一、选题的背景
台风,这是自然界中最强大的风暴之一。台风对人类社会产生了深远的影响,因此,深入理解它们的特性和行为模式至关重要。本研究的目标是通过对台风的风速和尺度进行大数据分析,来提供防灾减灾的科学依据。台风的风速和尺度是衡量其强度的两个重要指标。风速直接反映了台风的破坏力,而尺度则影响了台风影响的范围。通过对这两个指标的分析,我们可以了解到台风的强度分布、变化趋势以及可能的影响因素等信息。在现代大数据技术为我们提供了处理和分析大规模台风数据的可能性。通过Python等编程语言,我们可以使用各种数据分析方法(如统计分析、聚类分析、分类分析等)来挖掘数据中的有价值信息。这不仅可以提高我们对台风的认识,也可以为台风预测和防灾减灾提供数据支持。
二、大数据分析设计方案
1.本数据集的数据内容与数据特征分析
数据内容:
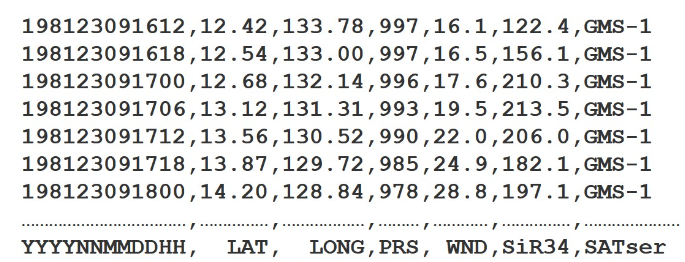
内容格式:
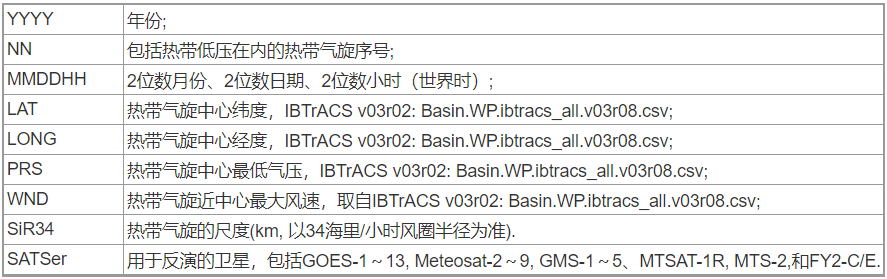
数据特征分析:
统计分析:对台风的最大风力速度,最大气旋尺度等数据进行统计
聚类分析:通过聚类分析,将具有相似特征的台风归为一类,这有助于我们理解不同类型的台风的特点。
线性回归:通过线性回归模型来预测台风的一些特性,例如路径、强度等。
2.数据分析的课程设计方案概述(包括实现思路与技术难点)
实现思路:
数据预处理:通过将台风数据数据集整理为结构化的数据集。进行数据清洗、去重、缺失值处理等预处理步骤。
数据分析:通过对数据进行深入的探索,包括可视化、计算描述性统计量等,以了解数据的分布和关系。
模型构建:根据问题的性质,选择合适的模型进行建模,如线性回归、聚类等。
技术难点:
数据预处理:数据预处理是一个复杂且耗时的过程,需要处理各种数据质量问题,如缺失值、异常值、重复值等。
模型特征选择:选择对模型有用的特征并创建新的特征是一项具有挑战性的任务,需要对数据和领域有较为深入的理解。
数据可视化:需要熟悉Python的数据可视化库,能选择合适的图表类型和展示方式。
三、数据分析步骤
1.数据源
数据来自中国气象局热带气旋资料中心 | 尺度分析资料 - 说明与资料下载 (typhoon.org.cn)
(https://tcdata.typhoon.org.cn/tcsize.html)
2.数据清洗
导入的库:
import pandas as pd
import matplotlib.pyplot as plt
import os
import numpy as np
from sklearn.ensemble import IsolationForest
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.preprocessing import LabelEncoder
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.cluster import KMeans#数据清洗
# 检查缺失值
missing_values = data.isnull().sum()
print("缺失值统计:")
print(missing_values)
# 使用均值填充缺失值
data['PRS'].fillna(data['PRS'].mean(), inplace=True)
data['WND'].fillna(data['WND'].mean(), inplace=True)
data_selected = data_selected.dropna()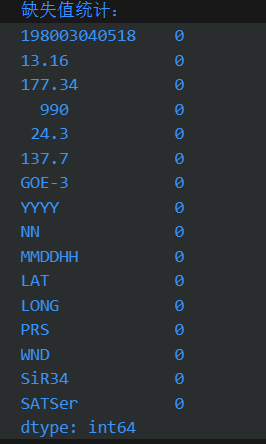
3.大数据分析过程及采用的算法
风速和尺度异常值处理:
features = ['PRS', 'WND']
# 创建异常值检测模型
model = IsolationForest(contamination=0.05) # 设置异常值比例为5%
# 训练模型并预测异常值
model.fit(data[features])
outliers = model.predict(data[features])
data['Outliers'] = outliers
# 处理异常值
data_no_outliers = data[data['Outliers'] == 1] # 保留非异常值
plt.figure(figsize=(10, 6))
plt.subplot(2, 1, 1)
plt.scatter(data['WND'], data['SiR34'], c=outliers, cmap='coolwarm')
plt.title('异常值处理前')
plt.xlabel('最大风速')
plt.ylabel('热带气旋尺度')
plt.subplot(2, 1, 2)
plt.scatter(data_no_outliers['WND'], data_no_outliers['SiR34'], color='blue')
plt.title('异常值处理后')
plt.xlabel('最大风速')
plt.ylabel('热带气旋尺度')
plt.tight_layout()
plt.show()结果: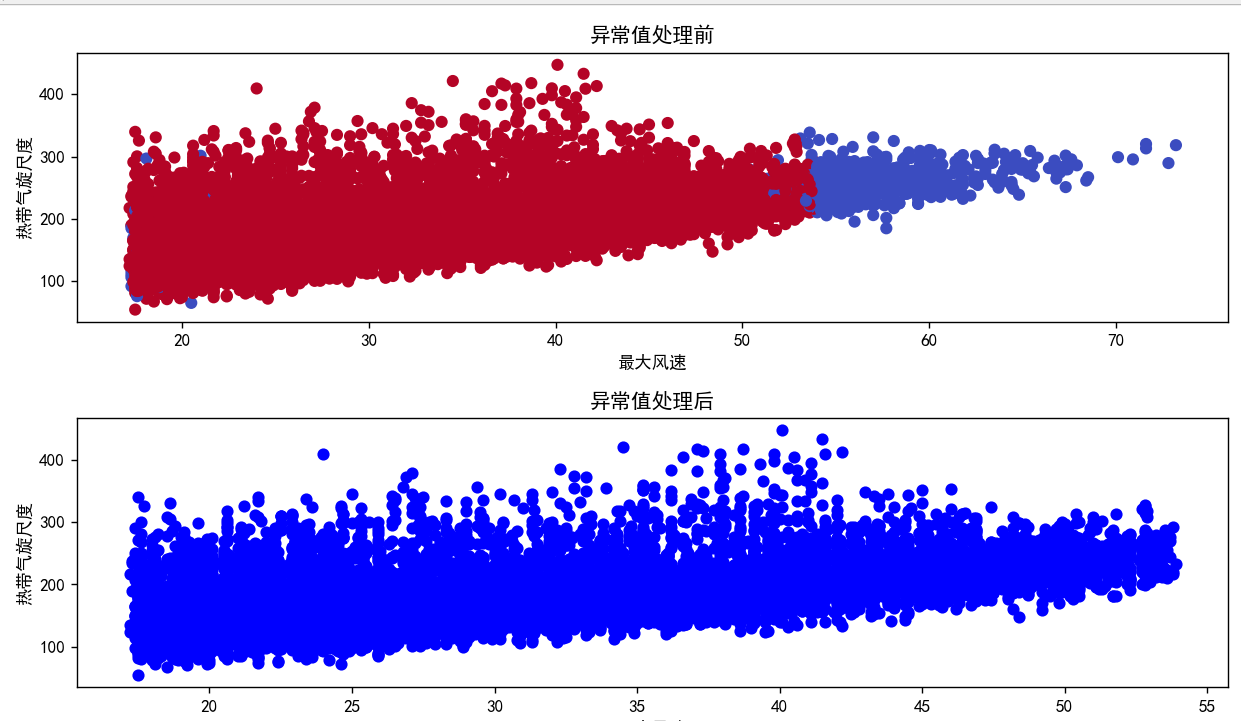
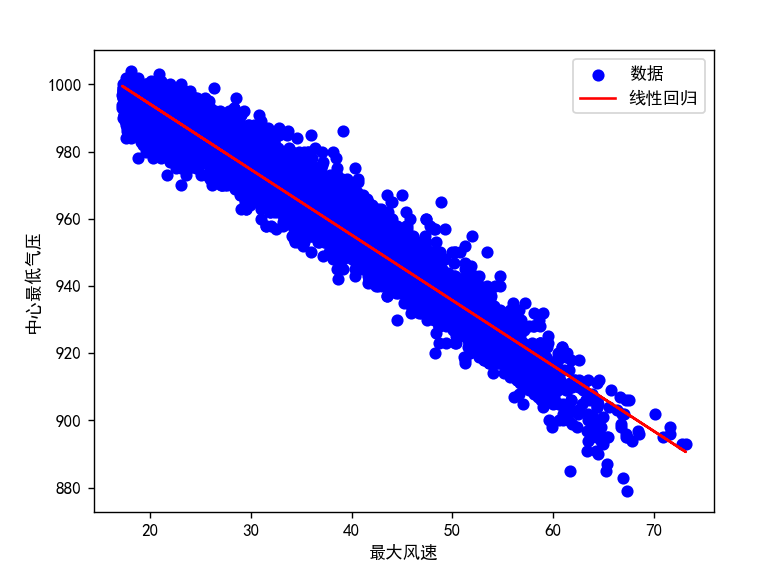
features = ['WND'] # 最大风速
