前言 如何刻画网络的优化性质呢?在优化相关的论文中,通常通过分析 Hessian 矩阵及其特征值,或者将损失函数进行一维或二维的可视化来分析网络的优化性质。我们希望这些指标能够帮助我们更好的理解网络损失的 landscape,优化器优化轨迹的性质等等。我们希望将这些指标刻画的性质与优化器的设计关联起来。我们也希望找到合适的指标来反应随着网络参数、数据量、批量大小等参数的变化,网络的优化性质如何变化「R1」。
本文转载自PaperWeekly
作者:郑奘巍
单位:新加坡国立大学
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
We should use the special structure properties of f(for example f is a given by a neural network)to optimize it faster, instead of purely relying on optimization algorithms.
― Yuanzhi Li

Hessian 阵
大量对神经网络损失空间的研究都是基于 Hessian 阵的。Hessian 阵是损失函数的二阶导数。由于 Hessian 阵是实对称矩阵,可以应用特征分解。它的特征值和特征向量可以帮助我们理解损失函数的 landscape。这里我们不太严谨的介绍一些优化文章中常见的概念。
1.1 常见概念
Curvature 曲率:数学定义为一点处密切圆弧的半径的倒数,它刻画了函数与直线的差距。在梯度为 0 的点时,Hessian 阵行列式为曲率。
Eigenvalue 特征值:Hessian 阵的特征值越大,对应的特征向量(Eigenvector)方向就越陡(凸性越强)。最大特征值对应的方向为最大曲率的方向。如果考虑以特征向量对应方向的单位向量作为基张成的空间,该空间称为特征空间 Eigenspace,对应的单位向量为 Eigenbasis。
Conditioning number 条件数:Hessian 阵的最大特征值与最小特征值的比值。条件数越大,系统越不稳定。
Axis-aligned 坐标轴对齐:Hessian 阵的特征向量是否与坐标轴平行。
Smoothness 光滑(一般指 Lipschitz 梯度条件):。如果是二阶可导凸函数,则有 。即 Smoothness 限制了 Hessian 阵特征值的大小(和变化幅度的上限),不能大于 。
