1. Binary Classification

如上图所示是经典的二分类问题。输入的图片是3通道64*64像素的,有3个64*64的矩阵,把这些像素亮度放入一个特征向量(feature vector)x。(按照通道的顺序排列下来,如上图的X),向量x的总维度就是64*64*3,为12288。用n_x=12288来表示输入的特征向量x(列向量)的维度,为了简写用小写n代替。
在二分类问题中,目标是训练一个分类器,它以图片的特征向量x为输入,预测输出的结果标签y是0还是1。
一些符号:
用一对(x,y)表示一个单独的样本,其中x是n_x维的特征向量,y为0或者1。训练集大小为m。train为训练集,test为测试集。
定义一个矩阵X,矩阵有m列,n_x行,这里矩阵X的行n_x代表了每个样本x的特征个数,列m代表了样本个数。有时候矩阵X的定义是训练样本作为行向量堆叠,而不是这样列向量堆叠。在神经网络中,一般用列向量。X是一个n_x*m的矩阵。当你用python 实现时,X.shape=(n_x,m)
Y是一个1*m的矩阵,同样Y.shape=(1,m)。
2. Logistic Regression
什么是logistic regression?
接下来我们介绍如何使用逻辑回归来解决二分类问题。
逻辑回归输出的是概率,所以取值需要限定在(0,1)之间,所以需要进行转换。引入Sigmiod函数,让输出限定在[0,1]之间。
已知的特征输入向量x可能是n_x维度,logistic回归的参数w也是n_x维的向量,而b就是一个常数项,通过广播机制来相加。(这里均表示列向量)
logistic regression 的线性预测输出可以写成如下格式:
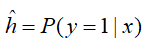
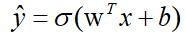
(在很多其他机器学习资料中,可能把常数b当做w0处理,并引入x0=1。这样从维度来看,x和w都会增加一维。但是在本课程中,为了简化计算和便于理解,Andrew建议使用上式的形式,将w和b分开比较好。)
- Sigmiod函数是一种非线性的S型函数,输出范围是[0,1],通常在神经网络中当激活函数(Activation function)。表达式和曲线如下:
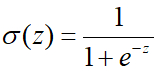
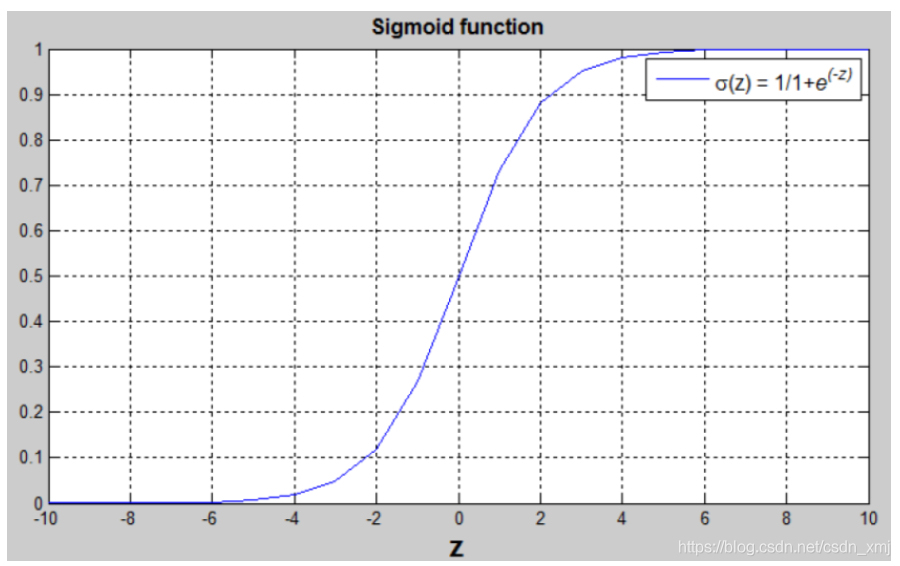
从曲线可以看出,当z很大时,函数值趋于1;当z很小时,函数值趋于0;且当z=0时,函数值为0.5。
并且当 z 值很大或者很小时,sigmod函数的梯度值非常小,导致梯度下降缓慢,这正是sigmod激活函数的致命缺点。
注意,Sigmoid函数的一阶导数可以用自身表示:
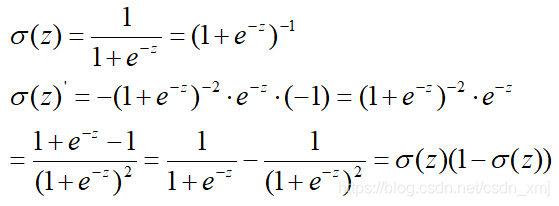
- 所以 logistic regression完整形式如下
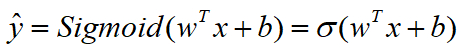
logistic regression的损失函数推导
在使用logistic regression时,w和b都是未知的参数,需要反复训练优化得的。为了拿到最优的logistic回归模型的参数w以及b,需要定义一个成本函数(cost function)。为了让模型通过学习调整参数,要给一个m个样本的训练集,很自然地,你想通过在训练集找到参数w和b,来得到你的输出。
对于m个训练样本,我们通常使用上标来表示对应的样本。例如(表示第i个样本):
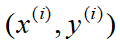
如何定义所有m个样本的cost function呢?先从单个样本出发,我们希望该样本的预测值与实际值越相似越好。
Loss(error) function:损失函数(误差函数),可以用来衡量算法的运行情况。你可以定义损失函数为y帽和y的差的平方,或者它们差的平方的1/2。
但通常在logistic回归中,大家都不这么做,因为当你学习这些参数的时候,你会发现之后讨论的优化问题,会变成非凸的,最后会得到很多个局部最优解,梯度下降法可能找不到全局最优解。
这个的直观理解就是我们通过定义这个损失函数L来衡量你的预测输出值y帽和y的实际值有多接近。
误差平方,似乎是个不错的选择,但用这个的话,梯度下降法就不太好用。因此我们选择的损失函数一般是凸的,另一个函数定义如下:在logistic回归中,我们会定义一个不同的损失函数它有和误差平方相似的作用,这些会给我们一个凸的优化问题。一般而言,我们偏向研究凸函数问题。
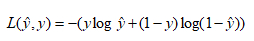
对于这个损失函数,我们也想让它尽可能的小。
例子:
(1)y=1时,L= - log(y^)想要足够小,y^就要足够大,最大最大不能超过1。
(2)y=0时,L=- log(1-y^)想要足够小,(1-y^)要足够大,y^就要足够小,最小不能小于0。
有很多函数都能达到这个效果:如果y=1,我们尽可能让y^很大;如果y=0,尽可能让y^很小。以上两个例子就解释了为什么用这个作为损失函数。(后面的选修视频会给出更正式的原因)
说明:loss function 损失函数是在单个训练样本中定义的,它衡量了在单个训练样本上的表现。
在实际训练过程中,我们需要衡量的是在全体训练样本上的表现,此时我们建立成本函数。成本函数J是根据之前得到的两个参数w和b,J(w,b)=损失函数求和/m.,即所有m个训练样本的损失函数和的平均。
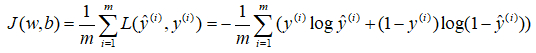
成本函数(cost function)是关于未知参数w和b的函数,我们的目标是在训练模型时,要找到合适的w和b,让成本函数J尽可能的小。
结果表明,logistic回归可以看成是一个非常小的神经网络。下一个视频,我们将直观地了解神经网络能做什么。
Gradient Descent
下面我们讨论如何使用梯度下降法来训练或学习 训练集 上的参数w和b。
我们希望找到使成本函数J(w,b)尽可能小的w和b
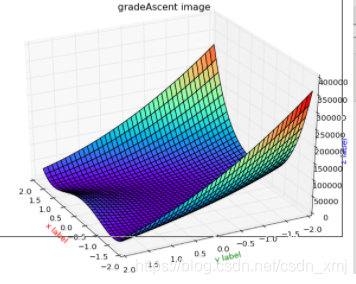
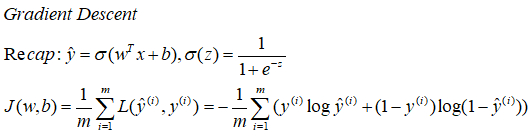
使用此成本函数的优势正是在于这个函数是一个凸函数。
凸函数(convex function)的局部优化特性是logistic回归使用这个成本函数J的重要原因之一。使用梯度下降法很快地收敛到局部最优解或者全局最优解。

通过上式不断的更新迭代w。(微积分中的导数)
由于J(w,b)是凸函数,梯度下降算法(Gradient Descent)是先随机选组一组参数w和b值,然后每次迭代的过程中分别沿着w和b的梯度(偏导数)的反方向前进一小步,不断修正w和b。每次迭代更新w和b后,都能让J(w,b)更接近全局最小值。
梯度下降算法每次迭代更新,w和b的修正表达式为:
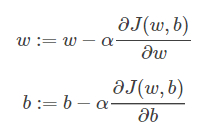
其中,alpha是学习因子(learning rate),表示梯度下降的步进长度,其值越大,w和b每次更新的“步伐”更大一些;越小,更新“步伐”更小一些。在程序代码中,我们通常使用dw来表示。
通常使用dw表示∂J(w,b)/∂w,用db表示∂J(w,b)/∂b。一般而言,在微积分中df/dx表示对单一变量求导数,∂f/∂x对多个变量中某个变量求偏导数。梯度下降算法能够保证每次迭代w和b都能向着J(w,b)全局最小化的方向进行。其数学原理主要是运用泰勒一阶展开来证明的。
向量化-Vectorization
深度学习在训练大量数据时表现才更加优越,所以你的代码运行的非常快至关重要,否则将等待非常长的时间去得到结果。所以在深度学习领域向量化是一个关键技巧。
在logistic回归中,使用numpy库进行向量操作,速度远快于使用循环
