数据采集与融合实践第三次作业
**代码连接: **
作业一
作业内容
-
要求:指定一个网站爬取这个网站的所有图片,如中国气象网,使用scrapy框架分别实现单线程和多线程爬取
-
输出信息:将下载的url信息在控制台输出,并将下载的图片存储在images子文件当中,并给出截图
思路解析
- 要实现全站图片的爬取,那么首先就获取网站里面的所有链接页面,然后再去检索每个页面的图片链接,将图片下载下来。需要注意的是,有的链接是连接到外部网站的,不属于本网站范畴,有可能会出错,因此可以加一个异常捕获的模块。
具体实现
- scrapy startproject wheather 创建项目
- cd wheather/wheather/spiders 进入spider
- scrapy genspider weather http://www.weather.com.cn 创建爬虫程序
- item编写:仅需要一个图片名称和图片url
import scrapy
class WheatherItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
number = scrapy.Field()
pic_url = scrapy.Field()
-
主要代码编写
import scrapy import re from wheather.items import WheatherItem class WeatherSpider(scrapy.Spider): name = 'weather' allowed_domains = ['www.weather.com.cn'] start_urls = ['http://www.weather.com.cn/'] count =0 total=0 def parse(self, response): html = response.text #获取所有网页的的连接 urlList = re.findall('<a href="(.*?)" ', html, re.S) for url in urlList: self.url = url try: yield scrapy.Request(self.url, callback=self.picParse) except Exception as e: print("err:", e) pass #设定爬取3页的图片即可 if(self.count>=3): break def picParse(self, response): #找到所有的图片 imgList = response.xpath("//img/@src") # imgList = re.findall(r'<img.*?src="(.*?)"', response.text, re.S) for k in imgList: k=k.extract() #最多53张图片 if self.total > 53: return try: item = WheatherItem() item['pic_url'] = k item['number'] = self.total self.total += 1 yield item except Exception as e: print(e) # pass -
pipeline编写 (单线程版本),编写的辅助函数download是为了获取不同图片的后缀名,使得图片能够顺利保存下来
import urllib.request
def download(url,count):
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"
}
try:
if(url[len(url)-4]=="."):#获取文件后缀名
ext=url[len(url)-4:]
else:
ext=""
req =urllib.request.Request(url,headers=headers)
data=urllib.request.urlopen(req,timeout=15)
data=data.read()
with open(".\\images\\"+str(count)+ext,"wb") as fp:
fp.write(data)
print("downloaded "+str(count)+ext)
except Exception as err:
print(err)
class WheatherPipeline:
def open_spider(self, spider):
pass
def process_item(self, item, spider):
img_url = item['pic_url']
number = item['number']
download(img_url,number)
return item
def close_spider(self,spider):
pass
- 多线程版本
import urllib.request
def download(url,count):
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"
}
try:
if(url[len(url)-4]=="."):#获取文件后缀名
ext=url[len(url)-4:]
else:
ext=""
req =urllib.request.Request(url,headers=headers)
data=urllib.request.urlopen(req,timeout=15)
data=data.read()
with open(".\\images\\"+str(count)+ext,"wb") as fp:
fp.write(data)
print("downloaded "+str(count)+ext)
except Exception as err:
print(err)
class WheatherPipeline:
def open_spider(self, spider):
pass
# self.threads=[]
# self.count=0
def process_item(self, item, spider):
img_url = item['pic_url']
number = item['number']
T = threading.Thread(target=download, args=(img_url, number))
T.setDaemon(False)
T.start()
self.threads.append(T)
self.count += 1
