一、利用xpath来抓取图片
- url地址是:唯美壁纸 - 唯美手机壁纸 - 唯美手机动态壁纸 - 元气壁纸 (cheetahfun.com)
- 数据解析方式xpath
二、分析
- 在浏览器中打开网页链接后,F12找到元素,可以看到图片的的内容可以在源代码中找到,
- 分析发现,每一个图片分别对应着一个li的标签【在<li class = "float-left">下层】
-
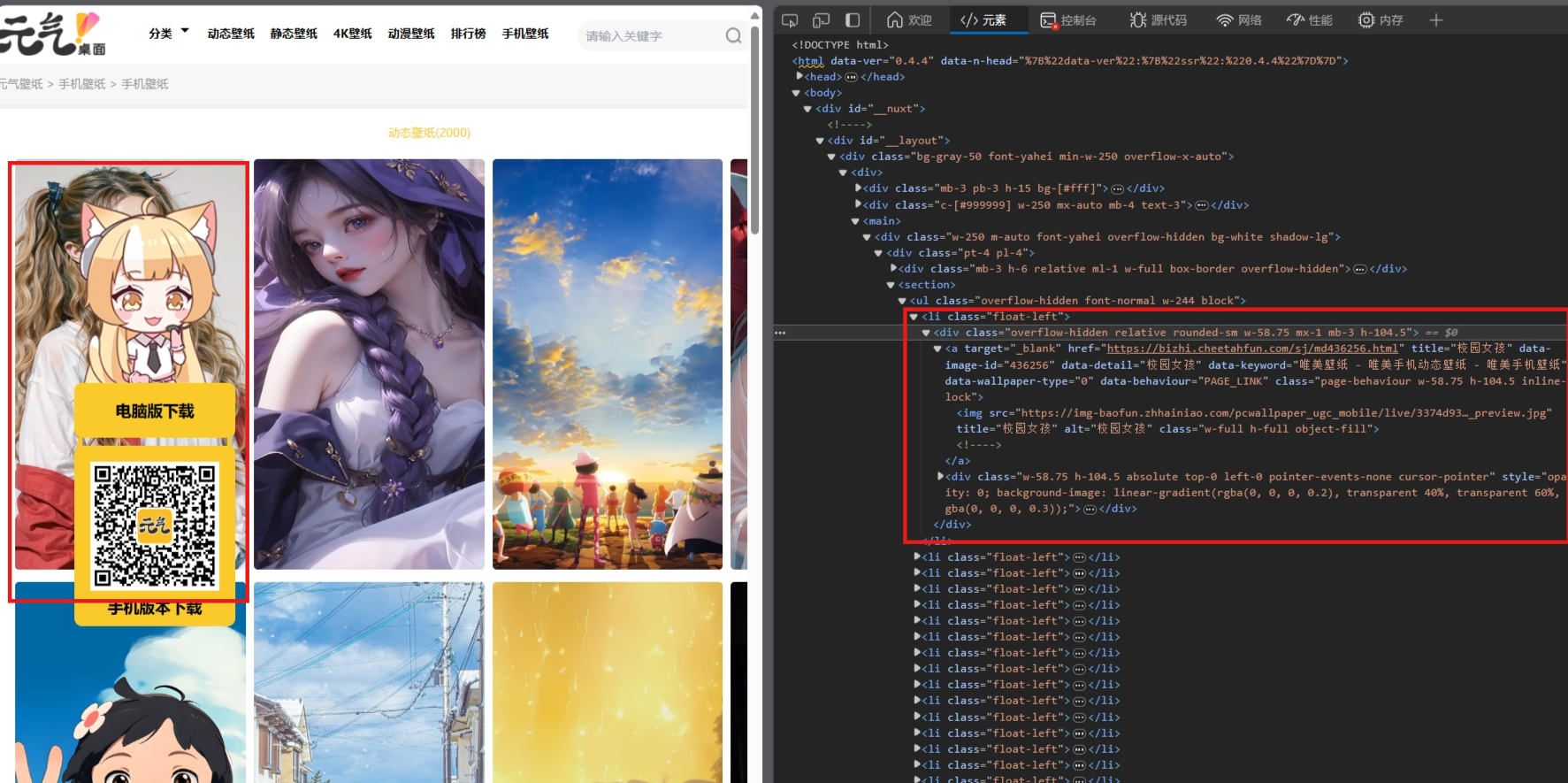
xpath解析:
#用xpath模块来获取一个网页的信息 1、导包 import requests from lxml import etree 2、发送请求 声明url,UA 根据请求方式进行请求,然后获取response内容 3、把获取的源码数据给etree对象进行处理 html = etree.HTML(resp.text) 4、xpaht解析 html.xpath(。。。)

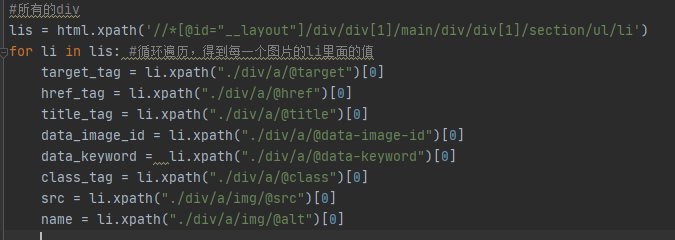
上面的是获取每一个图片中li里的值,这个和bs4有一点不太一样
三、完整代码
import requests from lxml import etree import json import time #1、声明一个url地址 url = "https://bizhi.cheetahfun.com/sj/dtag_11/" #UA伪装 headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0" } resp = requests.get(url=url,headers = headers) #把resp.html文本放到etree中 html = etree.HTML(resp.text) #<Element html at 0x20fe67b5a00> #所有的div lis = html.xpath('//*[@id="__layout"]/div/div[1]/main/div/div[1]/section/ul/li') for li in lis: #循环遍历,得到每一个图片的li里面的值 target_tag = li.xpath("./div/a/@target")[0] href_tag = li.xpath("./div/a/@href")[0] title_tag = li.xpath("./div/a/@title")[0] data_image_id = li.xpath("./div/a/@data-image-id")[0] data_keyword = li.xpath("./div/a/@data-keyword")[0] class_tag = li.xpath("./div/a/@class")[0] src = li.xpath("./div/a/img/@src")[0] name = li.xpath("./div/a/img/@alt")[0] #保存本地 with open("E:/python123/元气桌面/" + title_tag + ".jpg",mode="wb")as f: f.write(requests.get(src).content) print(title_tag +"下载完成!!") time.sleep(0.5)