target = 'PRS' # 中心最低气压
# 创建特征矩阵 X 和目标向量 y
X = data[features].values
y = data[target].values
# 创建线性回归模型对象
model = LinearRegression()
# 拟合模型
model.fit(X, y)
# 获取回归系数
coef = model.coef_
# 绘制散点图和回归线
plt.scatter(X, y, color='b', label='数据')
plt.plot(X, model.predict(X), color='r', label='线性回归')
plt.xlabel('最大风速')
plt.ylabel('中心最低气压')
plt.legend()
plt.show()结果:
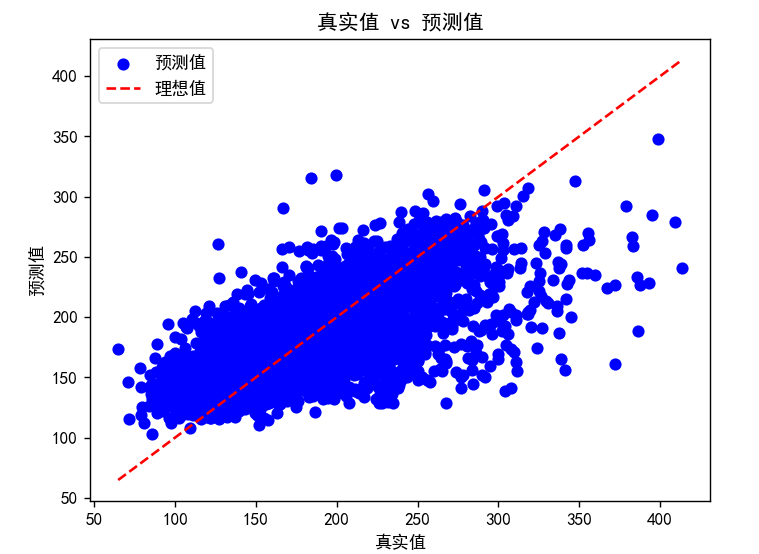
通过森林回归算法,来对台风尺度进行预测:
selected_features = ['PRS', 'WND', 'LAT', 'LONG', 'SiR34']
data_selected = data[selected_features]
data_selected = data_selected.dropna()
X = data_selected.drop('SiR34', axis=1)
y = data_selected['SiR34']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 建立随机森林回归器模型
random_forest = RandomForestRegressor(n_estimators=100, random_state=42)
random_forest.fit(X_train, y_train)
y_pred = random_forest.predict(X_test)
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
# 绘制预测结果和真实值的散点图
plt.scatter(y_test, y_pred, color='blue', label='预测值')
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], color='red', linestyle='--', label='理想值')
plt.xlabel('真实值')
plt.ylabel('预测值')
plt.title('真实值 vs 预测值')
plt.legend()
plt.show()结果:
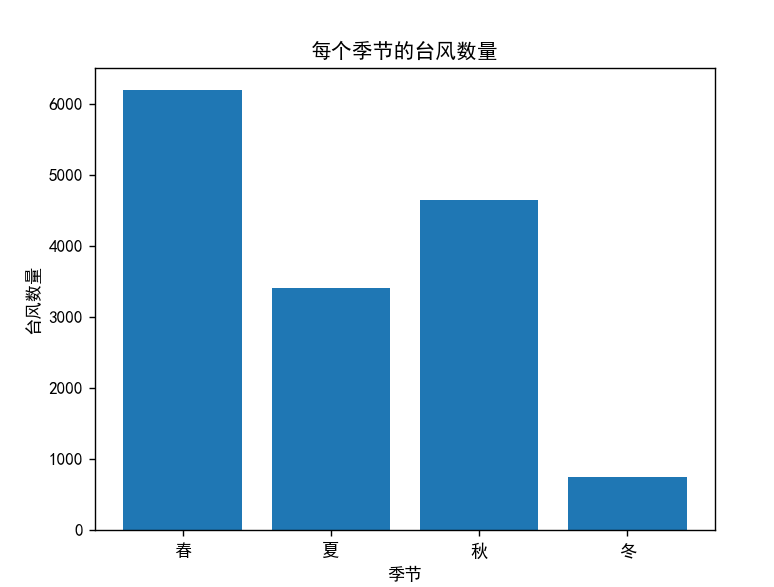
通过聚类算法来查找每个季节的台风数量:
data['MM'] = data['MMDDHH'].str[:2].astype(int)
# 使用K-means算法对月份进行聚类
kmeans = KMeans(n_clusters=4, n_init=10, random_state=0) # 假设我们想要将数据分为4个季节
data['SeasonCluster'] = kmeans.fit_predict(data[['MM']])
# 创建一个字典,映射季节的数字标签到季节的名称
season_names = {0: '春', 1: '夏', 2: '秋', 3: '冬'}
data['SeasonCluster'] = data['SeasonCluster'].map(season_names)
for season in season_names.values():
months_in_season = data[data['SeasonCluster'] == season]['MM'].unique()
print(f'{season}的月份范围:{months_in_season.min()} - {months_in_season.max()}')
typhoon_counts_per_season = data['SeasonCluster'].value_counts().loc[season_names.values()]
plt.bar(season_names.values(), typhoon_counts_per_season)
plt.xlabel('季节')
plt.ylabel('台风数量')
plt.title('每个季节的台风数量')
plt.show()结果:根据结果可以观察出,春秋两季往往是台风频发的季节,应当做好防台准备
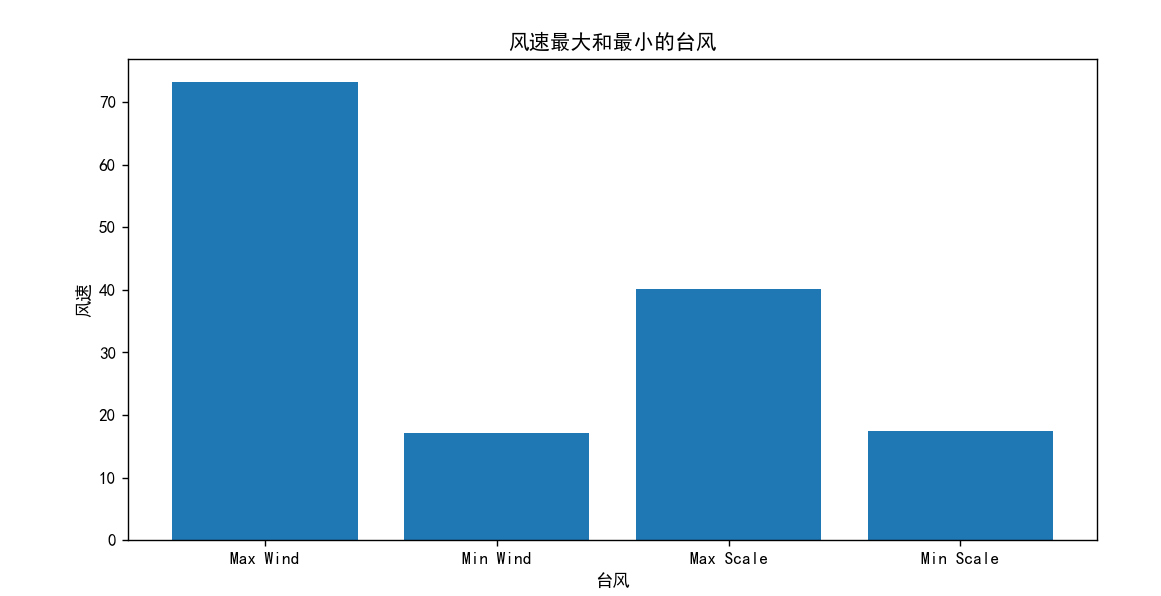
4.数据可视化
查找1980-2016年台风的极值
max_wind_typhoon = data.loc[data['WND'].idxmax()]
min_wind_typhoon = data.loc[data['WND'].idxmin()]
max_scale_typhoon = data.loc[data['SiR34'].idxmax()]
min_scale_typhoon = data.loc[data['SiR34'].idxmin()]
typhoons_to_compare = pd.DataFrame([max_wind_typhoon, min_wind_typhoon, max_scale_typhoon, min_scale_typhoon])
