Explicit Boundary Guided Semi-Push-Pull Contrastive Learning for Supervised Anomaly Detection
Introduction
只关注正常样本可能会限制AD模型的可判别性。如图1(a)所示,在没有异常情况的情况下,决策边界通常是隐式的,没有足够的判别性。在无监督异常检测中,由于缺乏对异常的了解,导致可判别性不足。
半监督学习利用了部分已知异常,但是已知的异常并不能代表所有的异常。这些方法可能受到已知异常的影响,无法推广到未见异常

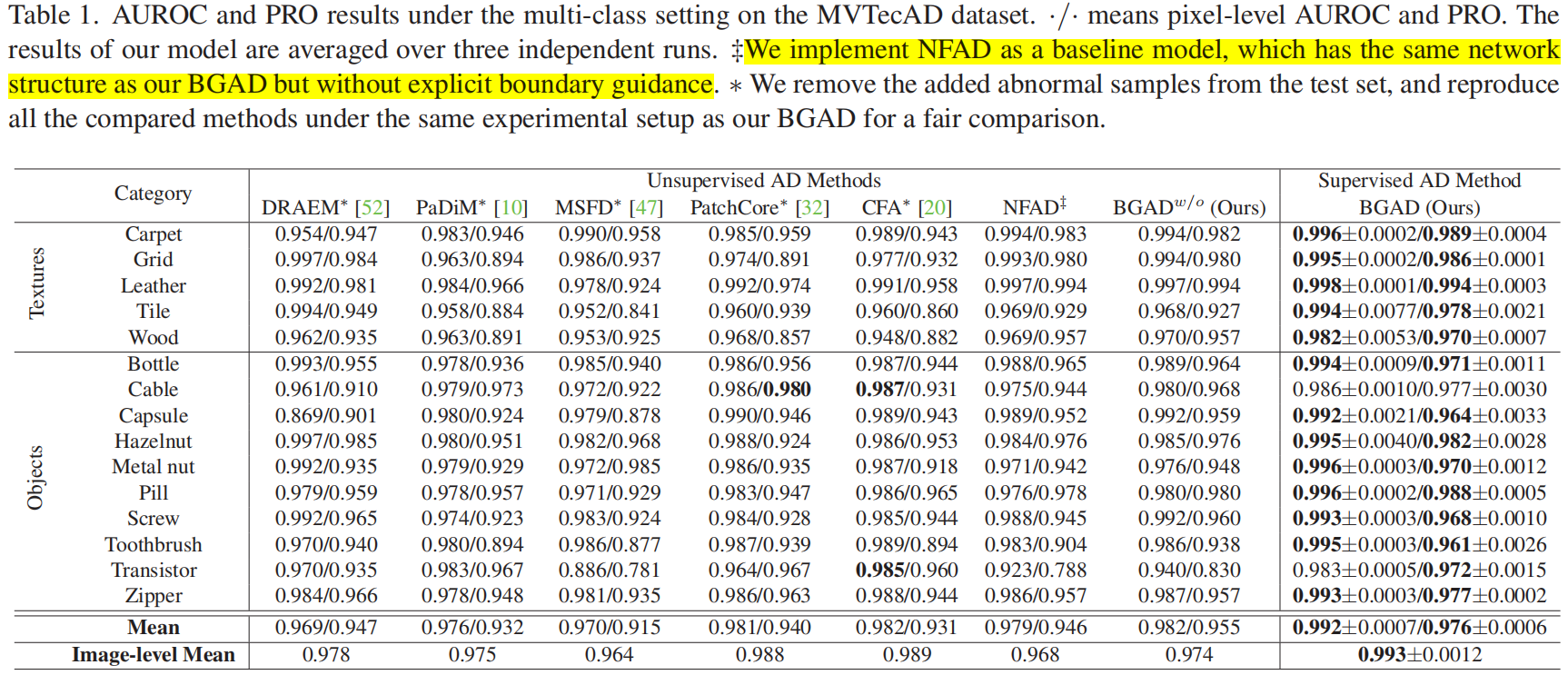
Boundary Guided Anomaly Detection (BGAD)模型。
Explicit Boundary Generating
我们首先采用归一化流来学习一个归一化的正常特征分布,并得到一个明确的分离边界,该边界靠近正常特征分布边缘,由一个超参数 \(\beta\) 控制(即图1(b)中的正常边界)。所得到的显式分离边界仅依赖于正常分布,与异常样本没有关系,因此可以缓解已知异常不足所引起的偏差问题。
Boundary Guided Optimizing
在 BG-SPP 损失下,只有对数似然值小于边界的正常特征被拉到一起,形成更紧凑的正常特征分布(半拉);而对数似然值大于边界的异常特征,则被推离边界超过一定的边缘区域(半推)。
此外,异常的稀缺也是一个关键问题,可能导致特征学习效率低下。因此,我们提出了RandAugment-based Pseudo Anomaly Generation,它可以通过在正常样本中创建局部不规则来模拟异常,以解决稀缺性挑战。
贡献点:
- 提出了一种新的显式边界引导监督AD建模方法,该方法通过精心设计的显式边界生成和边界指导优化,有效地利用了正常样本和异常样本。采用该方法可以同时获得较高的可判别性和较低的偏差风险。
- 为了有效地利用一些已知的异常,我们提出了BG-SPP损失,将正常特征聚集在一起,同时将异常特征推离分离边界,从而可以学习更多的判别特征。
