代码:https://github.com/Vill-Lab/2022-TIP-HCGA
摘要:由于更多的背景噪声和不完整的前景信息,被遮挡人员重新识别(ReID)是一项具有挑战性的任务。尽管现有的基于人类解析的 ReID 方法可以通过最精细像素级别的语义对齐来解决这个问题,但它们的性能很大程度上受到人类解析模型的影响。大多数监督方法建议除了具有跨域人体部位标注的 ReID 模型之外,还训练一个额外的人体解析模型,但面临昂贵的标注成本和领域差距;无监督方法将基于特征聚类的人体解析过程集成到 ReID 模型中,但缺乏监督信号会带来不太令人满意的分割结果。在本文中,我们认为 ReID 训练数据集中预先存在的信息可以直接用作监督信号来训练人类解析模型,而无需任何额外的注释。通过将弱监督的人类协同解析网络集成到 ReID 网络中,我们提出了一种新颖的框架,该框架利用同一行人的不同图像之间的共享信息,称为人类协同解析引导对齐(HCGA)框架。具体来说,人类协同解析网络受到三个一致性标准的弱监督,即全局语义、局部空间和背景。通过将行人 ReID 网络中的语义信息和深度特征输入引导对齐模块,可以获得前景和人体部分的特征,以进行有效的遮挡行人 ReID。两个遮挡数据集和两个整体数据集的实验结果证明了我们方法的优越性。特别是在 Occlusion-DukeMTMC 上,它实现了 70.2% Rank-1 准确率和 57.5% mAP。
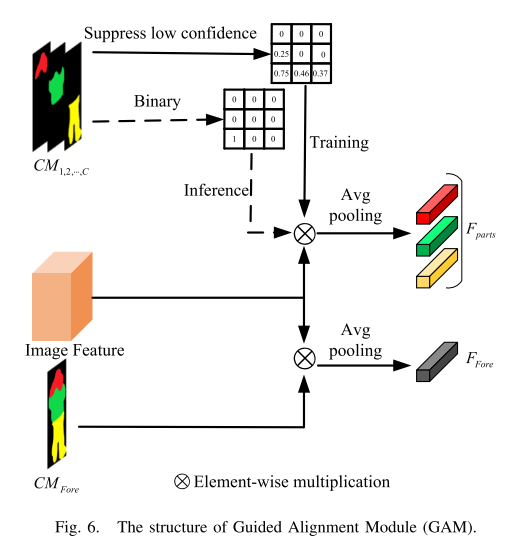
本文的主要贡献总结如下:1)我们提出了一种新颖的人类共同解析引导对齐(HCGA)框架,该框架交替训练人类共同解析网络和ReID网络,其中人类共同解析网络被训练以弱监督的方式获得配对结果而无需任何额外的注释。 2)对于人类协同配对网络,我们设计了三种新颖的损失函数,即局部空间一致性、语义一致性和背景组,以满足人类解析的理想约束。 3)对于ReID网络,我们提出了一种引导对齐模块,通过在训练期间忽略前景中低置信度的像素特征并在测试期间增强高置信度的像素特征来降低解析预测的不确定性。 4)我们进行了大量的实验来证明所提出的方法在两个遮挡数据集——Occlusion-DukeMTMC[16]和Occlusion-REID[17]上实现了优越的性能,并且在两个整体数据集——Market-1501[18]和CUHK03NP上实现了有竞争力的性能[19],[20]。
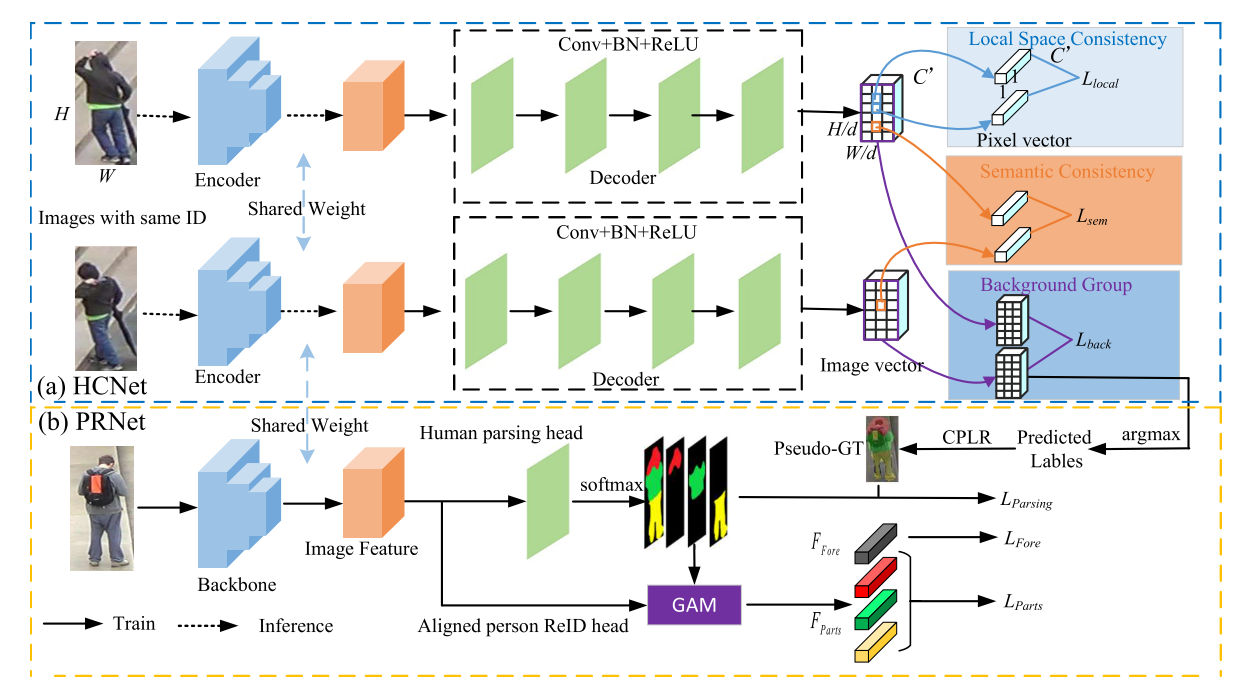
(a)人类协同解析网络(HCNet)。 (b) 人员重识别网络 (PRNet)。
两个子网络共享主干并交替训练,直到优化到最佳状态。具体来说,PRNet对参数进行细化,使不同语义的特征之间的差异更大。 HCNet 基于细化的特征产生更好的分割结果,以指导 PRNet 在像素级别的对齐。
HCNet的Encoder = PRNet的backbone
HCGA 训练阶段的每个 epoch 包含两个步骤:(1)将训练集中具有相同 ID 的一组图像作为批次输入 HCNet。在HCNet的训练阶段,Encoder的参数并没有更新。对于训练集的每个ID,我们单独训练一个解码器,并在训练结束时输出该ID的所有图像的协同解析结果。 (2)将协同解析结果作为PRNet的人类解析头的伪GT。在训练中,PRNet的所有参数均通过反向传播进行更新。
三个损失函数:
局部空间一致性损失 :受LBP算子启发,最大化R × R 窗口内中心像素和相邻像素的预测向量的相似性。

语义一致性损失:
背景组损失:
- Re-Identification Identification Co-Parsing Alignment Occludedre-identification identification co-parsing re-identification re-identification identification information re-identification identification transforming re-identification identity-guided identification camera camera-conditioned re-identification re-identification intra-identity identification re-identification identification perspectives re-identification identification adaptive pairwise occluded