Strong Convexity 强凸性:虽然神经网络一般都是非凸优化,但这里我们引入凸性用以和光滑对应,以便于理解。强凸性的定义为 。即 Strong Convexity 限制了 Hessian 阵特征值的大小(和变化幅度的下限),不能小于 m。
Sharpness / Flatness 平坦程度:对 Hessian 特征谱分布情况的描述。Sharp 指 Hessian 阵特征值含有大量大值,Flat 指 Hessian 阵特征值含有大量小值(绝大部分接近 0)。另一种定义方法是直接将 Sharpness 定义为最大的特征值 。Hessian 阵退化(degenerate)/ 奇异(singular)/ 低秩 / 线性相关是 Flat 的一种表现。通常收敛点平坦有利于泛化性能(Hessian 阵是实对称矩阵,特征值和奇异值相等)。
常见地形(terrain, landscape):
驻点(stationary point),临界点(critical point):
- 鞍点:H 非正定的驻点
- plateaus:平坦地,拥有小曲率的平面
- basins:盆地,局部最优点的集合
- wells:井,鞍点的集合
局部的泰勒展开到二阶:
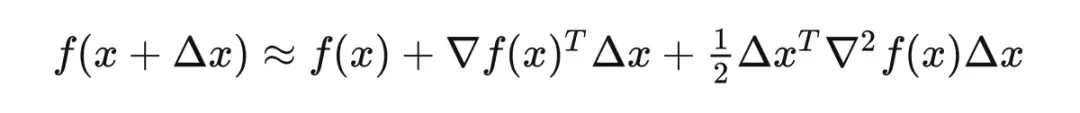
1.2 费雪信息
Fisher information matrix 费雪信息:
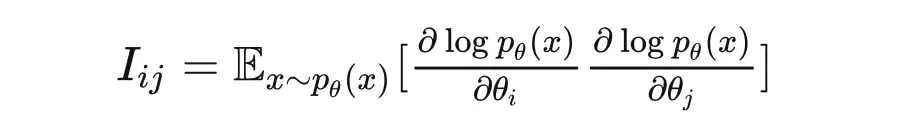
- 费雪信息总是对称半正定阵。由于 ,所以 Fisher information (二阶矩)衡量了不同样本对应导数的方差()。
- ,所以 Fisher information 同时是使用 log-likelihood 衡量的函数的 Hessian 阵的期望。证明可参考此处:https://mark.reid.name/blog/fisher-information-and-log-likelihood.html
- 分类模型建模的分布是 。在训练初期,网络的输出 与真实分布的差距很大。如果根据网络输出的标签采样,可以得到对应分布的 Hessian 阵(半正定)但并不是我们关心的真实分布的 Hessian 阵。
- 当模型分布与真实分布的差距很小时,Fisher information 可以近似为 Hessian 阵的期望。