- SOTA
Our Proposed Approach
Problem Statement
有监督的AD训练集由正常图像和一些异常图像组成。\(\mathcal{I}_{train}=\mathcal{I}^n\cup \mathcal{I}^a\),其中 \(\mathcal{I}^n=\{I^n_i\}_{i=1}^{N_0},\mathcal{I}^a=\{I_j^a\}_{j=1}^{M_0}(M_0 \ll N_0)\)。\(M_0\) 个异常是从可见的异常类 \(\mathcal{S}_s \sub \mathcal{S}\) 中随机采样的,其中 \(\mathcal{S} = \mathcal{S}_s \cup \mathcal{S}_u\) 表示所有可见和不可见的异常类。目标是学习一个模型 \(m : \mathcal{I} \rightarrow \mathbb{R}\),它能够对seen和unseen异常分配比正常样本高的异常分数
Overview
图2概述了我们提出的方法。
Learning Normal Feature Distribution by Normalizing Flow
为了找到一个与异常无关的分离边界,首先要学习一个简化的正常特征的分布。我们的方法采用归一化流[13,14]来学习正常特征的分布。
Conditional Normalizing Flow
采用与 real NVP 相同的思路。
使用real NVP的可逆性来对提取好的特征 \(\mathcal{X}\) 进行密度估计。
由模型pθ(x)估计的输入分布可根据变量变换公式计算如下
参数集 \(\theta\) 通过优化整个训练分布 \(p_\mathcal{X}\) 的对数似然得到
为了保存位置信息,我们添加了二维感知的位置嵌入。
Learning Normal Feature Distribution
潜变量分布 \(p_\mathcal{Z}(z),z \in \mathbb{R}^d\) 一般可以假设服从多元高斯分布
其中,\(\mu\) 为均值,\(\Sigma\) 为协方差。为了进一步简化,假设正常特征的隐变量服从 \(\mathcal{N}(0,\boldsymbol{\Iota})\)。用 \(p_\mathcal{Z}(z)=(2\pi)^{-\frac{d}{2}}e^{-\frac{1}{2}z^Tz}\) 替换公式1,则公式2中的优化目标变为
学习正常特征分布的最大似然损失函数定义为
Finding an Explicit and Compact Separating Boundary
由于特征的高维特征,因此我们考虑从异常分数分布中寻找边界。由于 CNFlow 生成的对数似然可以等效地转换为异常分数,因此我们在对数似然分布上选择边界。
Anomaly Scoring
归一化流的优点是,我们可以估计每个输入特征 \(x\) 的精确的对数似然 \(\log p(x)\),如下所述
异常分数计算如下:
Finding Explicit Separating Boundary
-
Building normal log-likelihood distribution
获得所有正常特征的似然对数 \(\mathcal{P}_n=\{\log p_i\}_{i=1}^N\)。\(\mathcal{P}_n\) 可以用来近似所有正常特征的对数似然分布
-
Finding explicit normal and abnormal boundary
我们定义了一个位置超参数 \(\beta\) 来控制从边界到中心的距离。我们选择排序后的正常样本的对数似然分布的 \(\beta\)-th百分位数(例如 \(\beta = 1\))作为正常边界 \(b_n\),这也表明正常样本中假阳率的上界为 \(\beta\)%。为了使特征学习更加鲁棒,我们进一步引入了一个边缘超参数 \(\tau\) (例如,\(\tau=0.1\)),并定义了一个异常边界 \(b_a=b_n - \tau\) (见图2)。
