我这里是使用的requests模块和re(正则)模块
可以模仿浏览器正常访问网页返回网页源码的方式,通过正则获取到小说的名字,以及每个章节名称和对应的网页链接,并将小说正文截取出来,写入到文本中,具体代码实现如下:
# 导入requests模块
import requests
# 导入re(正则)模块
import re
# 下载一个网页
url = 'https://ww.sangwu8.com/book/13/13962/'
# 模拟浏览器发送http请求
response = requests.get(url)
response.encoding = "gbk"
# 目标小说主页的网页源码
HTML = response.text
#print(HTML)
#print(re.findall(r'<h2>(.*?)</h2>', HTML))
# # 获取小说的名字
title = re.findall(r'<h2>(.*?)</h2>', HTML)[0]
print(title)
# # 新建一个文件,保存小说内容
fb = open('%s.txt' % title, 'w', encoding='utf-8')
# # 获取每一章的信息(章节,url)
# ul = re.findall(r'<dl>.*?</dl>', HTML, re.S)[0]
dl = re.findall(r'<dl>.*?</dl>', HTML, re.S)[0]
# print(dl)
# # [0]指列表
# # 提取 章节url、章节信息
chapter_info_list = re.findall(r'<a href="(.*?)">(.*?)<', dl)
# print(chapter_info_list)
# # 循环每一个章节,分别去下载
for chapter_info in chapter_info_list:
chapter_url, chapter_title = chapter_info