a = np.random.rand(1000000) b = np.random.rand(1000000) np.dot(a,b)
(可扩展深度学习实现是在GPU上做的,GPU(graphics processing unit)也叫图像处理单元。CPU和GPU都有并行化(parallelization)的指令,有时候也会叫SIMD(Single Instruction Multiple Data)指令,意思是单指令流多数据流,这个词的意思是如果你使用了这样的内置函数,np.function或者其他能让你去掉显式for循环的函数,这样python的numpy能够充分利用并行化去更快的计算,大大提高程序运行速度。这点对GPU和CPU上计算都是成立的。但相对而言,GPU更擅长SIMD计算,但CPU事实上也不是太差)
所以要记住,经验法则是当你编写新的网络时,或者你做的只是回归,那么一定要尽量避免for循环,能不用就不用。如果你可以使用内置函数,或者找出其他方法去计算循环,通常会比直接用for循环更快!
(1)已经矩阵A和向量v,想求乘积,我们通常使用u = np.dot(A,v)函数来进行矩阵乘积。(涉及python的numpy库)
(2)已经向量v,想做指数运算,作用到向量v的每一个元素。使用u = np.exp(v),v作为输入向量,u作为输出向量。这样代码会快很多。
实际上,numpy库有很多向量值函数,例如np.log()会逐个元素计算log;np.abs()会计算绝对值;np.maxinum计算所有元素中的最大值;v**就是v中每个元素的平方;1/v就是每个元素求倒数。所以当你想使用for循环时,应该看看可不可以调用numpy的内置函数。下面我们看看这些函数怎么应用到logistic回归梯度下降算法实现中来。
Vectorizing Logistic Regression
logistic回归的正向传播步骤,如果你有m个训练样本,那么对第一个样本预测你需要这样计算:
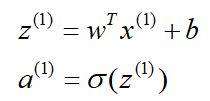
- 向量操作
定义一个矩阵X来作为你的训练输入,这是一个n_x * m的矩阵(每一个样本就是一列),维度是(n_x,m)。
先构建一个1*m(列为样本,行为预测值)的矩阵Z来作为你的训练输出,w^T是一个1*n_x的矩阵,维度是(1,n_x)。b是一个常数值,维度为(1,m)。
代码为
import numpy as np Z = np.dot(w.T,X) + b #w.T表示w的转置,b为1*1,Z为1*m矩阵 #python中自动扩展为一个1*m的行向量,这个操作在python中叫做广播(broadcasting) A = sigmoid(Z)
Trick
- import numpy as np a = np.random.randn(5) #生成5个随机高斯变量,储存在数组a中。
上述语句生成的a的维度是(5,),这是所谓的python中秩为1的数组,称为rank 1 array,它既不是行向量也不是列向量,这导致它有一些略微不直观的效果。在编写神经网络程序时,就不要用这种数据结构,可以使用a.reshape((5,1)) 转换结构
- 使用assert语句对向量或数组的维度进行判断:
assert(a.shape == (5,1)) #执行起来很快,也可以看成是代码的文档
assert会对内嵌语句进行判断,即判断a的维度是不是(5,1)的。如果不是,则程序在此处停止。使用assert语句也是一种很好的习惯,能够帮助我们及时检查、发现语句是否正确。
————————————————
版权声明:本文参考CSDN博主「双木的木」的原创文章,遵循CC 4.0 BY-SA版权协议,转载附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/csdn_xmj/article/details/114578241