typhoon_ids = ['Max Wind', 'Min Wind', 'Max Scale', 'Min Scale']
typhoons_to_compare['ID'] = typhoon_ids
# 绘制风速的柱状图
plt.figure(figsize=(10, 5))
plt.bar(typhoons_to_compare['ID'], typhoons_to_compare['WND'])
plt.xlabel('台风')
plt.ylabel('风速')
plt.title('风速最大和最小的台风')
plt.show()
# 绘制尺度的柱状图
plt.figure(figsize=(10, 5))
plt.bar(typhoons_to_compare['ID'], typhoons_to_compare['SiR34'])
plt.xlabel('台风')
plt.ylabel('尺度')
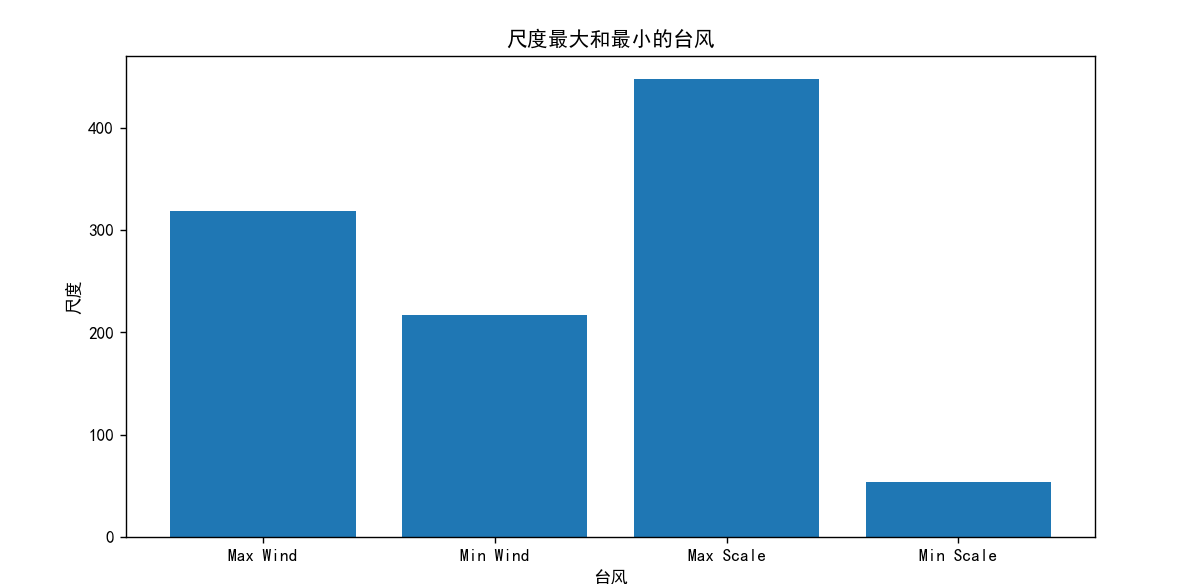
plt.title('尺度最大和最小的台风')
plt.show()结果:通过结果可以明显的看到风速最大的台风每秒超过了70m/s,而尺度最大的台风范围足足达到400km,难以想象居然如此的庞大
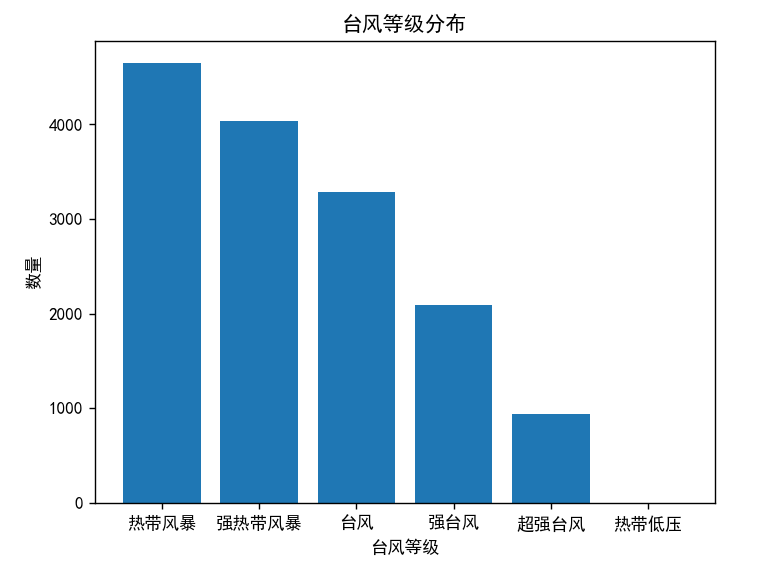
通过对风速的判断,实现台风划分等级来统计:
wind_speed_ranges = {
(10.8, 17.1): '热带低压',
(17.2, 24.4): '热带风暴',
(24.5, 32.6): '强热带风暴',
(32.7, 41.4): '台风',
(41.5, 50.9): '强台风',
(51.0, float('inf')): '超强台风'
}
data['等级'] = pd.cut(data['WND'], bins=[10.8, 17.1, 24.4, 32.6, 41.4, 50.9, float('inf')], labels=list(wind_speed_ranges.values()))
level_counts = data['等级'].value_counts()
print(level_counts)
level_counts = data['等级'].value_counts()
plt.bar(level_counts.index, level_counts.values)
plt.xlabel('台风等级')
plt.ylabel('数量')
plt.title('台风等级分布')
plt.show()结果:
使用folium库获取到地图信息,将台风具体显示在地图页面上方,可以看到虽然台风数量极多,但最终能登录我国的超强台风终究是少数(黑色为超强台风,红色为强台风,黄色为台风,其余为蓝色)。
china_data = data[(data['LONG'] >= 73) & (data['LONG'] <= 135) & (data['LAT'] >= 18) & (data['LAT'] <= 53)]
map = folium.Map(location=[35, 105], zoom_start=5)
level_color_mapping = {
'超强台风': 'black',
'强台风': 'red',
'台风': 'yellow',
'热带低压': 'blue',
'热带风暴': 'blue',
'强热带风暴': 'blue'
}
level_radius_mapping = {
'超强台风': 10,
'强台风': 7,
'台风': 5,
'热带低压': 4,
'热带风暴': 4,
'强热带风暴': 4
}
for index, row in china_data.iterrows():
level = row['等级']
color = level_color_mapping.get(level, 'gray') # 默认为灰色
radius = level_radius_mapping.get(level, 4) # 默认半径为4
label = f"{row['YYYY']}年{row['NN']}号热带气旋\n等级: {level}" # 编号和等级信息
folium.CircleMarker(location=[row['LAT'], row['LONG']], radius=radius, color=color, fill=True, fill_color=color, tooltip=label).add_to(map)
map.save("china_typhoon_map.html")
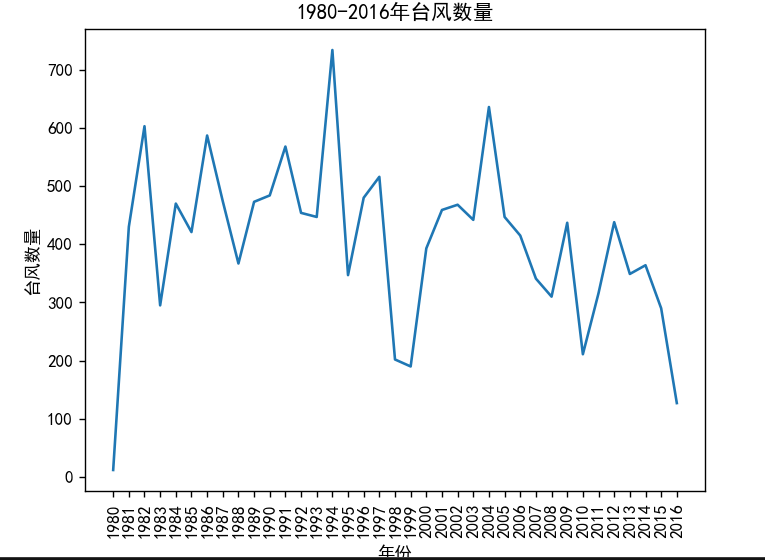
通过使用折线图来对台风近些年发展状况有一定的了解,
关于台风数量的变化,有一些研究表明:
- 自1995年以来,西北太平洋和南海台风的生成数量一直偏少,但登陆我国的台风比例却与气候平均值基本相当1。
- 清华大学近岸海洋动力学研究团队指出,登陆华南地区台风数量减少和登陆华东地区台风数量增加是两个独立的现象2。
- 亚洲地区台风委员会认为,近50年来,亚洲不同国家及地区登陆的台风数量变化比较大1。
这些研究结果表明,台风的数量并没有明显增加,可惜的是其强度却有所上涨。
# 筛选出1980-2016年的台风---折线图
typhoons = data[(data['YYYY'] >= '1980') & (data['YYYY'] <= '2016')]