chapter_url = "https://ww.sangwu8.com/book/13/13962/%s" %chapter_url
print(chapter_url, chapter_title)
# 下载章节内容
chapter_response = requests.get(chapter_url)
chapter_response.encoding = 'gbk'
chapter_HTML = chapter_response.text.replace('\u3000','').replace(' ','')\
.replace('<','').replace('br/>','').replace('&','').replace('lt;','').replace('gt;','').replace('<br />','').replace("\r", "").replace("\n", "")
# print(chapter_HTML)
# text = re.findall(r'<div class="centent">(.*?)</div>', chapter_HTML, re.S)
# print(text)
# 提取章节内容
chapter_content = re.compile('.*?<div class="centent">(.*?)</div>', re.S)
print(chapter_content)
test = re.findall(chapter_content, chapter_HTML)
#print(test)
#break 单章测试时退出使用
# 数据持久化
fb.write('\n')
fb.write(chapter_title)
fb.write('\n')
fb.write(test[0])
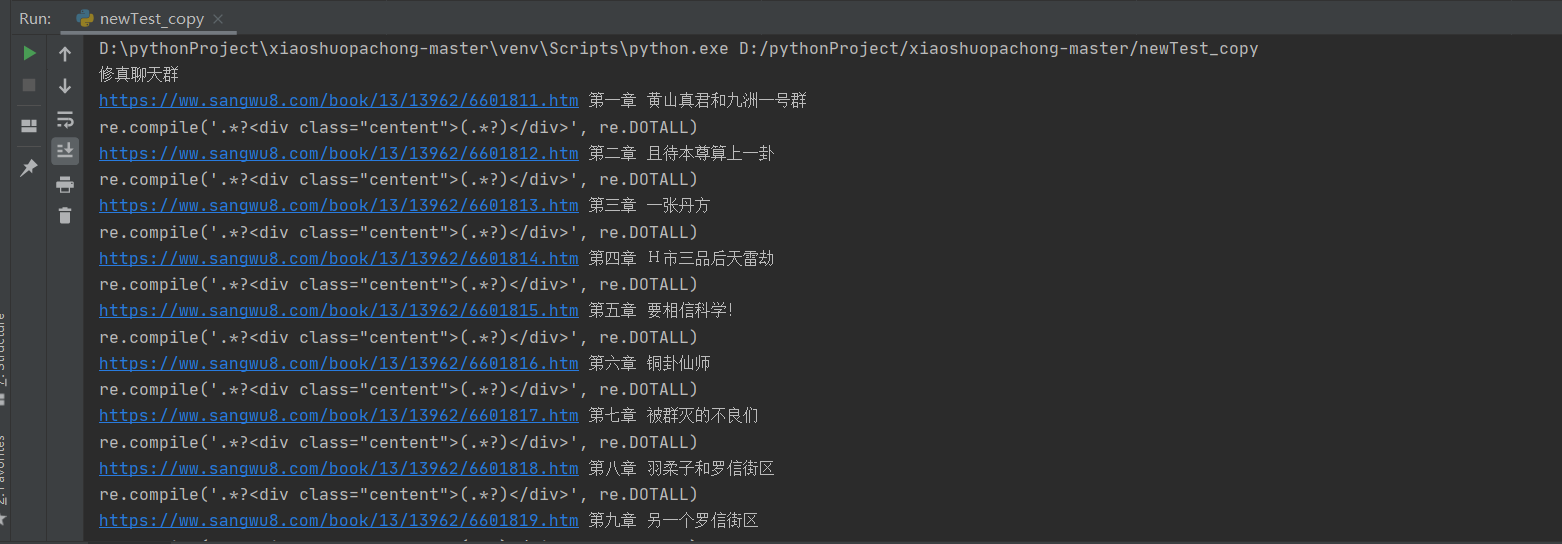
执行截图如下:
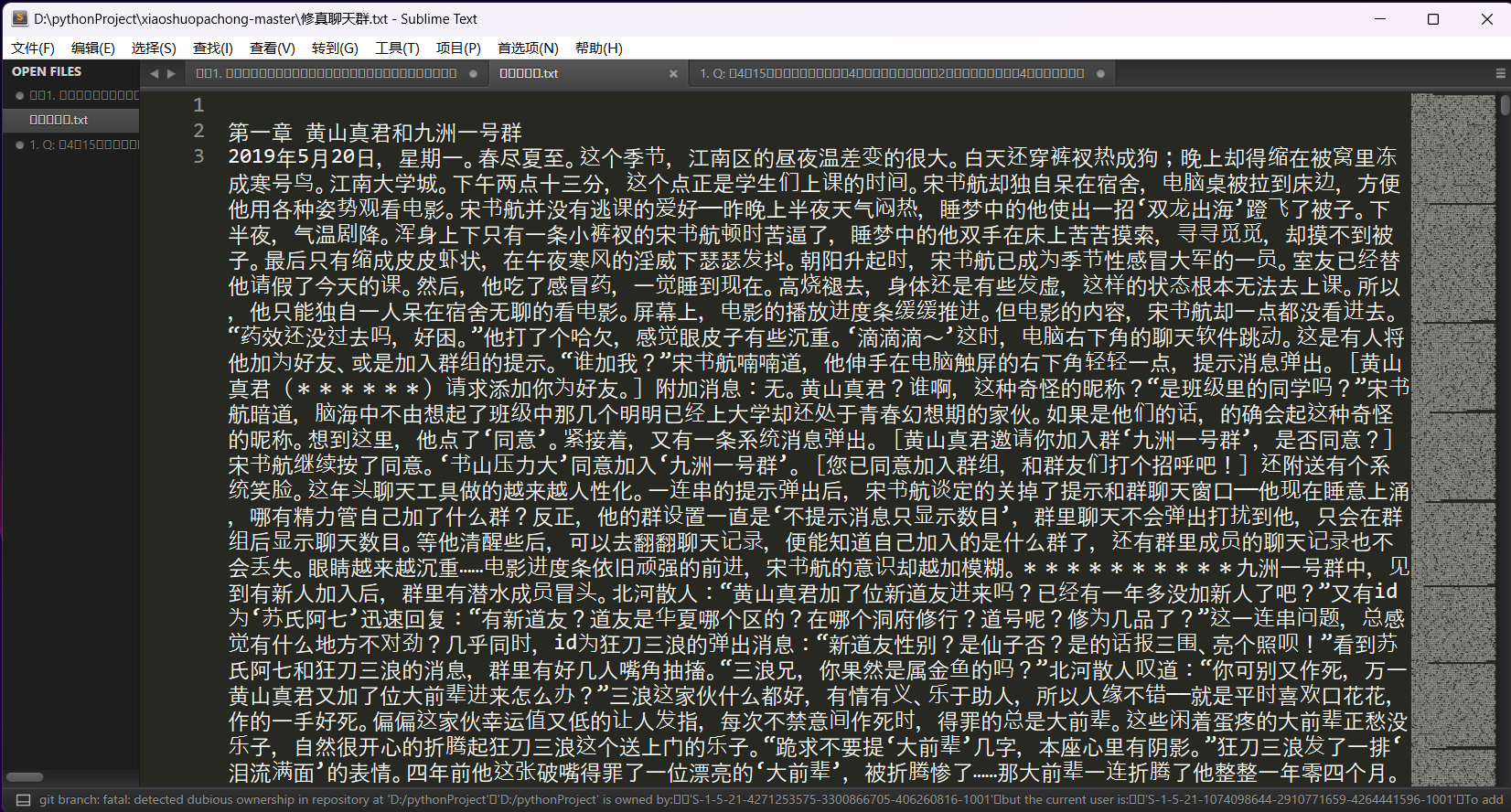
可以按照章节写入文本中
最终输出文本结果: