几何深度学习技术杂谈
计算机视觉的最新进展,主要来自于新颖的深度学习方法,以及基于大量数据来执行特定任务的分层机器学习模型,随之而来的性能提升,引发了其他科学领域类似应用的淘金热。
https://arxiv.org/pdf/1611.08097.pdf
随着深度学习技术的发展,人们已经不满足于将深度学习应用于传统的图像、声音、文本等数据上,而是对更一般的几何对象如网络、空间点云、曲面等应用深度学习算法,这一领域被称为几何深度学习(Geometric deep learning)。






下文中,我们将解释GDL中「几何」的含义,同时会将其与其他神经网络结构进行比较。最后,我们还会带大家深入了解它擅长的多种任务,以及最新前沿应用。
放心,即使没有太多的基础,读完这篇文章后,也能充分体会到GDL的魅力。

深度学习巨头LeCun牵头的几何深度学习在讲啥?
2016年,Bronstein的一篇名为《Geometric deep learning: going beyond Euclidean data》的文章来势汹汹,该文的后两位作者分别是Facebook前人工智能团队博士后成员Joan Bruna和现人工智能负责人Yann LeCun,这也算得上是全明星阵容,因此这篇文章的含金量和参考性就得以保证。
论文传送带:
https://arxiv.org/pdf/1611.08097.pdf
在这篇文章中,研究者首次引入了几何深度学习(GDL)一词。

文章表示,几何深度学习(GDL)定义了新兴的研究领域,该领域主要是针对非欧几里得数据的深度学习。
非欧几里得数据

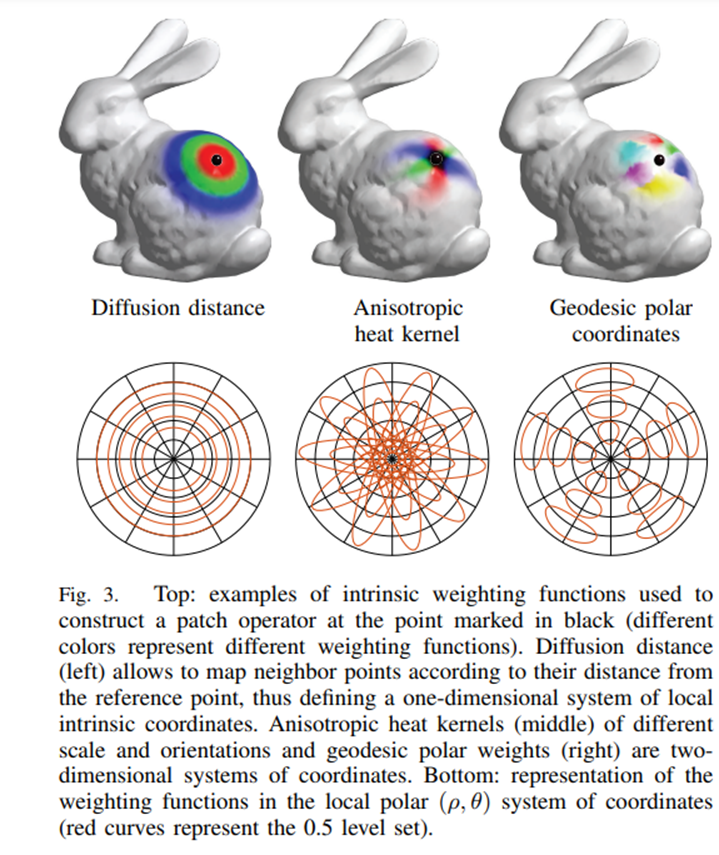
对于非欧几里得数据,两点之间的最短有效路径不是它们之间的欧几里得距离。我们将使用网格对此进行可视化。在下图中,可以看到,通过离散体素,将经典斯坦福兔子表示为网格(非欧几里得)或呈网格状体积(欧几里得)之间的区别。

点A和B之间的欧式距离是它们之间最短直线路径的长度,可视为图像上的蓝线。两点之间的测地距离,则更类似于绿线的长度。测地距离是高维最短路径概念的表示,而图的测地距离通常是节点之间的最短路径。
以非欧几里德的方式解释网格的优点是,测地距离对于在其上执行的任务更有意义。我们这样想:在深层的CNN中,我们依赖于可能彼此相关的相邻像素。为了在图上重现类似的设置,我们需要考虑重新制定「紧密度」。
当然,我们可以将固有的非欧几里德数据转换为欧几里得数据,但这样的效率和性能损失会很大。在针对零件分类和分割的斯坦福大学ShapeNet数据集上,这一代价显而易见。第一个在Chang等人提出的基准上达到良好结果的神经网络,依赖于对于网格的体积表示,以及处理过程中使用的深度信念网络。



因为问题的规模是立方的,因此这种方法的主要问题,是如何权衡离散化和运行效率。此外,在3D体素上使用卷积,会在3D空间上执行的计算中花费大量的开销。由于在同一体素空间中表示了许多不同的对象,所以没有简单的方法来防止这些空计算的发生。
当前的SOTA方法,则直接在网格结构上执行上述任务,或者将它们转换为点云,从而实现卓越的性能,显著缩短了运行时间。




