A Detector-Oblivious Multi-Arm Network for Keypoint Matching
背景:由于关键点检测器是在不同的损失函数下训练的,并且采用不同的算法设计的,因此它们通常对同一关键点坐标给出不同的描述(和置信度)。因此,每次与不同的关键点检测器组合时,都需要重新训练SuperGlue,因为估计的匹配依赖于关键点属性。
创新点:使用辅助任务学习来提高主要任务的性能。
主要方法:
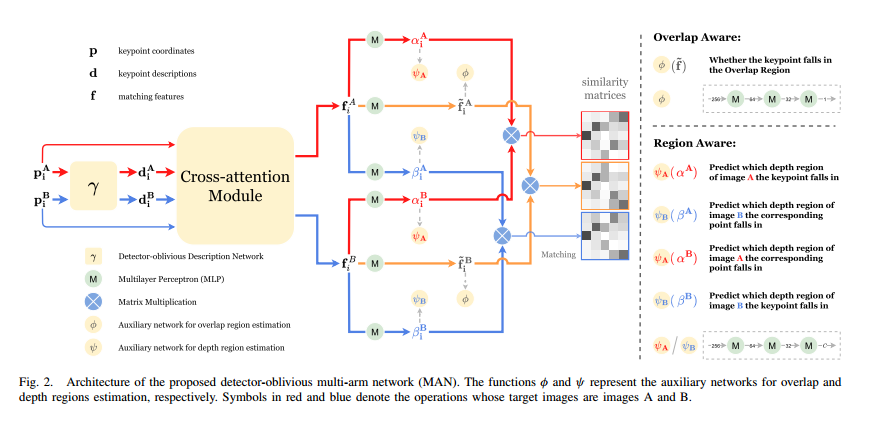
Detector-Oblivious Approach:经过实验发现SuperGlue输入的关键点置信度对性能的贡献很小,所以将其删除。提出了一个与检测器无关的函数,通过输入关键点位置,即可获得关键点描述符。(可以理解为训练一个网络,用于实现γ的网络可以是满足公式d = γ(I, p)的任何网络,I是输入的图像。如果网络可以为输入图像I提供密集的特征映射,则可以用于实现γ)
The Multi-Arm Network:使用网络不仅找到关键点的分数矩阵,还有其深度和重叠区域的对应关系。对应区域的概念取决于图像A和图像B,而不仅仅是单个图像。因此,从任何一幅图像中提取的描述符都不足以推断区域之间的关系。在进行区域估计时,需要关键点描述符d1和d1相互通信。借鉴了SuperGlue提出的交叉注意模块,在图像之间传递区域级信息。
重叠区域对应关系:
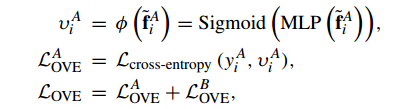
其中~ fiA是经过检测重叠区域网络转换过的关键点表示。υiA ∈(0,1),y iA∈{0,1}是二进制标签,使用上述损失函数来训练关键点是否在重叠区域。
深度区域对应关系:
使用Otsu的方法根据图像深度将图像分割为近景和远景区域。我们根据深度值将图像划分为C = 3个区域,其中有效区域占两个区域(蓝色和黄色),无效区域占一个区域(黑色)。
匹配过程:估计三个相似矩阵。对于推理,我们只保留在所有三个相似矩阵中幸存的匹配结果,从而增加了匹配的可靠性。

其中,D表示图像的深度图,D min和D max表示深度图的最小值和最大值,c表示区域类。
使用网络训练输出aiA,biA,aiB,biB.

上述为aiA,biA,aiB,biB代表的意义。
![]()
使用上述损失函数来训练关键点是否在同一深度区域。我们希望aiA,biA,aiB,biB的对应关系为:
![]()
深度区域对应关系的损失函数:
![]()
总体的损失函数:
![]()
其中,LMatch是SuperGlue提出的损失函数。
优化工作要朝着主要匹配任务,而不是辅助任务的方向发展。因此,只使用三层MLP来设计辅助网络。这种轻量级的辅助网络很难学习复杂的能力,例如准确估计关键点所在的重叠区域或深度区域。然而,我们认为首先在重叠区域找到关键点或者准确预测关键点的深度区域是很有趣的。如果网络可以排除重叠区域之外的关键点,我们就可以提前消除许多潜在的不匹配。如果网络可以精确估计关键点深度区域,我们就只能匹配相应区域的关键点,同时也可以防止非对应区域的关键点匹配。
缺点:计算量大。