Learning More Discriminative Features by Boundary Guided Semi-Push-Pull
我们的 BG-SPP 损失可以利用边界 \(b_n\) 作为对比目标(边界引导),只将对数似然小于 \(b_n\) 的正常特征拉到一起(半拉),而将对数似然大于 \(b_a\) 的异常特征推到 \(b_n\) 之外至少超过边界 \(\tau\) (半推)。
因为对数似然值的范围在 \((-\infty,0]\),较大的范围区间使得选择间隔超参 \(\tau\) 变得困难。因此我们定义了一个足够大的归一项 \(\alpha_n\) (如 \(\alpha = 10\)),并使用它将对数似然归一化到范围 \([-1,0]\)。我们指出,在eq(8)中,极小的对数似然(小于 \(- 1\))可以排除在BG-SPP损失之外,因为这些对数似然可以很容易地划分为异常。
因此,最小化BG-SPP的损失将鼓励所有的对数似然 \(\mathcal{P}\) 分布在区域 \([-1,b_a]\) 或 \([b_n,0]\)。
在第二个训练阶段,目标函数如下
Generalization Capability to Unseen Anomalies
以前的监督异常检测方法通常被建模为二元分类任务,将异常视为正样本。然而,这些模型过于依赖已知的异常。因此,这些模型可能会过拟合已知的异常,无法泛化到未知的异常。我们的方法可以缓解严重的偏差问题,原因如下:
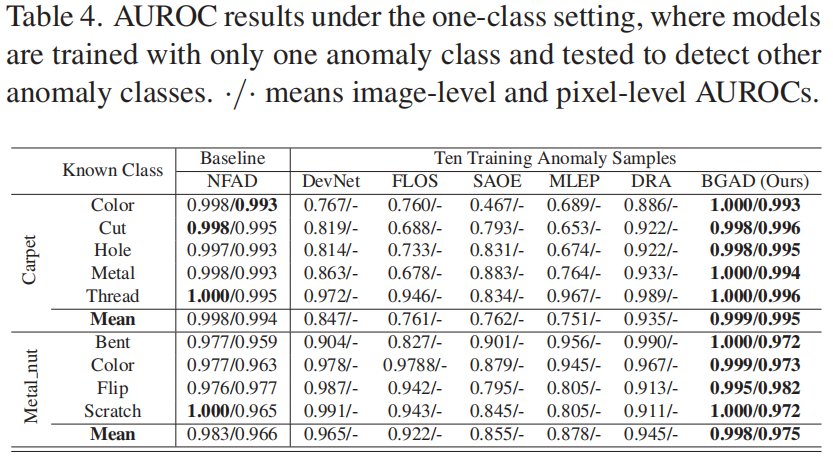
- 获得的明确分界线仅依赖于正常特征分布,与异常样本无关,这意味着最终的决策边界主要取决于正常分布,而不会受到异常的影响(见表4)。
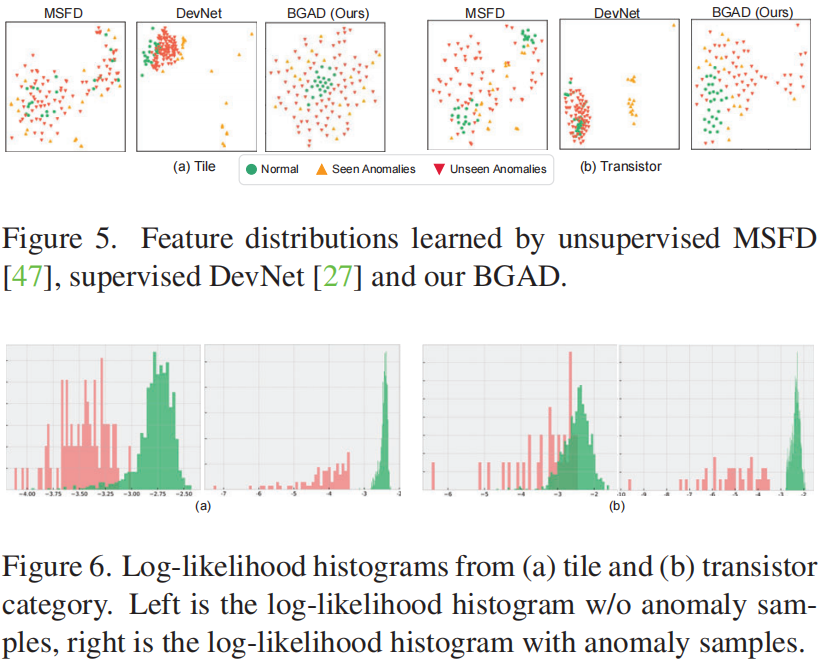
- 我们的方法仍然使用正常分布来确定异常,我们的方法可以形成更紧凑和有区别性的正常特征分布(这也有助于检测未知的异常),而不是在正常和已知异常之间形成决策边界(见图5)。