yearly_counts = typhoons['YYYY'].value_counts().sort_index()
plt.figure()
plt.plot(yearly_counts.index, yearly_counts.values)
plt.title('1980-2016年台风数量')
plt.xlabel('年份')
plt.ylabel('台风数量')
plt.xticks(rotation=90)
plt.show()
yearly_avg_max_wind_speed = typhoons.groupby('YYYY')['WND'].mean()
plt.figure()
plt.plot(yearly_avg_max_wind_speed.index, yearly_avg_max_wind_speed.values)
plt.title('1980-2016年台风平均最大风速')
plt.xlabel('年份')
plt.ylabel('平均最大风速')
plt.xticks(rotation=90)
plt.show()

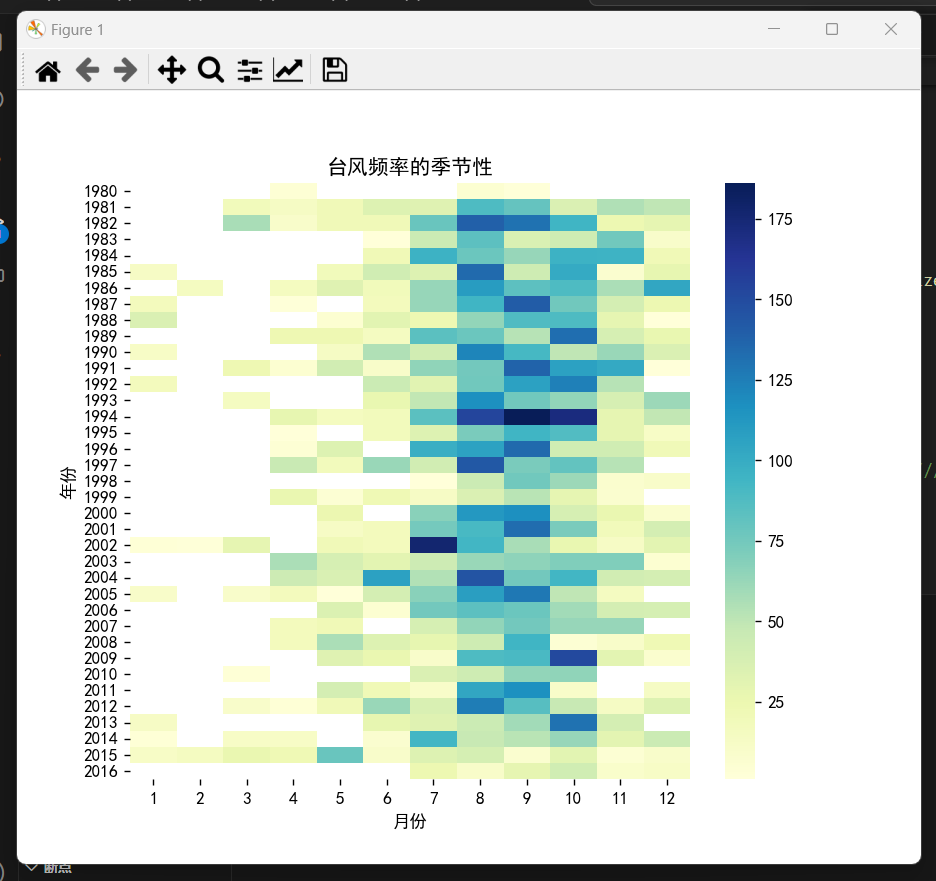
通过热力图以及散点图可以证实台风的发展数量与强度确实有所变化:
data['YYYY'] = data['YYYY'].astype(int)
data['MM'] = data['MMDDHH'].str[:2].astype(int)
average_strength_per_year_month = data.groupby(['YYYY', 'MM'])['WND'].mean().unstack()
# 绘制热力图
plt.figure(figsize=(10, 10))
sns.heatmap(average_strength_per_year_month, cmap='YlGnBu')
plt.title('台风强度随时间的变化')
plt.xlabel('月份')
plt.ylabel('年份')
plt.show()
#热力图-台风频率的季节性
typhoon_counts_per_year_month = data.groupby(['YYYY', 'MM']).size().unstack()
plt.figure(figsize=(10, 10))
sns.heatmap(typhoon_counts_per_year_month, cmap='YlGnBu')
plt.title('台风频率的季节性')
plt.xlabel('月份')
plt.ylabel('年份')
plt.show()
#折线图实现台风强度与频率的关系
typhoon_counts_per_year = data['YYYY'].value_counts()
average_strength_per_year = data.groupby('YYYY')['WND'].mean()
typhoon_data = pd.DataFrame({
'Count': typhoon_counts_per_year,
'Average Strength': average_strength_per_year
})
plt.scatter(typhoon_data['Count'], typhoon_data['Average Strength'])
plt.xlabel('台风数量')
plt.ylabel('平均强度')
plt.title('台风强度与频率的关系')
plt.show()

最后统计各卫星观测到的台风:
#统计卫星观测
typhoon_counts_per_satellite = data['SATSer'].value_counts()
percentages = 100. * typhoon_counts_per_satellite / typhoon_counts_per_satellite.sum()
labels = [n if percentages[n] >= 1 else '' for n in typhoon_counts_per_satellite.index]
fig, ax = plt.subplots(figsize=(15, 15))
def autopct(pct):
return ('%1.1f%%' % pct) if pct >= 1 else ''
ax.pie(typhoon_counts_per_satellite, labels=labels, autopct=autopct)
plt.title('每个卫星所观察到的台风数量')
max_strength_per_satellite = data.groupby('SATSer')['WND'].idxmax()
max_strength_typhoons = data.loc[max_strength_per_satellite]
print('每个卫星所观察到的最大风速台风:')
print(max_strength_typhoons)
plt.show()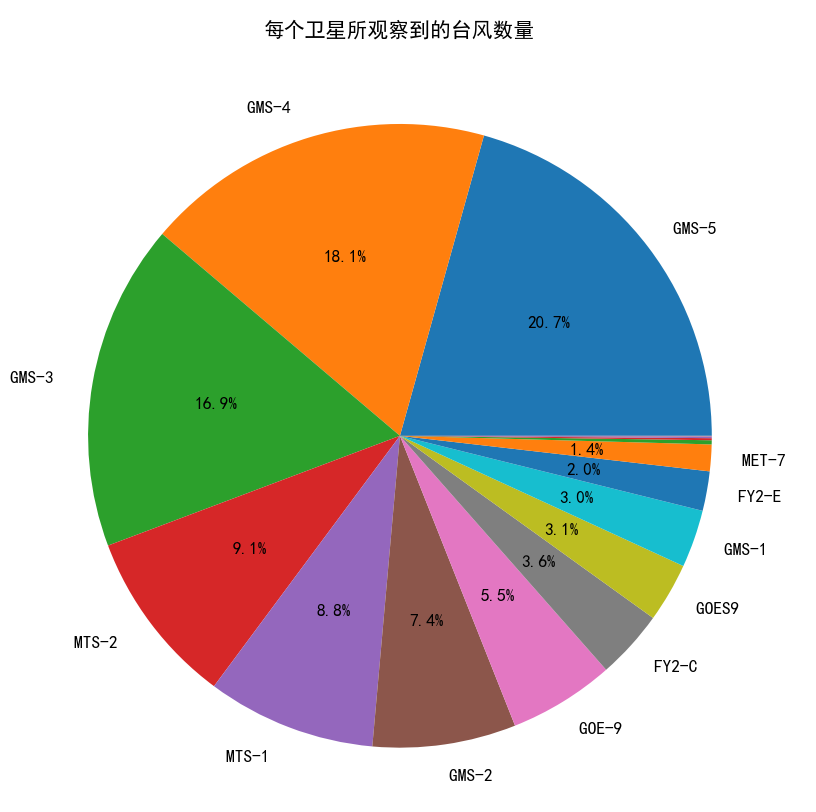
四、总结
通过本次的台风数据分析,我们发现了一些令人关注的趋势。近海登陆我国的台风数量随着时间的推移逐渐减少,然而,令人担忧的是,登陆的台风强度却在逐年增强。特别是在春秋两季交替的时期,台风的频发使得防台准备工作显得尤为重要。全球气候变暖可能会对台风的强度和数量产生影响。全球变暖可能会导致台风的强度增强,这是因为台风的一个主要动力源就是湿度,气候变暖导致水汽增加,为台风强度的增强提供了能量。此外,气候变暖还会使大气的垂直稳定度增强,这可能导致生成的台风更为强烈。西北太平洋的海温呈现出增暖的趋势,海温的变化也可能会导致台风强度的增强。