return item
def close_spider(self,spider):
for thread in self.threads:
thread.join()
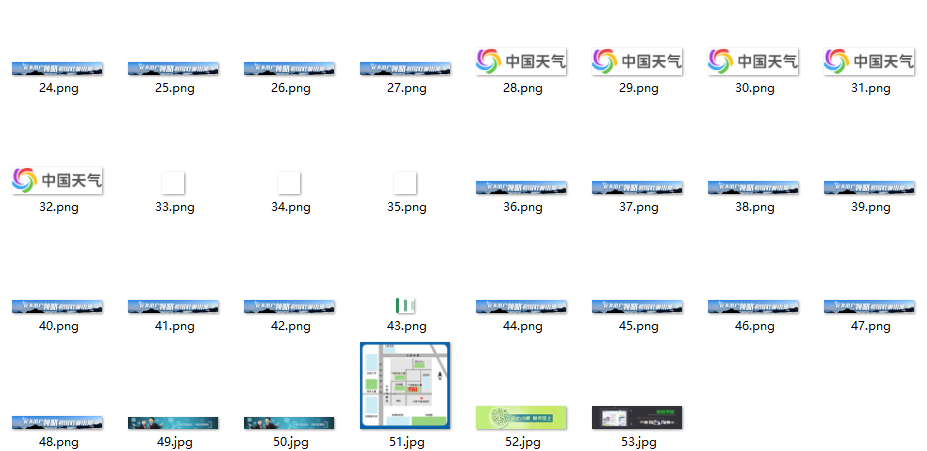
输出结果 限定53张图片(学号尾号53)
心得体会
难点在于如何实现全站的爬取吧,会卡住的地方在于spider需要编写两个parse函数,一个实现全站连接的获取,一个实现对单个页面的图片的爬取,如果掌握的这个写法,这道题就比较简单了。还有就是编写代码的过程会遇到不同的bug吧,需要自己耐心去debug
作业二
作业内容
要求:
-
熟练掌握scrapy中的item,pipeline 数据序列化输出方法;Scrapy+Xpath
-
MySQL数据库存储技术路线爬取股票先关信息
-
网站:东方财富网
输出信息:
- MySQL数据库存储和输出格式如下,表头应该是英文名命名,自定义设计
思路解析:之前爬取过东方财富网的网站,只需要重构一一下代码就可以使用,思路也是比较清晰,先编写item,编写主体代码,然后在pipeline将数据写入到数据库中
主体代码
import scrapy
import json
from gupiao.items import GupiaoItem
class WmoneySpider(scrapy.Spider):
name = 'wmoney'
allowed_domains = ['quote.eastmoney.com']
total_page_num=0
base_url = r'http://36.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124017913335698798893_1696658430311&pn={}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1696658430312'
start_urls = [base_url.format(1)]
def parse(self, response):
content = response.text
# print(content)
temp_file = content
# temp_file = str(temp_file.decode('utf-8'))
temp_file = temp_file.split('(', maxsplit=1)[1]
temp_file = temp_file[:-2]
# print(a)
json_file = json.loads(temp_file)
# print(json_file)
data_list = json_file['data']['diff']
for data in data_list:
dic=GupiaoItem()
dic['name']= str(data['f14'])
dic['price']=str(data['f2'])
dic['attr1']=str(data['f3']) + "%"
dic['attr2']=str(data['f4'])
dic['attr3']=str(data['f5'] / 1000.0)
dic['attr4']=str(data['f6'] / 100000000.0)
dic['attr5']=str(data['f7']) + "%"
dic['attr6']=str(data['f15'])
dic['attr7']=str(data['f16'])
dic['attr8']=str(data['f17'])
dic['attr9']=str(data['f18'])
dic['attr10']=str(data['f10'])
dic['attr11']=str(data['f12'])
print(dic)
yield dic
item
import scrapy
class GupiaoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name =scrapy.Field()
price = scrapy.Field()
attr1= scrapy.Field()
attr2 = scrapy.Field()
attr3 = scrapy.Field()
attr4 = scrapy.Field()
attr5 = scrapy.Field()
attr6 = scrapy.Field()
attr7 = scrapy.Field()
attr8 = scrapy.Field()
attr9 = scrapy.Field()
attr10= scrapy.Field()
attr11 = scrapy.Field()
pipeline的编写:主要在于添加了一个创建数据库的操作,在打开爬虫之前开始数据库,然后在爬虫结束的使用关闭数据库,中间的process_item就是将数据插入到数据库当中
import sqlite3
class GupiaoPipeline:
def open_spider(self, spider):
self.con=sqlite3.connect("G:\database\gupiao.db")
self.cursor=self.con.cursor()
try:
self.cursor.execute("create table if not exists gupiao "
"(name varchar(10),price varchar(10),attr1 varchar(10),"
"attr2 varchar(10),attr3 varchar(10),attr4 varchar(10),attr5 varchar(10),attr6 varchar(10),attr7 varchar(10),attr8 varchar(10),attr9 varchar(10),attr10 varchar(10),attr11 varchar(10),"
" primary key (name))")
except:
self.cursor.execute("delete from gupiao")
def process_item(self, item, spider):
insert = "insert into gupiao (name,price,attr1,attr2,attr3,attr4,attr5,attr6,attr7,attr8,attr9,attr10,attr11) " \
"values (?,?,?,?,?,?,?,?,?,?,?,?,?)"