1.3 Gauss-Newton 阵
Gauss-Newton decomposition:记神经网络输出为 ,其中 为损失函数,则网络的黑塞阵有如下分解。以一维 f 为例,高维可参考此处:
https://andrew.gibiansky.com/blog/machine-learning/gauss-newton-matrix/
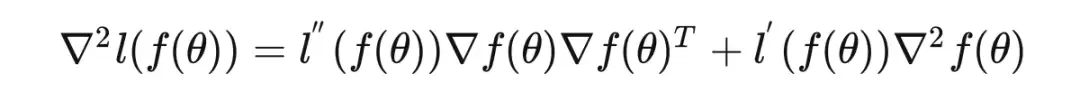
通过链式法则即可证明。这里的第一项被称作 Gauss-Newton 阵,它衡量了由于网络特征 的变动贡献的 Hessian 阵值。第二项则是由于输入值的变动贡献的 Hessian 阵值。由于第二项通常很小,所以我们可以近似认为黑塞阵由 Gauss-Newton 阵决定。通过变形,我们可以得到 Gauss-Newton 阵的另一种形式,衡量了样本的带权二阶矩。可见 Gauss-Newton 阵与 Fisher information 有着密切的联系。
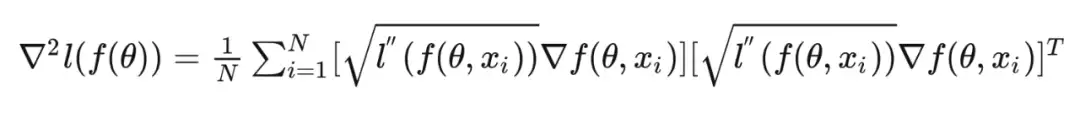

临界点的数量与性质
为了更直观的理解,不会介绍太多理论推导。讨论网络优化性质的文章往往观点鲜明,不少文章得出的结论甚至是相互矛盾。从今天的视角往前看,我们主要介绍目前被广泛接受的观点。但也要注意,部分结论是在 CNN,MLP,LSTM 上用监督学习进行,对应的是 over-paramterized 网络(参数量远大于数据量)。目前的 LLM 则一定程度是 under-parameterized 网络。
1. 局部最优点的数量随着网络参数的增加而指数级增加,但不同局部最优点的训练损失相差不大
[AHW96] 用单神经元网络说明了局部最优点的数量随着网络参数的增加而指数级增加。LeCun 引领的一系列工作 [CHM+14,CLA15,SGA15,K16] 使用 spin-glass 物理模型阐释了简化的神经网络中差局部最优解随着模型参数增大指数级减小,以及局部最优解附近相当平坦。[DY16] 则证明了多层神经网络中相似的结论。
[SEG+18] 中提到,在全连接层中交换任意两个神经元可以得到等价的神经网络。这个性质让随机初始化的网络可能收敛到非常不同的局部最优值。[DVS18] 则用过实验发现,不同的局部最小值之间可以通过平坦的路径相连。[KWL+20] 同样支持了这点:任意两个局部极小值之间都可以通过一条不会太”扭曲“的路径相连,这条路径上的损失最多比局部最优处的损失高一点。