收获:
-
数据处理技能:掌握了如何清洗、整理和处理数据的技能,这些技能在数据分析中非常重要。
-
分析方法理解:对统计分析、聚类分析和线性回归等分析方法有了更深入的理解。
-
结果解读能力:你学会了如何解读分析结果,并将这些结果转化为有用的信息。数据分析的最终目标是提供有用的信息,而不仅仅是生成复杂的数据模型。
-
问题解决能力:在分析过程中,遇到了各种问题,如数据质量问题、模型选择问题等。解决这些问题的过程可能提高了我的问题解决能力。
-
对台风的理解:通过分析台风数据,我对台风的特性和行为有了更深入的理解。
代码:
import pandas as pd
import matplotlib.pyplot as plt
import os
import numpy as np
from sklearn.ensemble import IsolationForest
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.preprocessing import LabelEncoder
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.cluster import KMeans
import folium
import seaborn as sns
#字体
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
#检测
file_path = '1980_2016_retrieved_TCsize_2Pub_v2.csv'
if os.path.isfile(file_path):
print("文件存在")
else:
print("文件不存在")
# 读取CSV文件
data = pd.read_csv('1980_2016_retrieved_TCsize_2Pub_v2.csv')
# 定义提取函数
def extract_data(row):
YYYY = str(row[0]).zfill(4)[:4] # 年份,取前4位,并用0填充
NN = str(row[0]).zfill(6)[4:6] # 热带气旋序号,取第5-6位,并用0填充
MMDDHH = str(row[0]).zfill(12)[6:12] # 时间,取第7-12位,并用0填充
LAT = row[1] # 纬度
LONG = row[2] # 经度
PRS = row[3] # 中心最低气压
WND = row[4] # 最大风速
SiR34 = row[5] # 热带气旋尺度
SATSer = row[6] # 卫星
return {'YYYY': YYYY, 'NN': NN, 'MMDDHH': MMDDHH, 'LAT': LAT, 'LONG': LONG, 'PRS': PRS, 'WND': WND, 'SiR34': SiR34, 'SATSer': SATSer}
extracted_data = data.apply(extract_data, axis=1)
extracted_data = pd.DataFrame(extracted_data.tolist())
data = pd.concat([data, extracted_data], axis=1)
#机器学习实现对异常值检测
features = ['PRS', 'WND']
# 创建异常值检测模型
model = IsolationForest(contamination=0.05) # 设置异常值比例为5%
# 训练模型并预测异常值
model.fit(data[features])
outliers = model.predict(data[features])
# 标记异常值
data['Outliers'] = outliers
# 处理异常值
data_no_outliers = data[data['Outliers'] == 1] # 保留非异常值
# 可视化处理前后的结果
plt.figure(figsize=(10, 6))
plt.subplot(2, 1, 1)
plt.scatter(data['WND'], data['SiR34'], c=outliers, cmap='coolwarm')
plt.title('异常值处理前')
plt.xlabel('最大风速')
plt.ylabel('热带气旋尺度')
plt.subplot(2, 1, 2)
plt.scatter(data_no_outliers['WND'], data_no_outliers['SiR34'], color='blue')
plt.title('异常值处理后')
plt.xlabel('最大风速')
plt.ylabel('热带气旋尺度')
plt.tight_layout()
plt.show()
#数据清洗
# 检查缺失值
missing_values = data.isnull().sum()
print("缺失值统计:")
print(missing_values)
# 使用均值填充缺失值
data['PRS'].fillna(data['PRS'].mean(), inplace=True)