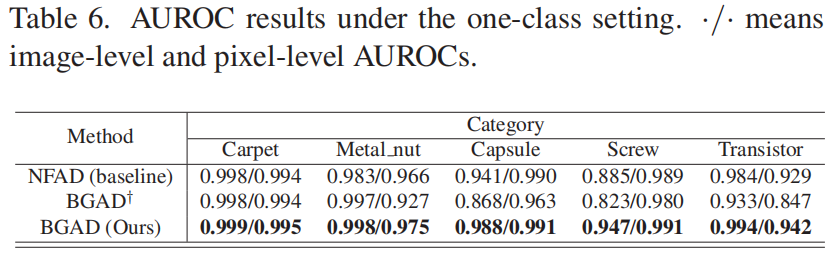
- 我们的方法中的半推挤机制不会强迫异常尽量偏离正常分布,这可能会导致对已知异常的过拟合,而只是将异常推到边界区域之外(见表6中的消融实验)。
RandAugment-based Pseudo Anomaly Generation
Constructing Augmentation Sets
选择 \(K\) 个可用的图像变换来构造一个数据增强集合 \(\mathcal{T}:= \{T_1,\dots,T_K|T_K : \mathcal{I} \rightarrow \mathcal{I}\}:\{\text{Flip,Rotate,Transpose,Noise,Distortion,Brightness,Sharpness,Translate, Blur}\}\)
Random Augmentation
随机选择一个增强子集 \(T_{RS} \sub \mathcal{T}\),包含 \(S\) 个变换,用来增强异常样本 \((I^a)^{'}=T_{RS}(I^a), I^a \in \mathcal{I}^a\)
Selecting Pasting Locations
考虑到异常一般只出现在目标区域,我们应该限制模拟异常在目标区域的位置。我们采用前景掩蔽策略,利用灰度二值化阈值算法对前景对象 \(M_I = Binary (I^n),I^n \in \mathcal{I}^n\) 进行有效定位。然后,我们可以从目标区域 (\(M_I = 1\)) 中选择一个随机的粘贴位置 \(r_a=Rand(M_I=1)\) ,以避免在背景中产生异常区域。
Cutting Anomalies
我们对增强异常样本的异常区域进行切割:\(\mathcal{R}_a = Cut ((I^a)^{'})\)。
Pasting Anomalies
