最近在项目中遇到这样一个问题,在进行数据查询的时候,特别的慢。
项目的基本情况
首先描述下项目的使用情况,数据库使用的是postgresql关系型数据库,主要数据存储字段data使用的类型是JSONB。
data字段存储数据,这个数据是包含了不少的图元,特别是在性能测试中,加入了特别多的图元 信息,最大的一条已经达到了3000多个SVG形成的图元。
查询分析
查询data字段长度,按照MB计算
SELECT id, DATA->>'name' AS filename , length(data::text)/1024/1024 AS leMB FROM t_re_data_inf AS trdi ORDER BY leMB DESC ;
查询的结果可以看到,最大的一条数据,这个data字段已经到19MB了,这个数据中的键值已经达到了4万多个。
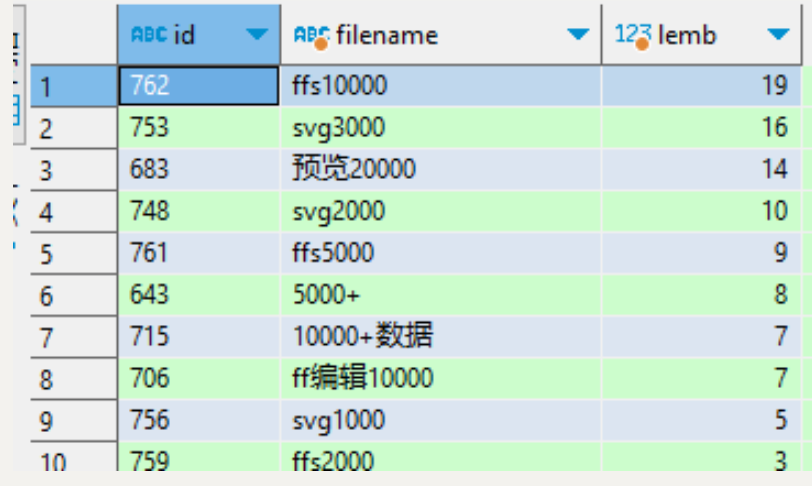
检查查询执行的SQL,发现会查询的是整一个data字段,查询速度就比较慢,实际业务分析发现,实际是不需要整个的数据,只需要data其中的十几个键值就行。这样返回给前端的数据就会小一点,能减少查询时间,详细就如方案一的设计。
优化方案一
去使用查询功能执行SQL,查询data中的一个键值,发现查询的速度在350毫秒左右。而在实际的业务场景中,查询的键值有十多个,在整体查询的时候,查询速度就在3.5秒左右了,这对整个业务执行来说是属于太慢了。在没有其他方式的时候也能作为一个备选方案。
select data->>'name' from data_info
优化方案二
采用索引的方式去减少查询时间。去检查在这个data字段中有没有存在一些索引,帮助去提升查询效率。实际发现没有相关的索引字段,然后根据索引的常见规则,去创建一些索引。
SELECT indexname ,indexdef,tablename FROM pg_indexes WHERE tablename = 'data_info'
这里需要注意,在创建索引的时候,需要注意几点:
CREATE INDEX data_info_id_idx ON meta.data_info (id);
-
确保索引字段不经常变动
-
确保索引字段是有唯一性的,没有大量的重复
-
使用索引的时候,是跟在where字段后面的
在使用索引后,实际的查询效率没有提升很大,也就放弃了这种方案,但是在一些其他的项目中,可以通过创建索引的方式去提升查询的效率。
优化方案三
在pgsql数据库本身性能的层面去优化查询的效率。
根据网上是一些文章,主要设置的参数包括:
- max_connections 设置客户端允许的最大连接数为100
- fsync on 强制将数同步更新到磁盘,修改为off
- shared_buffers 用做为缓存的数据,推荐设置为内存的1/4,不超1/2最好,能减少IO
- work_mem 用于提高内部排序操作的,设置值为1MB
- effective_cache_size 设置查询可用的最大内存,推荐设置为内存的1/2
实际上,设置了相关参数以后,实际的效率没有得到提升,说明在这个时候,数据库本身的性能是已经到了比较好的性能。
总结
在尝试优化的过程,已经从多方面进行了设置。总结出来,在遇见查询速度慢的时候,可以从几方面去分析,一是数据库本身性能层面去分析,一方面从索引方面去分析,还有就是优化查询SQL本身。