前面利用ResNet18实现了二分类,这里借助分类网络来识别图片和视频中不同肤色的人数。大体流程可以分为以下几步:数据获取、数据处理、模型训练、图片识别以及视频识别,其中大部分内容参考《机器视觉之TensorFlow2入门、原理与应用实践》第4章。
一、数据获取
这里获取黑人和白人模特数据用于训练。
-
图片地址链接
https://www.quanjing.com/tupian/mote_bairen.html
https://www.quanjing.com/tupian/mote_heiren.html -
爬虫代码
参照书本,爬虫脚本定义了一个Crawler类,主要分为以下几块

根据自己需要,可以调整时间间隔以及图片数量。 -
爬虫结果
白人
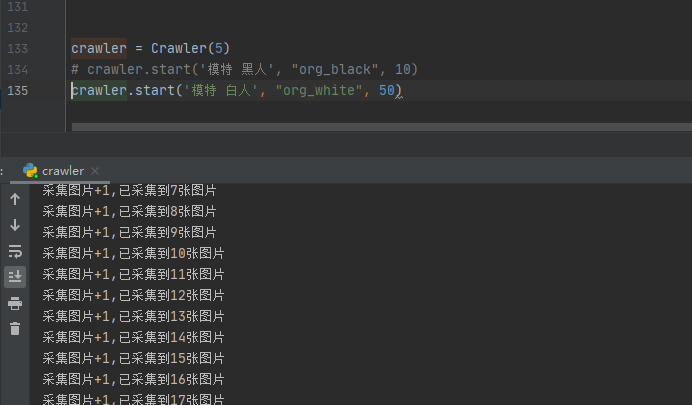

黑人

二、数据处理
前面爬取得到的图片不仅仅包含人脸,还有身体及其他背景等内容,而且图片大小也不一致,所以这里需要对获取的图片进行预处理,主要分为以下两个步骤:
- 获取每张图片上人脸位置
- 依据人脸位置对图片进行裁剪,得到人脸图像
1. 获取人脸位置
为了快速获得图片中人脸位置信息,这里借助face_recognition库直接得到人脸位置。
-
安装
face_recognitionpip install face_recognition -
识别流程
import face_recognition import cv2 img_path = "./test.jpg" img = cv2.imread(img_path) # 获取位置信息 faces = face_recognition.face_locations(img) print("faces location: ", faces) -
结果

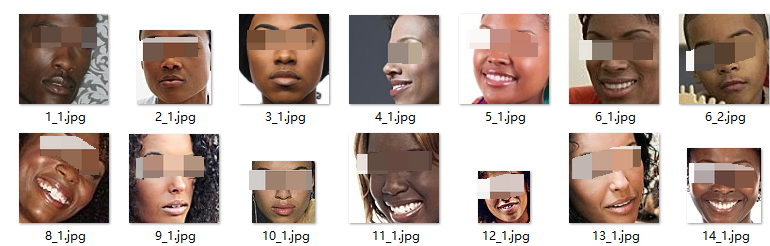
2. 裁剪图片
通过上一步获得了人脸的包围框信息,借助openCV库对其进行裁剪,并保存至相应文件夹。
import os
file_name = os.path.basename(img_path)
save_dir = "./dataset/black"
sampleNum = 1
for (top, right, bottom, left) in faces:
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# save img
cv2.imwrite(os.path.join(save_dir, file_name + str(sampleNum) + ".jpg"), img[top:bottom, left:right])
sampleNum += 1
裁剪后图片

三、模型训练
经过以上步骤,数据集就制作完成了,沿用Resnet18实现二分类的内容制作对应的数据集并进行训练,得到黑人和白人两个类别的分类模型。
训练过程这里就不重复,直接贴出训练过程中visdom可视化结果