data['WND'].fillna(data['WND'].mean(), inplace=True)
features = ['WND'] # 最大风速
target = 'PRS' # 中心最低气压
X = data[features].values
y = data[target].values
model = LinearRegression()
model.fit(X, y)
coef = model.coef_
plt.scatter(X, y, color='b', label='数据')
plt.plot(X, model.predict(X), color='r', label='线性回归')
plt.xlabel('最大风速')
plt.ylabel('中心最低气压')
plt.legend()
plt.show()
# 特征选择
selected_features = ['PRS', 'WND', 'LAT', 'LONG', 'SiR34']
data_selected = data[selected_features]
# 数据清洗
data_selected = data_selected.dropna()
X = data_selected.drop('SiR34', axis=1)
y = data_selected['SiR34']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 建立随机森林回归器模型
random_forest = RandomForestRegressor(n_estimators=100, random_state=42)
random_forest.fit(X_train, y_train)
y_pred = random_forest.predict(X_test)
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
plt.scatter(y_test, y_pred, color='blue', label='预测值')
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], color='red', linestyle='--', label='理想值')
plt.xlabel('真实值')
plt.ylabel('预测值')
plt.title('真实值 vs 预测值')
plt.legend()
plt.show()
# 聚类
# 首先,我们从'MMDDHH'列中提取月份信息,并将其转换为整数类型
data['MM'] = data['MMDDHH'].str[:2].astype(int)
# 使用KMeans进行聚类
kmeans = KMeans(n_clusters=4, n_init=10, random_state=0)
data['SeasonCluster'] = kmeans.fit_predict(data[['MM']])
season_names = {0: '春', 1: '夏', 2: '秋', 3: '冬'}
data['SeasonCluster'] = data['SeasonCluster'].map(season_names)
# 打印每个季节的月份范围
for season in season_names.values():
months_in_season = data[data['SeasonCluster'] == season]['MM'].unique()
print(f'{season}的月份范围:{months_in_season.min()} - {months_in_season.max()}')
# 计算每个季节的台风数量
typhoon_counts_per_season = data['SeasonCluster'].value_counts().loc[season_names.values()]
# 绘制每个季节的台风数量
plt.figure(figsize=(10, 6))
plt.bar(season_names.values(), typhoon_counts_per_season, color=['#1f77b4', '#ff7f0e', '#2ca02c', '#d62728'])
plt.xlabel('季节', fontsize=14)
plt.ylabel('台风数量', fontsize=14)
plt.title('每个季节的台风数量', fontsize=16)
plt.grid(True)
plt.show()
spring_data = data[data['SeasonCluster'] == '春']
max_wind_speed_spring = spring_data['WND'].max()
plt.figure(figsize=(10, 6))
plt.bar('春季', max_wind_speed_spring, color='#1f77b4')
plt.xlabel('季节', fontsize=14)
plt.ylabel('最大风速', fontsize=14)
plt.title('春季的最大风速', fontsize=16)
plt.grid(True)
plt.show()
max_wind_typhoon = data.loc[data['WND'].idxmax()]