self.cursor.execute(insert,(item['name'],item['price'],item['attr1'],item['attr2'],item['attr3'],item['attr4'],item['attr5'],item['attr6'],item['attr7'],item['attr8'],item['attr9'],item['attr10'],item['attr11']))
return item
def close_spider(self, spider):
self.con.commit()
self.con.close()
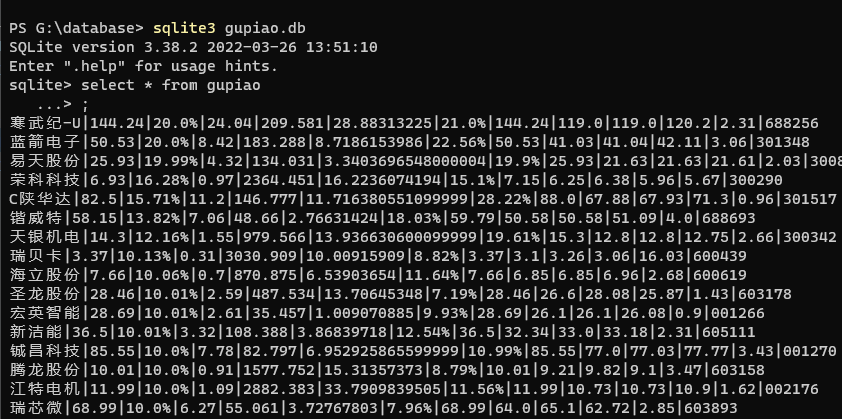
输出结果:通过windows自带的sqlite3查看数据
心得体会
这一题没有什么难点,就是上一次作业的代码的重构,感觉就是一个无情的码字机器
作业三
作业内容
要求:
- 熟练掌握scrapy中的item,pipeline数据的序列化输出方法
- 使用scrapy框架+Xpath_+MySQL数据库存储技术路线爬取外汇网站
候选网站: 招商银行网
输出信息:MySQL数据库存储和输出格式
思路解析:
总体思路和作业二差不多,无非就是html解析的部分不一样,但是有个问题,scrapy的response获取不到全部的数据,需要我们重新别写一个response返回给spider,需要到mid
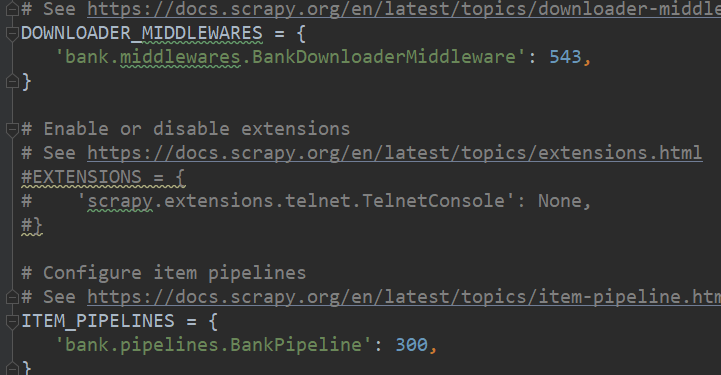
首先是setting的设置:需要到setting中将pipeline和middleware打开
编写item文件
import scrapy
class BankItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
attr1= scrapy.Field()
attr2=scrapy.Field()
attr3=scrapy.Field()
attr4= scrapy.Field()
attr5=scrapy.Field()
编写pipeline: 和作业2一样,将数据都插入到数据裤裆中
import sqlite3
class BankPipeline:
def open_spider(self, spider):
self.con=sqlite3.connect("G:\database\\bank.db")
self.cursor=self.con.cursor()
try:
self.cursor.execute("create table if not exists bank "
"(name varchar(10),attr1 varchar(10),"
"attr2 varchar(10),attr3 varchar(10),attr4 varchar(10),attr5 varchar(10),"
" primary key (name))")
except:
self.cursor.execute("delete from gupiao")
def process_item(self, item, spider):
insert = "insert into bank(name,attr1,attr2,attr3,attr4,attr5) " \
"values (?,?,?,?,?,?)"