四、图片识别
对于给定图片,我们按照先确定人脸位置,然后再对人脸进行分类的思路进行处理。这里确定人脸位置同样采用face_recognition模块,裁剪得到对应的人脸图片,然后输入到人脸二分类模型,进行预测,进而得到不同肤色的人数。接下来按照以下步骤进行展开。
- 检测图片中人脸位置
- 绘制人脸边界框
- 图片左上角显示不同肤色的人数
test_dir = r"./test_img"
img_size = 64
class_names = ["black", "white"]
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = resnet18(pretrained=True) # model
model = nn.Sequential(*list(model.children())[:-1], # [b, 512, 1, 1] -> 接全连接层
nn.Flatten(), # [b, 512, 1, 1] -> [b, 512]
nn.Linear(512, 2)).to(device) # 添加全连接层
model.load_state_dict(torch.load(r"D:\AI\Classify/resnet18-2Class_black_white.pkl"))
model.eval()
with torch.no_grad():
# print(model)
tf = transforms.Compose([
transforms.Resize((img_size, img_size)),
# transforms.CenterCrop(self.resize),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
img_paths = glob.glob(os.path.join(test_dir, "*.jpg"))
for image_path in img_paths:
img = cv2.imread(image_path)
faces = face_recognition.face_locations(img)
print(image_path, faces)
nums = [0, 0]
for (top, right, bottom, left) in faces:
face_img = img[top:bottom, left:right]
face_img = Image.fromarray(face_img)
pre_img = tf(face_img).unsqueeze(0)
pred = model(pre_img.to(device))
cls_id = pred.argmax(dim=1).item()
nums[cls_id] += 1
print("pred: ", pred, "cls: ", cls_id, "name: ", class_names[cls_id])
cv2.rectangle(img, (left, top), (right, bottom), (255 * cls_id, 255 * cls_id, 255 * cls_id), 2)
# 添加类别
cv2.putText(img, str(class_names[cls_id]), (left, top - 5), cv2.FONT_ITALIC, 0.6, (255 * cls_id, 255 * cls_id, 255 * cls_id), 1)
# 添加计数信息
cv2.putText(img, "black: " + str(nums[0]), (10, 30), cv2.FONT_ITALIC, 0.5, (0, 0, 255), 2)
cv2.putText(img, "white: " + str(nums[1]), (10, 50), cv2.FONT_ITALIC, 0.5, (0, 0, 255), 2)
cv2.imshow("img", img)
cv2.waitKey(0)


五、视频识别
视频和图片类似,在图片识别的基础上多了一个获取视频单帧图片和按Q退出程序的步骤。
- 获取视频每一帧图片
- 检测图片中人脸位置
- 绘制人脸边界框
- 图片左上角显示不同肤色的人数
- 随着人脸移动、框也进行位置变动
- 按Q键退出程序
这里借助openCV直接调取电脑摄像头
import cv2
from PIL import Image
import numpy as np
cap = cv2.VideoCapture(0) # 打开摄像头
while(True):
ret, frame = cap.read() # 获取摄像头信息
img = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
faces = face_recognition.face_locations(img) # 检测人脸位置
nums = [0, 0]
for (top, right, bottom, left) in faces:
face_img = img[top:bottom, left:right]
face_img = Image.fromarray(face_img)
face_img = face_img.resize((32, 32), Image.ANTIALIAS)
face_img = np.reshape(face_img, (-1, 32, 32, 3))
pred = model.predict(face_img)
classes = pred[0].tolist().index(max(pred[0]))
nums[classes] += 1
cv2.rectangle(img, (left, top), (right, bottom), (255*classes, 255*classes, 255*classes), 2)
# 添加类别
cv2.putText(img, str(classesnum[classes]), (left, top-5), cv2.FONT_ITALIC, 0.6, (255*classes, 255*classes, 255*classes), 1)
# 添加计数信息
cv2.putText(img, "black: " + str(nums[0]), (10, 30), cv2.FONT_ITALIC, 0.5, (255, 255, 255), 2)
cv2.putText(img, "white: " + str(nums[1]), (10, 50), cv2.FONT_ITALIC, 0.5, (255, 255, 255), 2)
cv2.imshow("img", img)
if cv2.waitKey(1) &oxFF == ord("q"):
break
cap.release()
cv2.destroyAllWindows()
参考资料
1、《机器视觉之TensorFlow2入门、原理与应用实践》第4章