min_wind_typhoon = data.loc[data['WND'].idxmin()]
max_scale_typhoon = data.loc[data['SiR34'].idxmax()]
min_scale_typhoon = data.loc[data['SiR34'].idxmin()]
typhoons_to_compare = pd.DataFrame([max_wind_typhoon, min_wind_typhoon, max_scale_typhoon, min_scale_typhoon])
# 为每个台风创建一个标识符
typhoon_ids = ['Max Wind', 'Min Wind', 'Max Scale', 'Min Scale']
typhoons_to_compare['ID'] = typhoon_ids
# 绘制风速的柱状图
plt.figure(figsize=(10, 5))
plt.bar(typhoons_to_compare['ID'], typhoons_to_compare['WND'])
plt.xlabel('台风')
plt.ylabel('风速')
plt.title('风速最大和最小的台风')
plt.show()
# 绘制尺度的柱状图
plt.figure(figsize=(10, 5))
plt.bar(typhoons_to_compare['ID'], typhoons_to_compare['SiR34'])
plt.xlabel('台风')
plt.ylabel('尺度')
plt.title('尺度最大和最小的台风')
plt.show()
#台风分级
wind_speed_ranges = {
(10.8, 17.1): '热带低压',
(17.2, 24.4): '热带风暴',
(24.5, 32.6): '强热带风暴',
(32.7, 41.4): '台风',
(41.5, 50.9): '强台风',
(51.0, float('inf')): '超强台风'
}
# 新增一列"等级",根据中心风速进行分类
data['等级'] = pd.cut(data['WND'], bins=[10.8, 17.1, 24.4, 32.6, 41.4, 50.9, float('inf')], labels=list(wind_speed_ranges.values()))
# 打印台风等级统计结果
level_counts = data['等级'].value_counts()
print(level_counts)
# 统计台风等级数量
level_counts = data['等级'].value_counts()
# 绘制柱状图
plt.bar(level_counts.index, level_counts.values)
plt.xlabel('台风等级')
plt.ylabel('数量')
plt.title('台风等级分布')
plt.show()
# 筛选中国境内的台风数据
china_data = data[(data['LONG'] >= 73) & (data['LONG'] <= 135) & (data['LAT'] >= 18) & (data['LAT'] <= 53)]
map = folium.Map(location=[35, 105], zoom_start=5)
level_color_mapping = {
'超强台风': 'black',
'强台风': 'red',
'台风': 'yellow',
'热带低压': 'blue',
'热带风暴': 'blue',
'强热带风暴': 'blue'
}
# 定义台风等级和标记大小的映射关系
level_radius_mapping = {
'超强台风': 10,
'强台风': 7,
'台风': 5,
'热带低压': 4,
'热带风暴': 4,
'强热带风暴': 4
}
for index, row in china_data.iterrows():
level = row['等级']
color = level_color_mapping.get(level, 'gray') # 默认为灰色
radius = level_radius_mapping.get(level, 4) # 默认半径为4
label = f"{row['YYYY']}年{row['NN']}号热带气旋\n等级: {level}" # 编号和等级信息
folium.CircleMarker(location=[row['LAT'], row['LONG']], radius=radius, color=color, fill=True, fill_color=color, tooltip=label).add_to(map)
map.save("china_typhoon_map.html")
#筛选出1980-2016年的台风---折线图
typhoons = data[(data['YYYY'] >= '1980') & (data['YYYY'] <= '2016')]
yearly_counts = typhoons['YYYY'].value_counts().sort_index()
plt.figure()
plt.plot(yearly_counts.index, yearly_counts.values)
plt.title('1980-2016年台风数量')