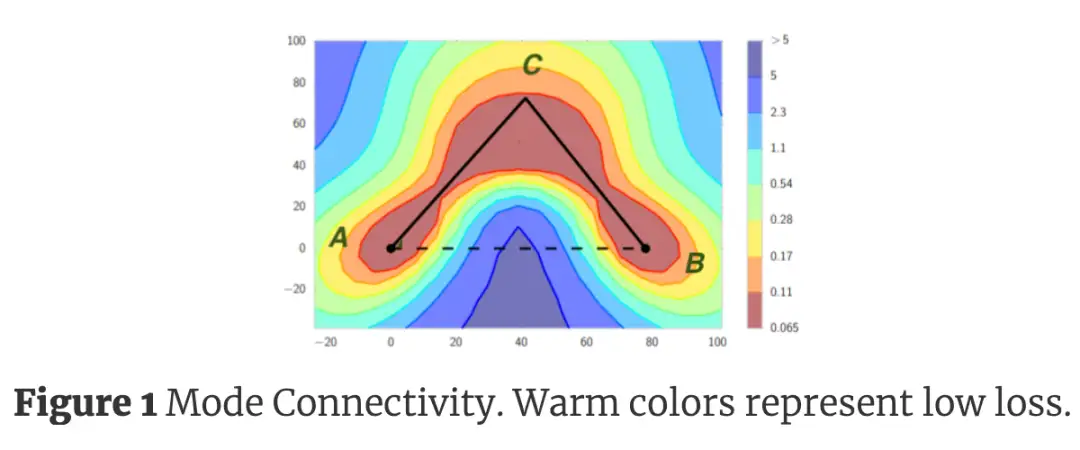
2. 鞍点的数量比上局部最优点的数量随着网络参数的增加而指数级增加
[DPG+14] 理论分析了鞍点数量和局部最优点数量的比例随着网络参数的增加而指数级增加,同时鞍点通常被 plateaus 所包围。[LSJ+16] 则通过理论分析补充,训练时不会陷入鞍点,但是会减慢速度。[CHM+14] 同意该看法,并认为训练神经网络的过程可以看作避开鞍点,并通过选择鞍点的一端从而打破“对称性”的过程。在鞍点处优化器的选择会影响到最终收敛点的性质。
3. Hessian 的低秩性质
[SBL17,SEG+18] 通过计算 CNN 网络训练时的特征谱,发现 Hessian 阵特征值谱分布特点:
- 在训练初期,Hessian 特征值以 0 为中心对称分布。随着训练进行不断向 0 集中,H 退化严重。训练末期极少量小于 0。
- 接近收敛时 Hessian 特征谱分为两部分,大量接近 0,离群点远离大部分特征值,离群点的数量接近于训练数据中的类别数量(或聚类数量)。即 Hessian 阵此时是低秩的。
- 数据不变的情况下,增大参数仅仅使 Hessian 阵接近 0 的部分更宽;参数不变的情况下,数据量的变化会改变 Hessian 阵特征谱的离群点。
- 参数量越大,批量大小越小,训练结束时 Hessian 阵特征值的负值越多(但总体比例都很小。[BKX19] 补充,在训练早期 Hessian 阵就会变得基本没有负值。
[DVS18,BKX19] 同样发现了离群点数量(近似 Hessian 阵的秩)与分类任务中的类别数量相关。最近的一篇工作 [SHS23] 则说明,CNN 中 Hessian 阵的秩随着参数增加而增大。[SKV20] 分析了每层的 Hessian 特征值谱,发现与整个网络的 Hessian 特征值谱相似。
[GRD18] 则进一步描绘了整个训练过程中的低秩现象:Hessian 最大的几个特征值对应的特征向量张成的子空间尽管会变化,但变化程度不大。训练的梯度会很快的进入到这个子空间中,但在这个子空间中并没有什么规律。故整个神经网络的训练似乎是发生在一个低维的子空间上的。
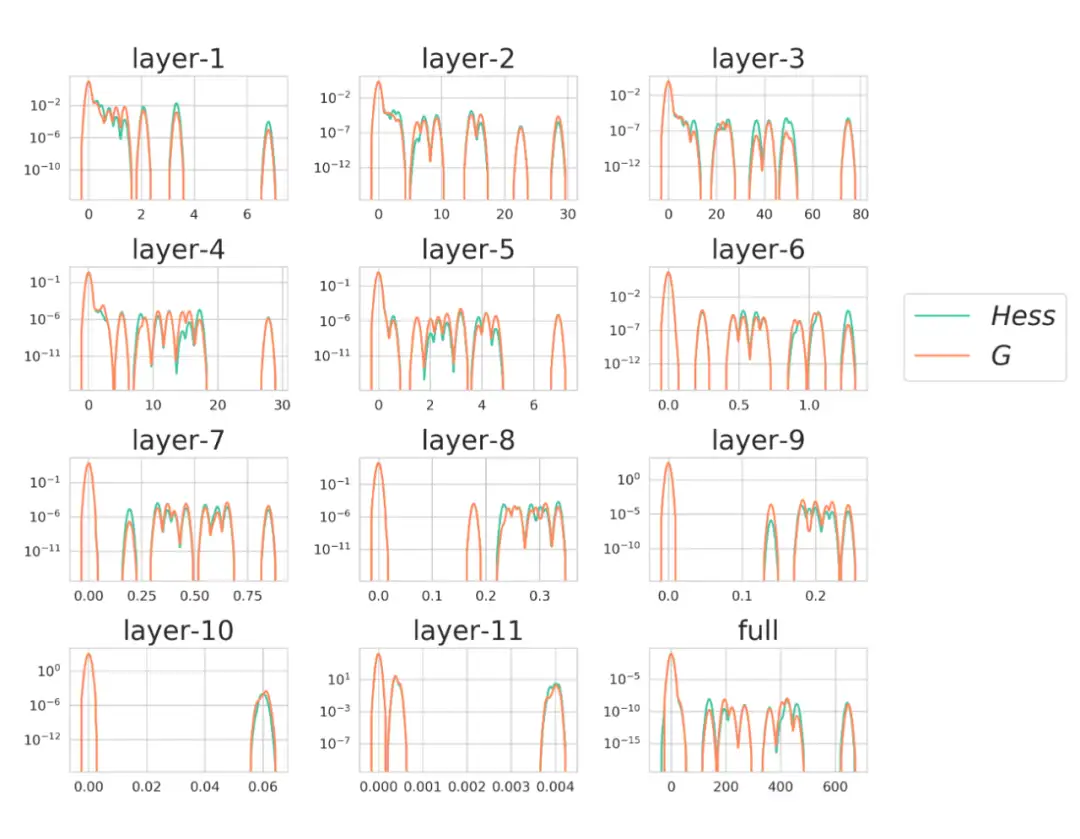
4. Gauss-Newton 阵可以近似 Hessian 阵
