NO.1 由来
在平时打项目时,拿到入口点后就会遇到一个比较尴尬的问题。扫描吧怕点掉了,不扫就只能手动敲ip访问,耗时耗力。就想着用python写个调浏览器扫描的脚本。
NO.2 代码
只适合扫描小网段资产,毕竟目的就是尽量模拟正常访问的流量。写的一般,有需要的可以自己改改
#调用浏览器扫描网段web,模拟人工访问。
#需安装playwright,默认调用chromium/edge。若无法使用需安装Playwright内置浏览器python -m playwright install
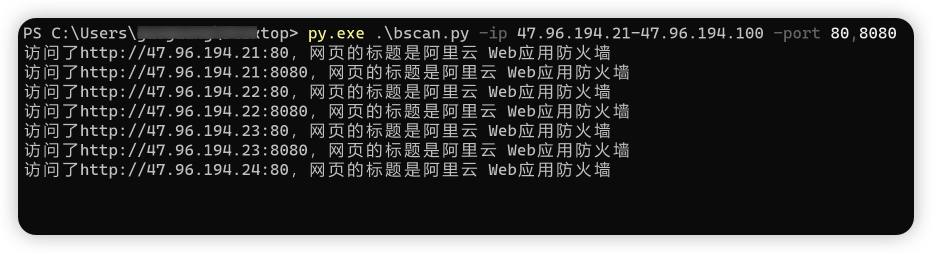
#使用方法 python bbscan.py -ip 10.88.2.123-10.88.2.130 -port 80,8080
import playwright
from playwright.sync_api import sync_playwright
import sys
import time
# 定义一个函数,将ip地址转换为整数
def ip_to_int(ip):
# 分割ip地址为四个部分,并将每个部分转换为整数
parts = [int(p) for p in ip.split('.')]
# 按位移运算合并为一个整数,并返回
return sum(p << (24 - i * 8) for i, p in enumerate(parts))
# 定义一个函数,将整数转换为ip地址
def int_to_ip(n):
# 按位移运算分割整数为四个部分,并将每个部分转换为字符串
parts = [str((n >> (24 - i * 8)) & 255) for i in range(4)]
# 用点号连接为一个ip地址,并返回
return '.'.join(parts)
# 定义一个空列表,用于存储ip地址
ips = []
# 获取命令行参数,并转换为一个字典
args = dict(zip(sys.argv[1::2], sys.argv[2::2]))
# 如果字典中有-ip键,那么获取其值作为ip值
if '-ip' in args:
ip = args['-ip']
# 如果ip值包含-,那么表示是一个范围,需要分割为起始ip和结束ip
if '-' in ip:
start_ip, end_ip = ip.split('-')
# 将起始ip和结束ip转换为整数,并生成一个范围
start_n = ip_to_int(start_ip)
end_n = ip_to_int(end_ip)
# 遍历范围中的每个整数,并将其转换为ip地址,添加到列表中
ips.extend(int_to_ip(n) for n in range(start_n, end_n + 1))
# 否则,表示是一个单个的ip地址,直接添加到列表中
else:
ips.append(ip)
# 如果字典中有-port键,那么获取其值作为port值
if '-port' in args:
port = args['-port']
# 如果port值包含逗号,那么表示是多个端口,需要分割为一个列表
if ',' in port:
ports = port.split(',')
# 否则,表示是一个单个的端口,直接转换为一个列表
else:
ports = [port]
# 使用playwright.sync_api模块创建一个同步的浏览器上下文
with sync_playwright() as p:
browser_context = p.chromium.launch()
# 遍历列表中的每个ip地址和端口,拼接成一个url,并访问该url
for ip in ips:
for port in ports:
url = f'http://{ip}:{port}'
# 使用浏览器上下文的new_page方法创建一个新的页面,并使用try-except语句来处理超时异常
page = browser_context.new_page()
try:
#请求url,3000毫秒超时
page.goto(url,timeout=3000)
# 获取网页的标题,并打印出来
title = page.title()
print(f'访问了{url},网页的标题是{title}')
# 等待1秒钟
time.sleep(1)
except (playwright._impl._api_types.Error, playwright._impl._api_types.TimeoutError) as e:
# 如果发生超时异常,打印出错误信息,并继续执行下一个url
print(f'访问{url}超时,错误信息是{e}')
finally:
# 最后,在finally中关闭页面对象
page.close()
# 关闭浏览器上下文对象
browser_context.close()
效果如下,如果在强检测环境下可以更改访问间隔。