plt.xlabel('年份')
plt.ylabel('台风数量')
plt.xticks(rotation=90)
plt.show()
yearly_avg_max_wind_speed = typhoons.groupby('YYYY')['WND'].mean()
plt.figure()
plt.plot(yearly_avg_max_wind_speed.index, yearly_avg_max_wind_speed.values)
# 添加标题和标签
plt.title('1980-2016年台风平均最大风速')
plt.xlabel('年份')
plt.ylabel('平均最大风速')
# 将x轴的标签旋转90度
plt.xticks(rotation=90)
# 显示图表
plt.show()
data['YYYY'] = data['YYYY'].astype(int)
data['MM'] = data['MMDDHH'].str[:2].astype(int)
# 计算每年每月的平均台风强度
average_strength_per_year_month = data.groupby(['YYYY', 'MM'])['WND'].mean().unstack()
# 绘制热力图
plt.figure(figsize=(10, 10))
sns.heatmap(average_strength_per_year_month, cmap='YlGnBu')
plt.title('台风强度随时间的变化')
plt.xlabel('月份')
plt.ylabel('年份')
plt.show()
#热力图-台风频率的季节性
typhoon_counts_per_year_month = data.groupby(['YYYY', 'MM']).size().unstack()
# 绘制热力图
plt.figure(figsize=(10, 10))
sns.heatmap(typhoon_counts_per_year_month, cmap='YlGnBu')
plt.title('台风频率的季节性')
plt.xlabel('月份')
plt.ylabel('年份')
plt.show()
# 计算每年的台风数量
typhoon_counts_per_year = data['YYYY'].value_counts()
# 计算每年的平均台风强度
average_strength_per_year = data.groupby('YYYY')['WND'].mean()
typhoon_data = pd.DataFrame({
'Count': typhoon_counts_per_year,
'Average Strength': average_strength_per_year
})
# 绘制散点图
plt.scatter(typhoon_data['Count'], typhoon_data['Average Strength'])
plt.xlabel('台风数量')
plt.ylabel('平均强度')
plt.title('台风强度与频率的关系')
plt.show()
#统计卫星观测
typhoon_counts_per_satellite = data['SATSer'].value_counts()
percentages = 100. * typhoon_counts_per_satellite / typhoon_counts_per_satellite.sum()
labels = [n if percentages[n] >= 1 else '' for n in typhoon_counts_per_satellite.index]
# 创建一个新的图形和子图
fig, ax = plt.subplots(figsize=(15, 15))
def autopct(pct):
return ('%1.1f%%' % pct) if pct >= 1 else ''
ax.pie(typhoon_counts_per_satellite, labels=labels, autopct=autopct)
plt.title('每个卫星所观察到的台风数量')
max_strength_per_satellite = data.groupby('SATSer')['WND'].idxmax()
max_strength_typhoons = data.loc[max_strength_per_satellite]
print('每个卫星所观察到的最大风速台风:')
print(max_strength_typhoons)
plt.show()
# 计算每个卫星所观察到的台风的平均风速
mean_strength_per_satellite = data.groupby('SATSer')['WND'].mean()
print('每个卫星所观察到的台风的平均风速:')
print(mean_strength_per_satellite)
fig, ax = plt.subplots(figsize=(15, 7))
ax.bar(mean_strength_per_satellite.index, mean_strength_per_satellite)
plt.title('每个卫星所观察到的台风的平均风速')
plt.xlabel('卫星')
plt.ylabel('平均风速')
plt.show()