[SEG+18,SKV20] 都指出了这一点。实验如图所示。Sophia 等二阶优化器正是利用了这点进行对角黑塞阵的计算。[LGZ+19,P19] 则验证了梯度的二阶矩的大特征值与 Hessian 阵的大特征值近似。
5. 平坦的收敛点具有更好的泛化性,大的批量容易收敛到 sharp 的收敛点
[KMN+17] 指出 Flat minima 有利于泛化,大批量训练容易收敛到 sharp minima,小批量训练容易收敛到 flat minima。[SEG+18] 同意这一点,但反对 [KMN+17] 中认为 flat minima 和 sharp minima 被 well 分割开。通过实验证明能够从 sharp minima 平坦的“走”到 flat minima。[YGL+18] 分析了不同批量大小收敛点的 Hessian 特征谱,发现了相同的结论。
一般认为平坦的损失空间,既有利于优化算法的梯度下降,得到的收敛点性质也会更好。故很多文章从该角度解释网络设计的成功原因。譬如残差链接,BN,更宽的网络(over-paramterized)都有助于让损失空间更平滑。

优化路径性质
这里先介绍两篇近期的工作,之后有机会再补充。
[LBZ+21] 沿着前人的工作,探讨了初始权重与训练完成后的权重,两者插值得到的一系列权重的性质。可以看到不同初始化的网络权重往往收敛到同一个盆地。虽然与训练路径不同,插值路径也是单调递减,没有凸起的现象。
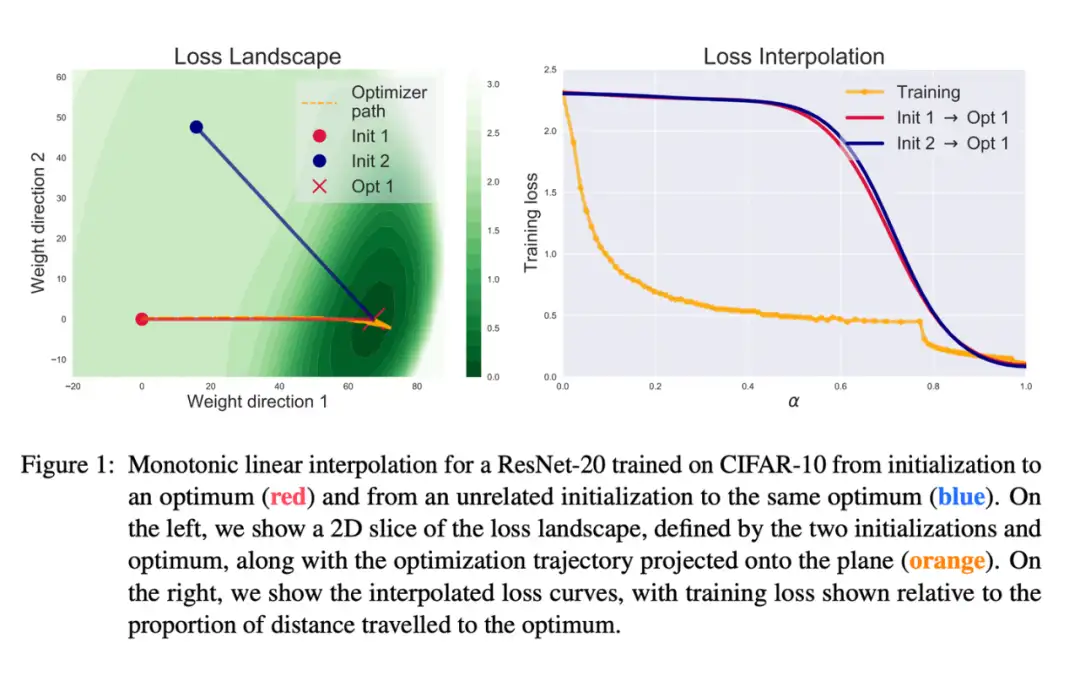
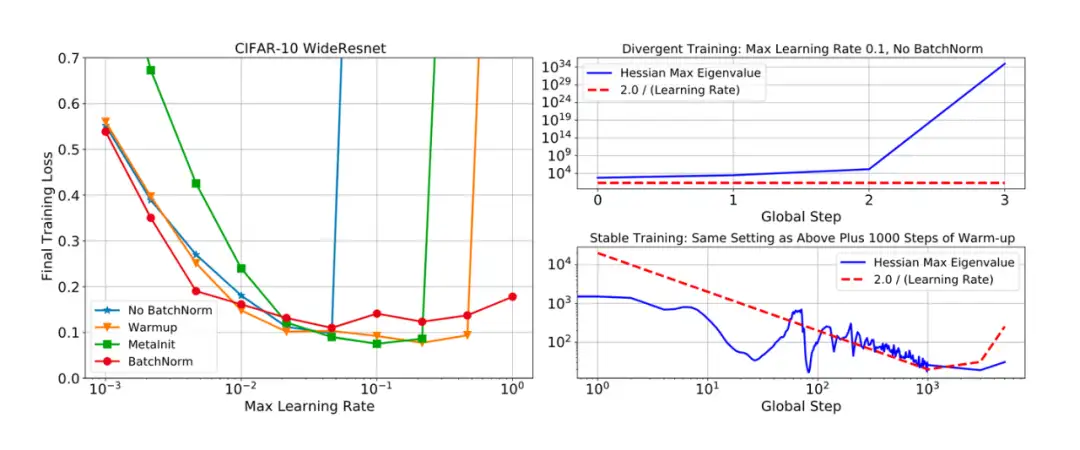
[PL23] 工作则是将优化器每步进行分解。根据局部泰勒展开,作者定义 gradient correlation 和 directional sharpness 两项:
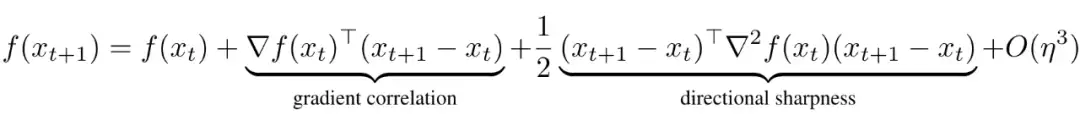
作者发现,不同的优化器的 direction sharpness 的表现很不相同。Sharpness 刻画的是一个点局部的平坦程度,而 directional sharpness 则刻画了优化方向上的平坦程度。在语言模型上,作者发现 SGD 优化器的 direction sharpness 显著高于 Adam 优化器。作者认为这是 Adam 优化器收敛速度快的原因。作者还通过梯度的值裁剪进一步减小 Sharpness 程度,从而加速收敛。
