模型算法(最难,模型结构与训练方法)
数据(最耗时,数据与模型效果之间的关系)
算力(GPU显卡+模型量化)
模型参数量、训练数据量:
模型参数量决定 整个模型的理论效果
训练数据量决定 整个模型的实际效果
多模态:用于表示某种信息的模式(图片、文字、语音、视频)
通过各种预训练模型将信息的不同模式,用相近的向量进行表示。

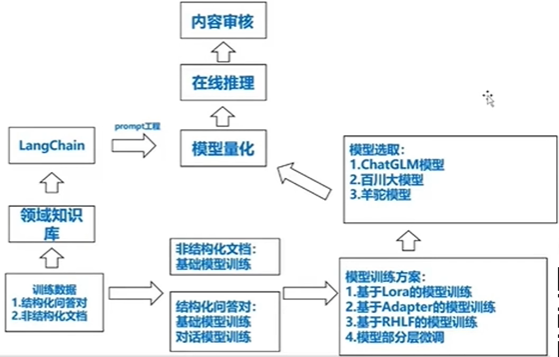
大模型的核心,问答系统(transform 结构)
prompt工程(模型适配)

nlp应用场景:
文本摘要
信息提取
问答
文本分类
对话
代码生成
推理
cv应用领域:
vit(vision transformer),做图像分类
yolo 目标检测------->(置信度,目标,位置)
时间序列问题
文本分类

文本预处理:
1.中文分词技术
2.英语可以用空格就可以切分单词
(1)基于词表的分词算法
正向最大匹配法,对于输入的一段文本从左至右、以贪心的方式切分出当前位置上长度最大的词。正向最大匹配法是基于词典的分词方法,其分词原理是:单词的颗粒度越大,所能表示的含义越确切。
- 正向最大匹配算法
- 逆向最大匹配算法
- 双向最大匹配算法
(2)基于统计模型的分词算法
基于统计模型的分词算法的主要核心是词是稳定的组合,在上下文中相邻的字如果同时出现的次数越多,那么就越有可能构成一个词。因此字与字相邻出现的概率或者频率能较好地反映成词的可信度。可以对训练文本中相邻出现的各个字的组合的频度进行计算统计,得出它们之间的互现信息。互现信息体现了汉字之间结合关系的紧密程度。当紧密程度高于某一个阈值时,便可以认为此字组可能构成了一个词。该方法又称为无字典分词。
- 基于N-gram语言模型的分词方法
- 基于HMM的分词方法
- 基于CRF的分词方法
常用分词工具(jieba分词)
jieba分词目前在中文分词中被引用的还是比较多的,jieba分词支持三种模式:
- 精确模式,试图将句子最精确地切开,适合文本分析;
- 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快, 但是不能解决歧义;
- 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回 率,适合用于搜索引擎分词;
自定义Jieba分词词典
开发者可以指定自己自定义的词典,以便包含 jieba 词库里没有的词。虽然 jieba 有新词识别能力,但是自行添加新词可以保证更高的正确率

文本分词后,接下来是文本向量化(Word Embedding,词嵌入),即用向量或矩阵的形式表示文本,也可以理解为对文本的数值化处理。文本向量化从数学角度可以解释为映射,即将单词映射到另一个空间,f : A -> B,生成一个在新空间上的表达。
词向量方法:
One-hot Representation
Word2Vec
Distributed Representation
常说的embedding特征其实包含两个意思(其实本质是一样的):
- 1、基于一些模型比如word2vec、graph embedding方法等产出item、user的embedding作为user维度、item维度的一部分特征传入模型使用。
- 2、深度模型产出的中间结果,比如双塔模型,我们最终算法的user 和 item的余弦相似度,但是会依赖中间产出的user、item embedding;又比如Youtube DNN中会依赖用户的行为序列特征,比如点击序列,但是点击序列是没有办法被网络直接使用的,所以就要借助embedding去实现。