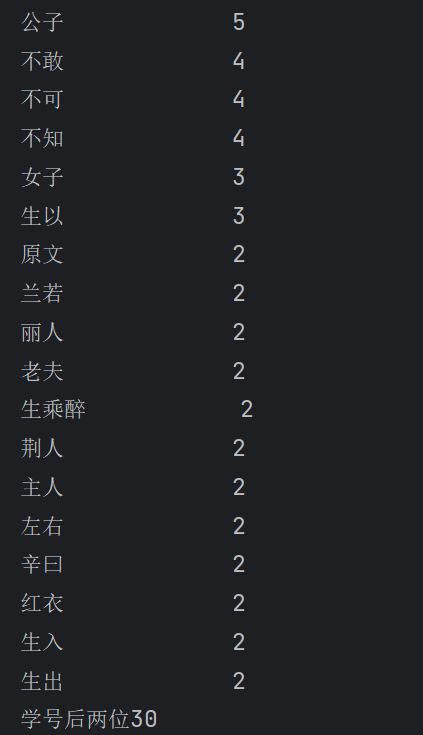
import jieba txt = open("D:\python-learn\lianxi\聊斋志异.txt","r",encoding = 'utf-8').read() words = jieba.lcut(txt) counts = {} for word in words: if len(word) == 1: continue else: counts[word] = counts.get(word,0)+1 items = list(counts.items()) items.sort(key = lambda x:x[1],reverse = True) for i in range(20): word,count = items[i] print("{0:<10}{1:>5}".format(word,count)) print("学号后两位30")