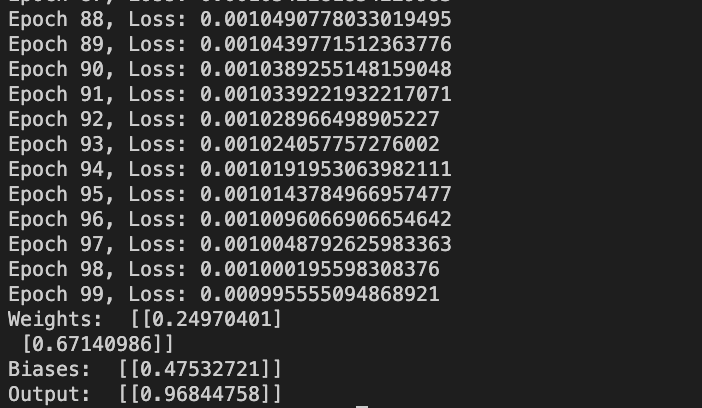
import numpy as np class NeuralNetwork: def __init__(self, input_size, output_size): self.input_size = input_size self.output_size = output_size self.weights = np.random.rand(input_size, output_size) self.biases = np.random.rand(1, output_size) def forward(self, inputs): self.z = np.dot(inputs, self.weights) + self.biases self.output = np.tanh(self.z) return self.output def tanh_derivative(self): return 1 - np.power(self.output, 2) def backward(self, inputs, labels, learning_rate): error = self.output - labels d_weights = np.dot(inputs.T, error * self.tanh_derivative()) d_biases = np.sum(error * (1 - np.power(self.output, 2)), axis=0, keepdims=True) self.weights -= learning_rate * d_weights self.biases -= learning_rate * d_biases def train(self, inputs, labels, learning_rate, epochs): for i in range(epochs): output = self.forward(inputs) self.backward(inputs, labels, learning_rate) loss = np.mean(np.square(labels - output)) print("Epoch {}, Loss: {}".format(i, loss)) def print(self): print("Weights: ", self.weights) print("Biases: ", self.biases) print("Output: ", self.output) # Example usage inputs = np.array([[1.0, 2.0]]) labels = np.array([[1.0]]) network = NeuralNetwork(input_size=2, output_size=1) network.train(inputs, labels, learning_rate=0.1, epochs=100) network.print()