既然这一部分是几何深度学习,那我不是很懂图论诶,这怎么破?
不用担心,在本文的其余部分中,您不需要图论知识,但您应该先阅读一下,才能使用我们很快将要看的软件库。为了了解GDL中的基本概念,如果您想要对图论中得到很好的入门级理解,可以参考Vaidehi Joshi的《图论的优雅介绍》(A Gentle Introduction To Graph Theory):
https://medium.com/basecs/a-gentle-introduction-to-graph-theory-77969829ead8
为了理解这一领域的详细算法,想更深一步理解该领域的深度理论,请参阅Wu等人的论文《关于图神经网络的全面研究》(A comprehensive survey on graph neural networks)。
此外,该研究报告中介绍的分类法,还可以帮助您理解此领域与深度学习其他领域的相似之处。
当然,最好的情况是,这篇文章可以让你根据可用的数据,来判断可能的应用场景,并解决现存的问题。

深度CNN的两个基本属性:局部性和空间转换的不变性。此外,通过在深层CNN中堆叠卷积层,我们鼓励网络学习不同抽象级别上的特征。这种层次结构,也是深层CNN的第三个主要属性。这意味着通过顺序组合图层,我们实现了功能层次结构,从而可以在数量上更好地表示有监督任务。总而言之,这三个方面使深层CNN可以很好地应用于到图像域。

当前在GDL中的研究,也试图达到类似的目标,但是这一过程,要建立在功能更强大的推理基础上。正如Francois Chollet在上面的推文中提到的那样,深层的CNN可以很好地概括所有视觉数据。在图形上使用GDL时,我们可以依赖于任意关系归纳偏差,来开发可以推广到任意关系数据的算法。
预测新冠发病率!几何深度学习要怎么玩?
图分割
图的分割是对图的每个组成部分,节点或边进行分类的任务。
从较大的COSEG语义分段数据集中,我们提取出了四足数据集,并显示了此任务的真实标签。在这种情况下,每一部分都有属于五种可能类别之一的标签:耳朵,头部,躯干,腿和尾巴。根据此局部级别的信息,生成节点或边缘标签就变得很简单。当前,这种直接在网格上工作的方法可以在基准上实现很好的SOTA性能。
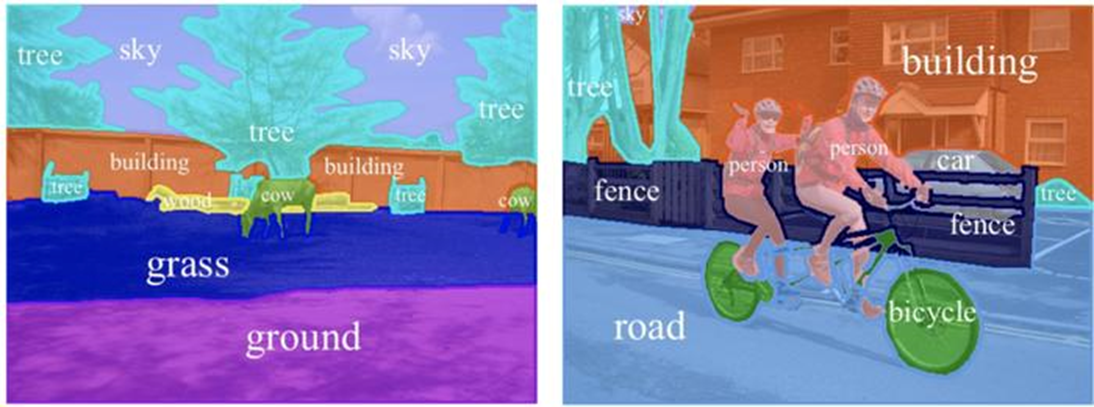
为什么在这种粒度级别上进行语义分割,有意义吗?好吧,可以想像自动驾驶汽车面对的任务,此情形要求汽车不断监控其环境,并解释下一个行人要做什么。通常,行人可以由大型3D边界框,或具有更多运动程度的骨骼来表示。通过更好,更快的3D语义分割,更多的自动驾驶感知算法将变得可行。
图分类
此子应用类别中的算法,接收图形或子图形作为其输入,并根据与该预测相关的概率值,来预测n个指定类之一。该预测通常以与图像分类非常相似的方式进行,因为所用网络有两个主要部分。
第一个是特征提取器,其功能是根据输入数据为手头的任务生成最佳表示。另外的则是一个或多个完全连接的层,以将结果回归约束到某个维度,而对于多类分类,softmax层是必需的。多类分类意味着对于我们拥有的每个输入,都可能有不止一种类与其对应。
针对这项更广泛的任务,令人激动的例子之一就是3D面部表情的分类。当前社会中,消费级产品已经配备了传感器,并具有足够的计算能力,来生成所需的3D数据结构。
同时,应用在这些数据结构上的算法的可解释性也变得越来越高。Gong等人最近推出了一种基于网格的方法,该方法仅依赖XYZ坐标,而无需任何辅助要素,该方法可在4DFAB上以接近80%的精度实现SOTA性能。