我们将裁剪后的异常区域粘贴到选定位置 \(r_a\) 处的正常样本中,生成模拟异常样本: \(I_{sa}=Paste(I^n, \mathcal{R}_a, r_a)\)。
Experiments
Evaluation Metrics
在评估方面,异常检测中使用的标准度量是AUROC。图像级别的AUROC用于异常检测,像素级别的AUROC用于评估异常定位。为了平等权衡各种大小的真实异常区域,我们还采用了在[5]中提出的Per-Region-Overlap(PRO)曲线度量。
Experimental Settings
Multi-Class Setting
多类别设置旨在评估异常检测模型在检测已知异常类别方面的性能。在这种设置下,已知的异常是从测试集中的现有异常类别中随机抽取的一些异常样本。然后,在测试期间,我们会仔细排除这些添加的异常样本,确保测试集不包含这些已知异常样本。
One-Class Setting
单类别设置旨在评估异常检测模型在检测未知异常类别方面的泛化能力。在这种设置下,已知的异常仅从一个异常类别中随机抽样,而且测试集中的这个异常类别的所有异常样本都被移除,以确保测试集只包含未知的异常类别。
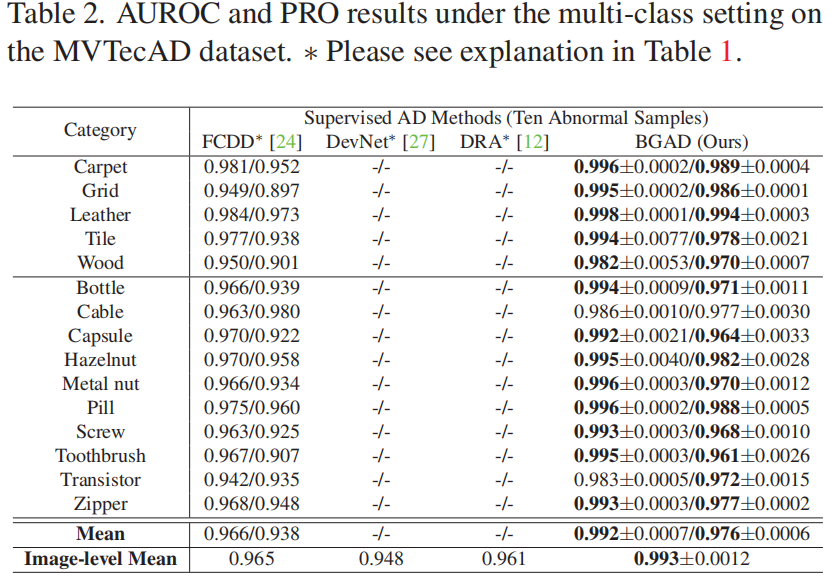
Results under the Multi-Class Setting
MVTecAD
我们将NFAD实现为基线模型,该模型具有与BGAD相同的网络结构,但没有明确的边界指导。
BTAD
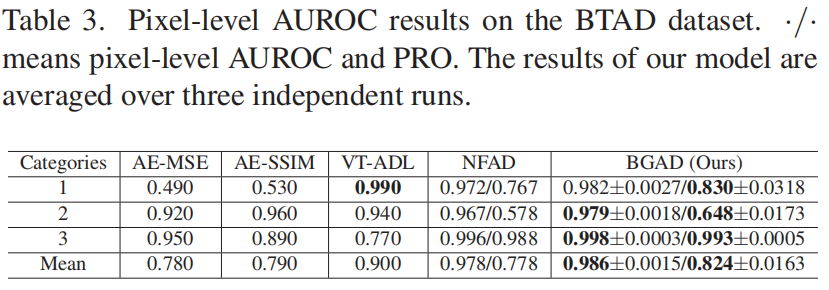
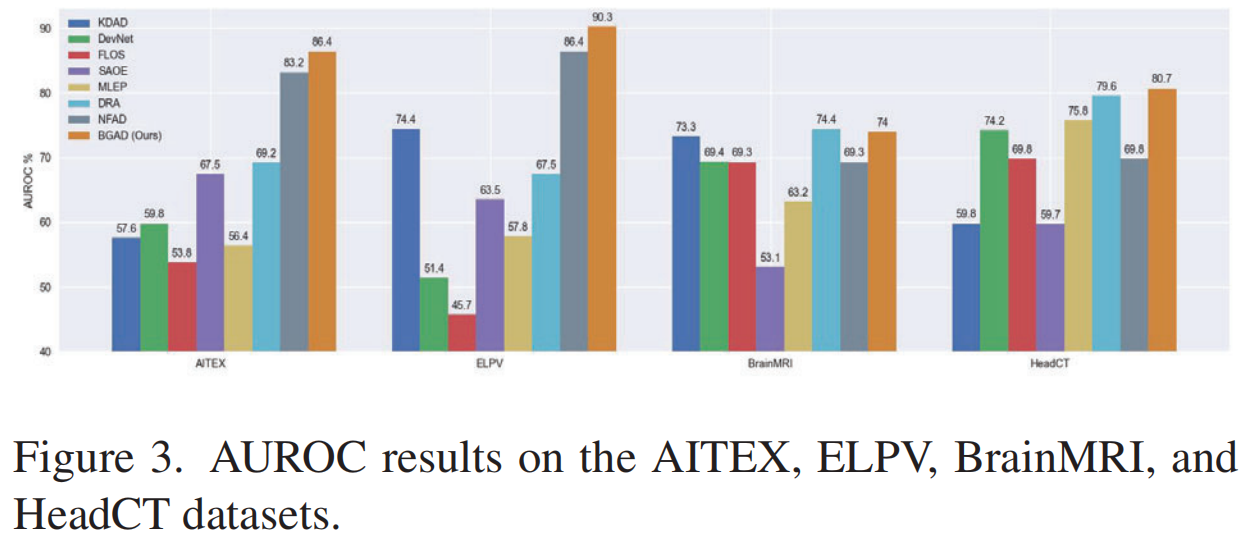
Other Datasets
Results under the One-Class Setting
Comparison to Supervised AD Methods
Ablation Study
Experiments On Hard Subsets
为了进一步证明我们的方法检测复杂异常的能力,我们从MVTecAD数据集中构建了两个更困难的子集,并在这两个子集上进行了实验。