self.cursor.execute(insert,(item['name'],item['attr1'],item['attr2'],item['attr3'],item['attr4'],item['attr5']))
return item
def close_spider(self, spider):
self.con.commit()
self.con.close()
编写middleware.py文件:在process_response重新使用selenium模拟浏览器返回数据,封装response返回给spider
import time
from scrapy.http import HtmlResponse
class BankDownloaderMiddleware:
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None
def process_response(self, request, response, spider):
driver = spider.driver
driver.get(request.url)
time.sleep(1.5)
content = driver.page_source
new_response = HtmlResponse(url=request.url, body=content,encoding='utf-8',request=request)
return new_response
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
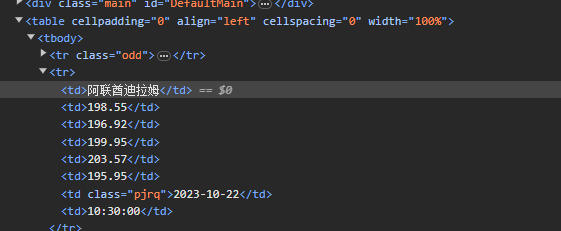
打开网站,观察单条数据html标签
主体代码编写:
import scrapy
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from bank.items import BankItem
class ZsyhSpider(scrapy.Spider):
name = 'zsyh'
allowed_domains = ['www.boc.cn']
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
def __init__(self): #爬虫初始化
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver_path = r'G:\Chrome Driver\chromedriver-win64\chromedriver.exe'
driver_service = Service(driver_path)
self.driver = webdriver.Chrome(service=driver_service, options=chrome_options)
def close(self,spider):
self.driver.quit()
def parse(self, response):
response.enconding ='utf-8'
table = response.xpath('/html/body/div/div[5]/div[1]/div[2]/table/tbody/tr')
print("==========================================")
# print(table)
for t in table[1:]:
item = BankItem()
# print(tr.xpath('.//td[1]/text()').extract())
item['name'] = t.xpath('.//td[1]/text()').extract_first()
item['attr1'] = t.xpath('.//td[2]/text()').extract_first()
item['attr2'] = t.xpath('.//td[3]/text()').extract_first()
item['attr3'] = t.xpath('.//td[4]/text()').extract_first()
item['attr4'] = t.xpath('.//td[5]/text()').extract_first()
item['attr5'] = t.xpath('.//td[6]/text()').extract_first()
yield item
# print("==================================================")
输出结果:
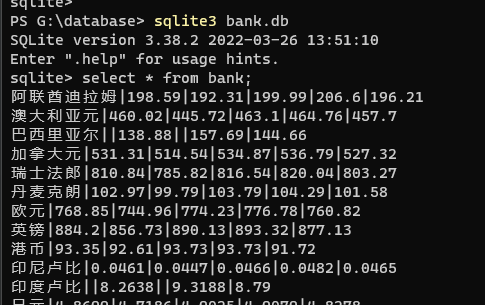
心得体会
这一题的难点在于,需要重新编写middleware,使用selenium模拟浏览器获取数据然后封装成response返回给spider去解析,如果知道这一点那么这一题就不是很难了