试集结果的散点图,通过散点图来查看我们的模型预测值与观测值的接近程度。
可视化训练结果
plt.scatter(X_train , Y_train, color = 'red')
plt.plot(X_train , regressor.predict(X_train), color ='blue')
可视化测试结果
plt.scatter(X_test , Y_test, color = 'red')
plt.plot(X_test , regressor.predict(X_test), color ='blue')