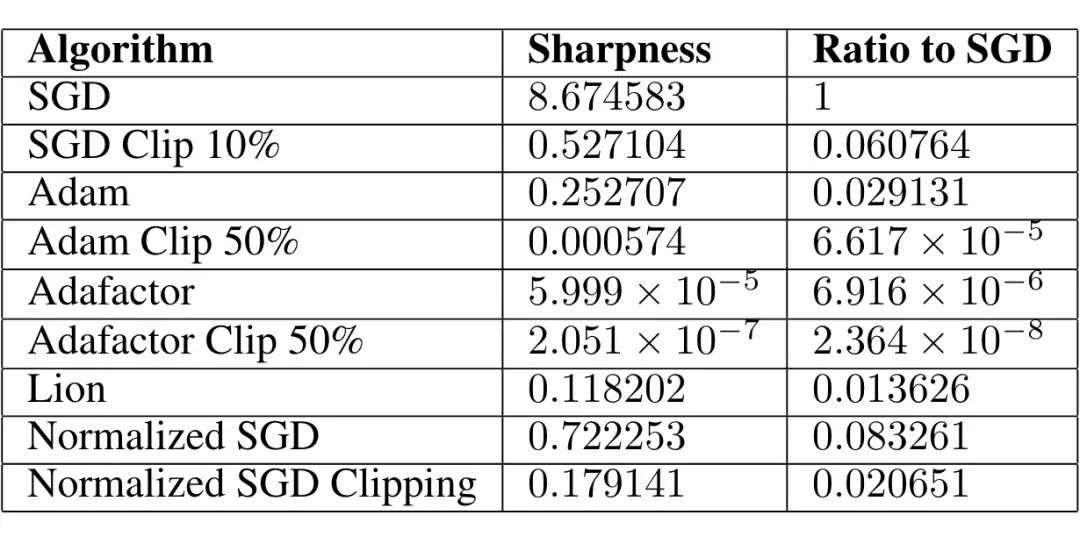
我们已经知道收敛点是需要越平坦泛化性越好的。但从这两篇文章中可以看到,我们希望优化路径始终能够在平坦的区域探索。以往的文章会认为这些区域可能会导致优化陷入鞍点,但目前看来,优化空间中存在大量这样平坦的空间,优化器应该在这些较为平坦的空间中“大踏步”的进行探索。

Transformer 优化性质
前面的分析都是比较泛化的,为了更好的设计针对 Transformer 的优化器,我们还需要分析 Transformer 的特殊性质。比如文章 [LLG+20] 就指出了 Transformer 训练时的一些困难。同样的,Adam 在 Transformer 上表现显著好于 SGD,也暗示了 Transformer 的优化性质与 CNN 等网络不同。
Transformer 的分析文章很多都是对模型设计的分析,如果有机会,我会单独写一篇文章进行介绍。这里只介绍一篇最近的工作 [LYB+23],以补完本节的完整性。
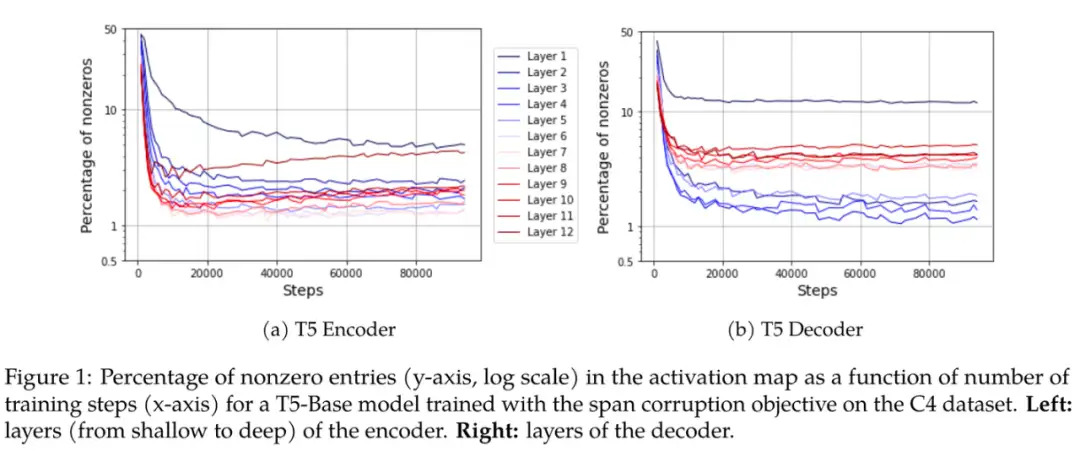
该工作用大量实验揭示了非常直接但有趣的一个现象:Transformer 架构的激活层非常的稀疏。在 T5-Base 中,只有 3% 的神经元被激活了(ReLU 输出值非 0)。并且增大模型会使其更加稀疏,以及和数据似乎无关。无论使用视觉还是语言,甚至是随机数据,以及不重复的数据,都有该现象出现。作者简单的讨论了这种现象可能和优化动力学相关。笔者认为这个现象可能会给 Transformer 的优化器设计一些启示。
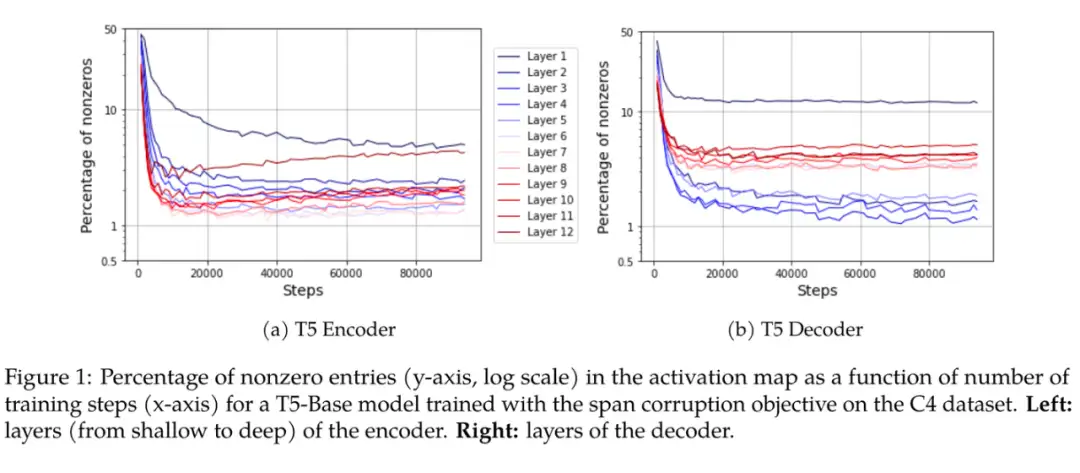
▲ [LYB+23] 激活值的稀疏性现象
参考文献
[CHM+14] The Loss Surfaces of Multilayer Networks
[CLA15] Open Problem: The landscape of the loss surfaces of multilayer networks
[AHW96] Exponentially many local minima for single neurons
[SGA15] Explorations on High Dimensional Landscapes
