今天我们一起学习如何对模型微调和引导。
微调,用原模型,跑新数据,得到新输出。
引导,引导生成过程,改变输出结果。
作者之前用过sd模型,不同的采样方法在不同的采样步数下有不同的效果。首先采样步数并非越高越好或越低越好,有一个最佳使用区间,其次,不同采样方法有自己不同的最佳采样步数区间。
一般而言30左右大部分不会出错。
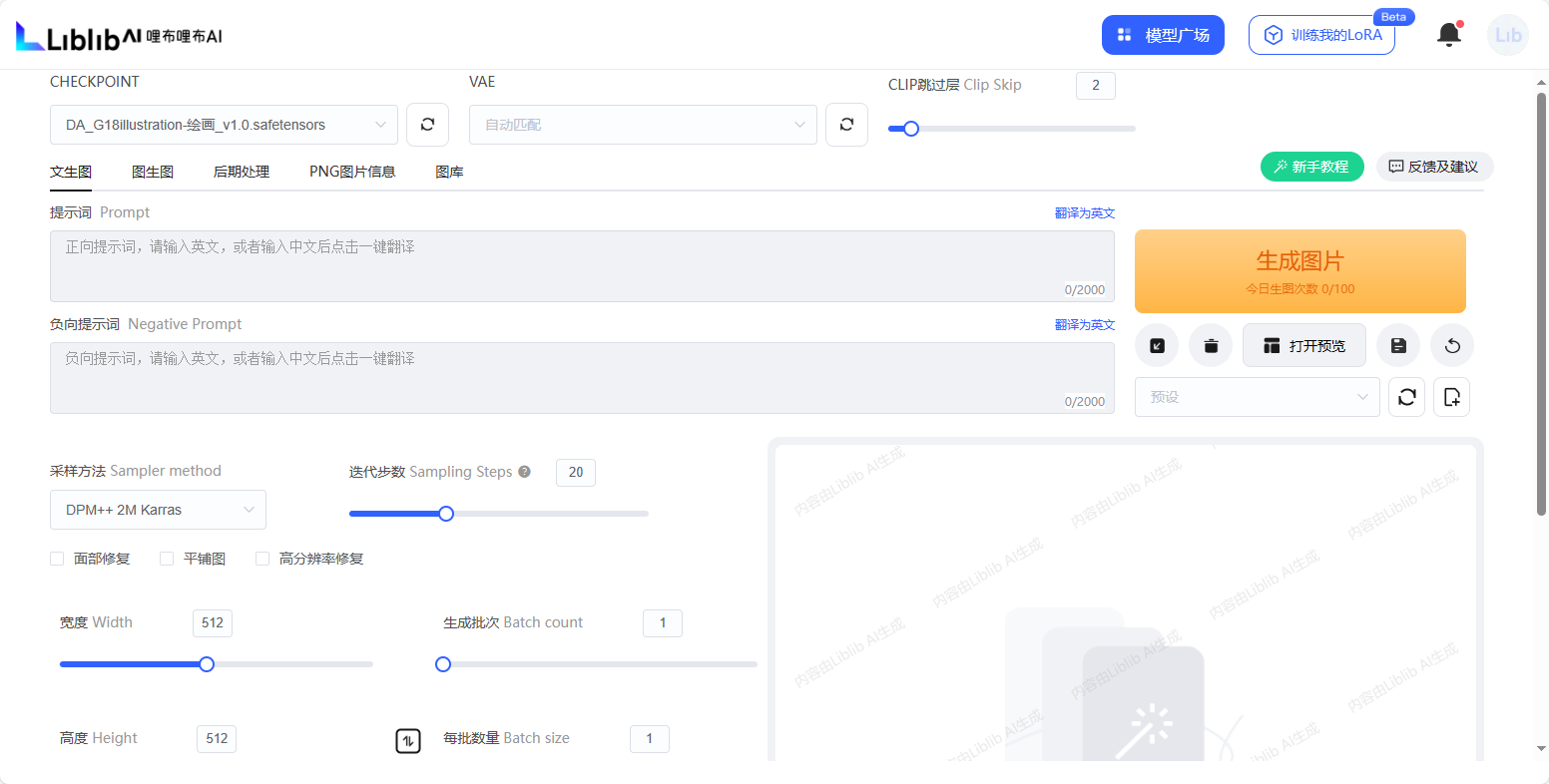
liblibai 搜索即可找到
这是在sd模型里随便截的图,其包含的采样方法。本次实验所用的就是其中的DDIM模型。
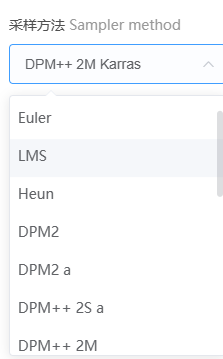
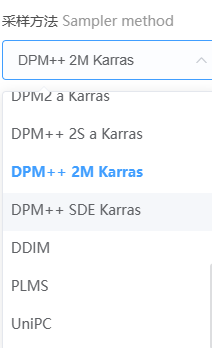
本次数据结果,有点像,上述的采样步数的设置特点:

梯度积累
对于一批数据,假设有32个图像,可以将其分成4批8个图像,分别进行训练,但前3次不改变权重,第4次改变权重,同样可以实现迭代训练。这样可以减轻硬件负担,拿时间换可行性。
如何实现:
设置一个切分数,比如32个图分成4批,然后在权重更新之前加一句判断,仅当迭代次数是切分数的整数倍时更新权重。
经过一番努力(不停地点击运行代码),获得了一堆 奇怪的东西。
