将原本一个时钟周期完成的较大的组合逻辑通过合理的切割后分由多个时钟周期完成。
将路径系统的分割成一个个数字处理单元(阶段),并在各个处理单元之间插入寄存器来暂存中间阶段的数据。被分割的单元能够按阶段并行的执行,相互间没有影响。所以最后流水线设计能够提高数据的吞吐率,即提高数据的处理速度。
在 FPGA 设计中,可以直接调用 IP 核来生成一个高性能的乘法器。在位宽较小的时候,一个周期内就可以输出结果,位宽较大时也可以流水输出。在能满足要求的前提下,可以谨慎的用 * 或直接调用 IP 来完成乘法运算。常数的乘法都会用移位相加的形式实现,例如:
A = A<<1 ; //完成A * 2
A = (A<<1) + A ; //对应A * 3
A = (A<<3) + (A<<2) + (A<<1) + A ; //对应A * 15
有时候数字电路在一个周期内并不能够完成多个变量同时相加的操作。所以数字设计中,最保险的加法操作是同一时刻只对 2 个数据进行加法运算,最差设计是同一时刻对 4 个及以上的数据进行加法运算。如果设计中有同时对 4 个数据进行加法运算的操作设计,那么此部分设计就会有危险,可能导致时序不满足
以下是官方给的RGB888 to YCbCr的算法公式,我们可以直接把算法移植到FPGA上,但是我们都知道FPGA无法进行浮点运算,所以我们采取将整个式子右端先都扩大256倍,然后再右移8位,这样就得到了FPGA擅长的乘法运算和加法运算了

在这里我们选择加3级流水线,就第一个Y分量而言,先计算括号中得乘法运算,消耗一个时钟,然后将括号中的数据求和,消耗一个时钟,这里为了计算方便,将128也扩大256倍,放到括号中,最终结果除以256就行了也就是右移8位,在FPGA中我们只需要舍弃低8位取高8位就行
//*************************************************************//
Y = (77 *R + 150*G + 29 *B)>>8 Cb = (-43*R - 85 *G + 128*B + 32768)>>8 Cr = (128*R - 107*G - 21 *B + 32768)>>8
//***************************************************************//
module rtl( input clk, input rst_n, input cmos_R0, cmos_G0, cmos_B0, output reg [7:0] img_Y1, output reg [7:0] img_Cb1, output reg [7:0] img_Cr1 ); reg [15:0] cmos_R1, cmos_R2, cmos_R3; reg [15:0] cmos_G1, cmos_G2, cmos_G3; reg [15:0] cmos_B1, cmos_B2, cmos_B3; always @(posedge clk or negedge rst_n) begin if(!rst_n)begin cmos_R1 <= 16'd0; cmos_G1 <= 16'd0; cmos_B1 <= 16'd0; cmos_R2 <= 16'd0; cmos_G2 <= 16'd0; cmos_B2 <= 16'd0; cmos_R3 <= 16'd0; cmos_G3 <= 16'd0; cmos_B3 <= 16'd0; end else begin cmos_R1 <= cmos_R0 * 8'd77; cmos_G1 <= cmos_G0 * 8'd150; cmos_B1 <= cmos_B0 * 8'd29; cmos_R2 <= cmos_R0 * 8'd43; cmos_G2 <= cmos_G0 * 8'd85; cmos_B2 <= cmos_B0 * 8'd128; cmos_R3 <= cmos_R0 * 8'd128; cmos_G3 <= cmos_G0 * 8'd107; cmos_B3 <= cmos_B0 * 8'd21; end end reg [15:0] img_Y0; reg [15:0] img_Cb0; reg [15:0] img_Cr0; always @(posedge clk or negedge rst_n) begin if(!rst_n)begin img_Y0 <= 16'd0; img_Cb0 <= 16'd0; img_Cr0 <= 16'd0; end else begin img_Y0 <= cmos_R1 + cmos_G1 + cmos_B1; img_Cb0 <= cmos_B2 - cmos_R2 - cmos_G2 + 16'd32768; img_Cr0 <= cmos_R3 - cmos_G3 - cmos_B3 + 16'd32768; end end always @(posedge clk or negedge rst_n) begin if(!rst_n)begin img_Y1 <= 8'd0; img_Cb1 <= 8'd0; img_Cr1 <= 8'd0; end else begin img_Y1 <= img_Y0 [15:8]; img_Cb1 <= img_Cb0 [15:8]; img_Cr1 <= img_Cr0 [15:8]; end end endmodule
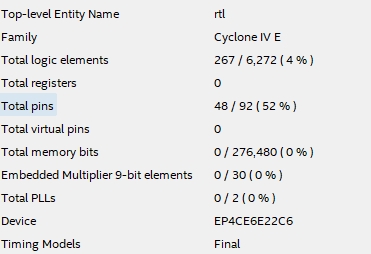
 这是编译后的报告
这是编译后的报告
让给我们看看写得一塌糊涂的verilog的报告
参考:
1、博客园:ninghechuan
2、csdn:https://blog.csdn.net/GJZGRB/article/details/134435972