[DY16] No bad local minima: Data independent training error guarantees for multilayer neural networks
[K16] Deep Learning without Poor Local Minima
[SEG+18] Empirical Analysis of the Hessian of Over-Parametrized Neural Networks
[DVS18] Essentially No Barriers in Neural Network Energy Landscape
[DPG+14] Identifying and attacking the saddle point problem in high-dimensional non-convex optimization
[LSJ+16] Gradient Descent Converges to Minimizers
[SBL17] Eigenvalues of the Hessian in Deep Learning: Singularity and Beyond
[KWL20] Explaining Landscape Connectivity of Low-cost Solutions for Multilayer Nets
[GRD18] Gradient Descent Happens in a Tiny Subspace
[SKV20] A Deeper Look at the Hessian Eigenspectrum of Deep Neural Networks and its Applications to Regularization
[LGZ+19] Hessian based analysis of SGD for Deep Nets: Dynamics and Generalization
[P19] Measurements of Three-Level Hierarchical Structure in the Outliers in the Spectrum of Deepnet Hessians
[SHS23] The Hessian perspective into the Nature of Convolutional Neural Networks
[KMN+17] On large-batch training for deep learning generalization gap and sharp minima
[YGL+18] Hessian-based Analysis of Large Batch Training and Robustness to Adversaries[GGG+21] A Loss Curvature Perspective on Training Instability in Deep Learning
[PL23] Toward Understanding Why Adam Converges Faster Than SGD for Transformers
[LLG+20] Understanding the Difficulty of Training Transformers
[LYB+23] The Lazy Neuron Phenomenon: On Emergence of Activation Sparsity in Transformers
[LBZ+21] Analyzing Monotonic Linear Interpolation in Neural Network Loss Landscapes
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
LSKA注意力 | 重新思考和设计大卷积核注意力,性能优于ConvNeXt、SWin、RepLKNet以及VAN
CVPR 2023 | TinyMIM:微软亚洲研究院用知识蒸馏改进小型ViT
ICCV2023|涨点神器!目标检测蒸馏学习新方法,浙大、海康威视等提出
ICCV 2023 Oral | 突破性图像融合与分割研究:全时多模态基准与多交互特征学习
HDRUNet | 深圳先进院董超团队提出带降噪与反量化功能的单帧HDR重建算法
南科大提出ORCTrack | 解决DeepSORT等跟踪方法的遮挡问题,即插即用真的很香
1800亿参数,世界顶级开源大模型Falcon官宣!碾压LLaMA 2,性能直逼GPT-4
SAM-Med2D:打破自然图像与医学图像的领域鸿沟,医疗版 SAM 开源了!
GhostSR|针对图像超分的特征冗余,华为诺亚&北大联合提出GhostSR
Meta推出像素级动作追踪模型,简易版在线可玩 | GitHub 1.4K星
CSUNet | 完美缝合Transformer和CNN,性能达到UNet家族的巅峰!