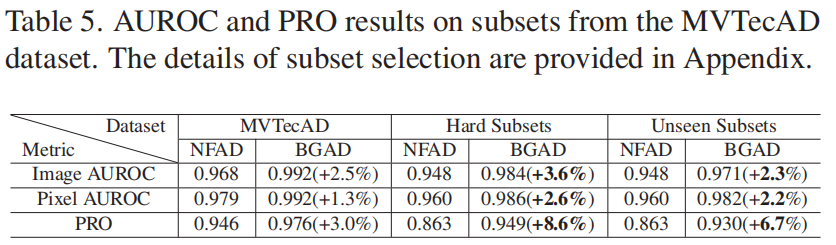
Generalization to Hard Subsets
我们使用简单的子集作为训练集,并在困难子集上验证结果,以探索模型的可推广性。简单子集是通过从原始数据集中排除上一段提到的困难子集而形成的。实验结果如表5所示。
Effect of Semi-Push-Pull Mechanism
我们实现了BGAD的一个变体(称为BGAD†),它不使用BG-SPP损失,而使用传统的对比损失。比较结果如表6所示,附录中还有更多结果(表11)。可以看出,BGAD†的性能不如BGAD,并且甚至不如基线NFAD(尤其是对于一些复杂的类别,例如Capsule、Screw、Transistor)表现更差。
原因是BGAD†的完全推挤机制会鼓励异常特征至少偏离正常分布的足够大的边界,这可能使模型更倾向于生成较大的异常分数,从而导致模型更容易过拟合已知的异常。因此,BGAD†可能会为正常特征生成较大的异常分数,这将显著降低AUROC指标。然而,在我们的BGAD中的半推挤机制只改变了模糊区域,对整个正常和异常分布的影响较小。因此,BG-SPP损失不会使模型倾向于生成较大的异常分数,更有利于减轻模型对已知异常的过拟合。
Qualitative Results
我们在MVTecAD数据集中可视化了一些异常定位结果,如图4所示。我们的BGAD可以生成更精确的异常定位图(见图4中的第1、3、4、5、6列),甚至可以生成优于地面真相的异常图(见图4中的第2列)。

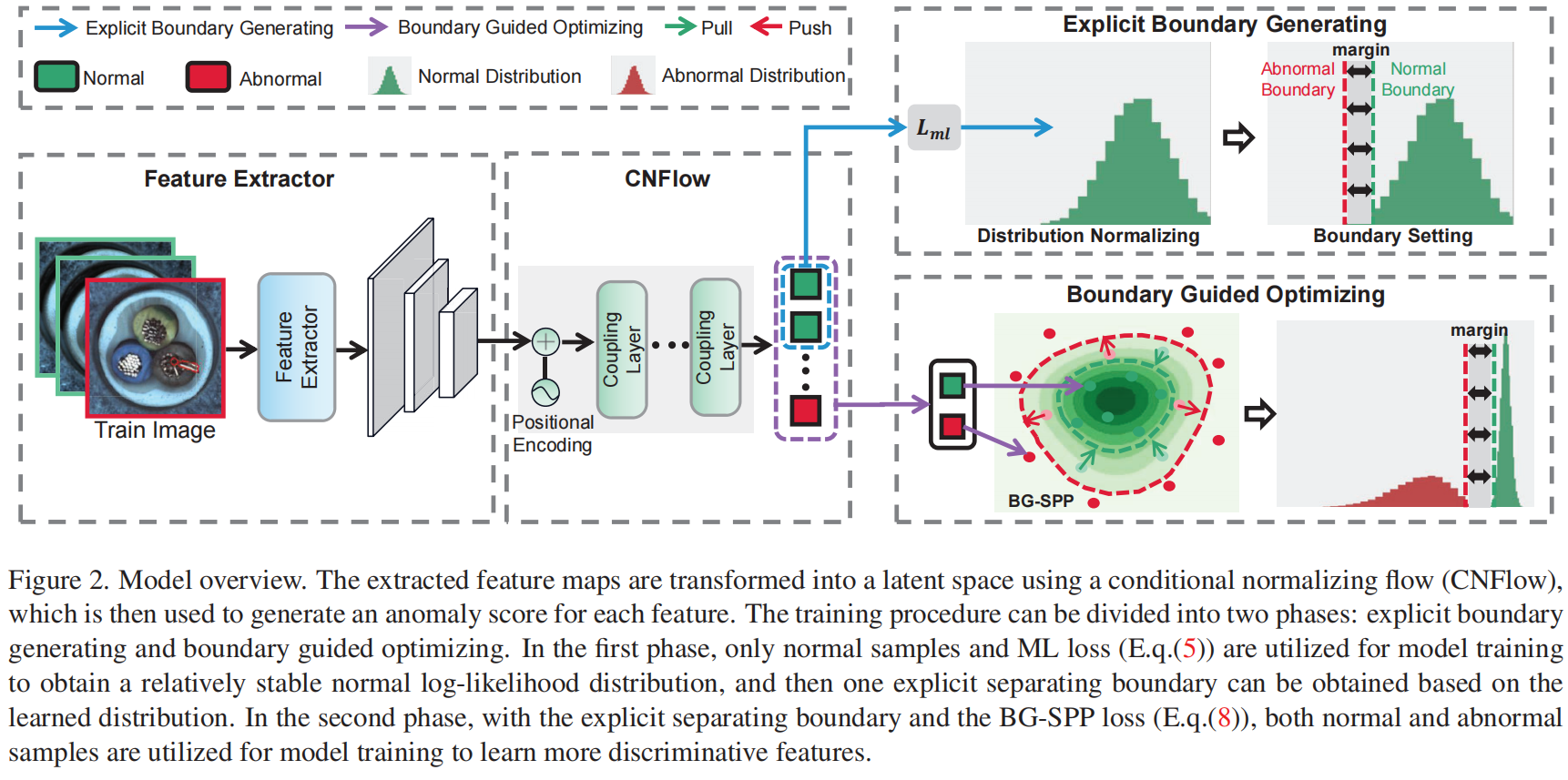
为了更直观地说明我们方法的有效性,我们在图5和图6中可视化了正常和异常特征分布以及对数似然分布。从图5可以看出,监督方法DevNet 受到已知异常的影响,无法区分未知异常和正常数据。但我们的方法可以有效地减轻这个问题,并生成比无监督方法MSFD更具区别性的特征。从图6可以看出,我们的BGAD可以减小模糊的对数似然区域。