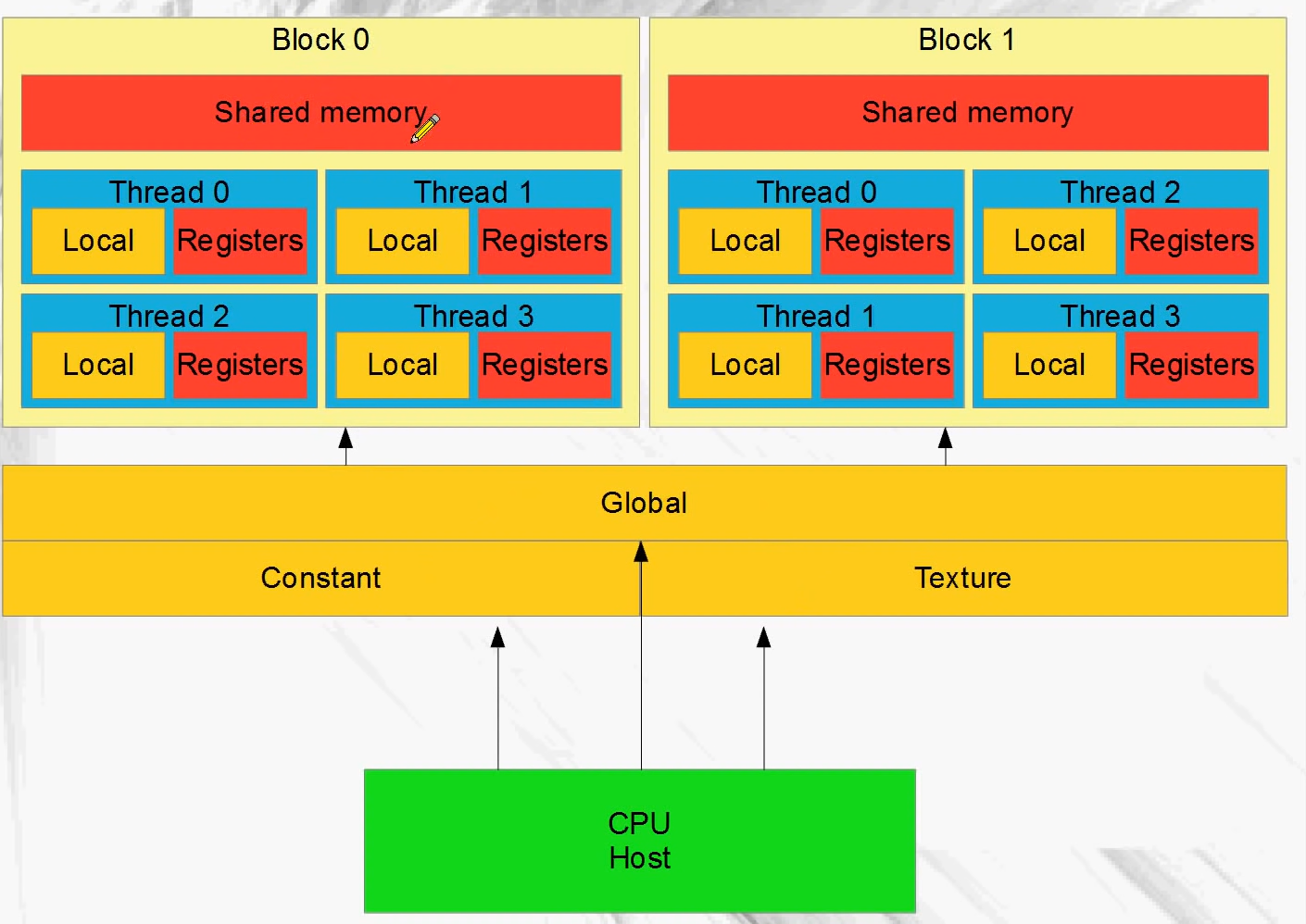
Global
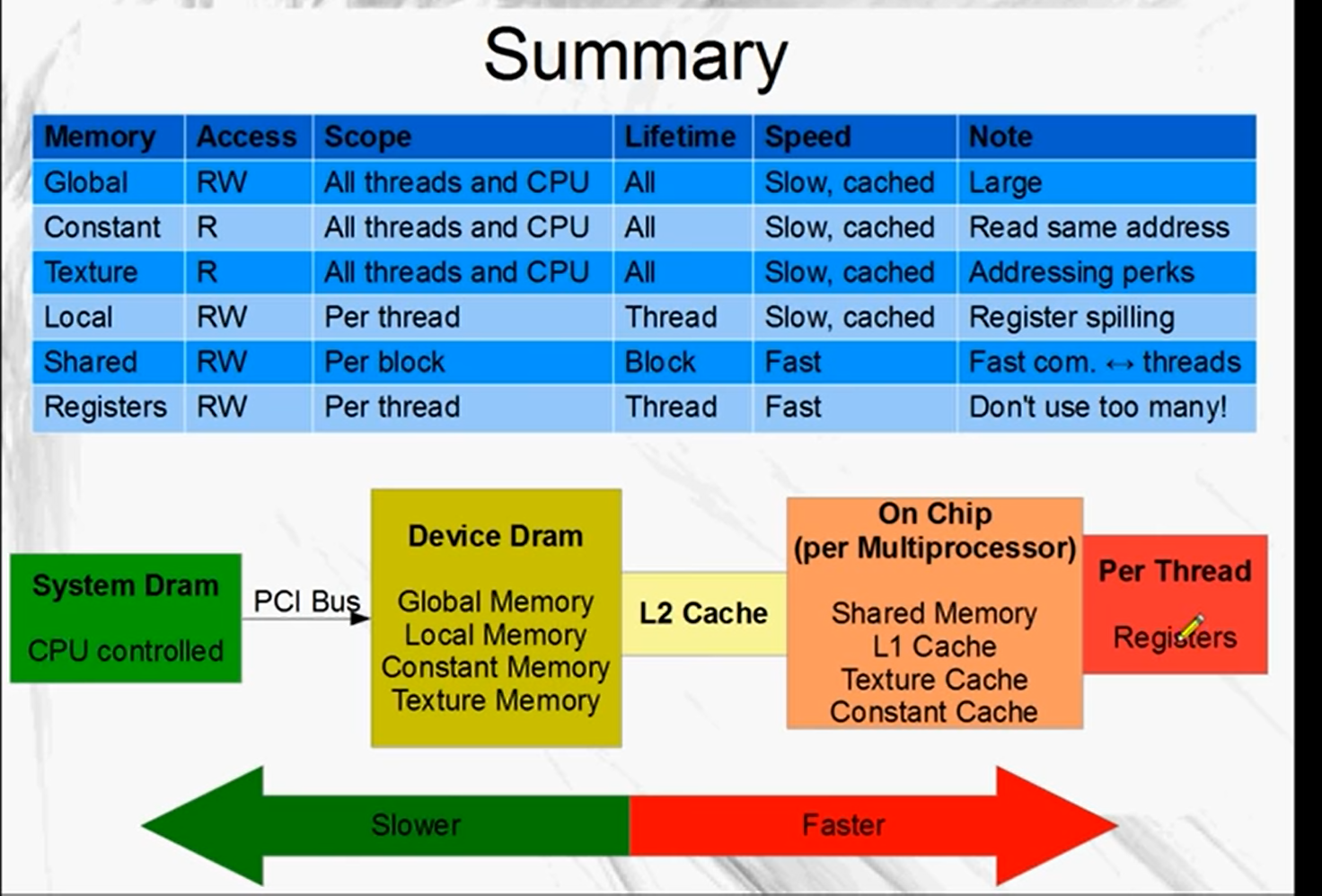
There's a large amount of global memory. It's slower to access than other memory like shared and registers.
All running threads can read and write global memory and so can the CPU.
The functions cudaMalloc, cudaFree, cudaMemcpy, cudaMemset all deal with global memory.
This is the main memory store of the GPU, every byte is addressable.
It is persistent across kernel calls.
For cards with compute capability 2.0 or higher, it is cached.
Local
This is also part of the main memory of the GPU, so it's generally slow.
Local memory is used automatically by NVCC when we run out of registers or when registers cannot be used. This is called register spilling.
It happens if there's too many variables per thread to use registers or if kernels use structures.
Also, array that aren't indexed with constants use local memory since registers don't have addresses, a memory space that's addressable must be used
The scope for local memory is per thread.
Local memory is cached in an L1 then an L2 cache, so register spillling may not mean a dramatic performance decrease on compute capability 2.0 and up.
Caches L1 and L2

On compute capability 2.0 and up, there's an L1 cache per multiprocessor. There's also an L2 cache which is shared between all multiprocessors.
Global and local memory use these.
The L1 is very fast, shared memory speeds. The L1 and shared memory are actually the same bytes. the can be configured to be 48k shared and 16k of L1 or 16k of shared and 48k of L1.
All global memory accesses go through the L2 cache, including those by the CPU.
You can turn caching on and off with a compiler option.
Texture and constant memory have their own separate caches.
Constant
This memory is also part of the GPU's main memory. It has its own cache. Not related to the L1 and L2 of global memory.
All threads have access to the same constant memory but they can only read, they can't write to it.
The CPU(host) sets the values in constant memory before launching the kernel.
It is very fast(register and shared memory speeds) even if all running threads in a warp read exactly the same address.
It's small, there's only 64k of constant memory.
All running threads share constant memory.
In graphics programming, this memory holds the constants like the model, view and projection matrices.
In graphics programming, this memory holds the constants like the model, view and projection matrices.
Texture
Texture memory resides in device memory also. It has its own cache.
It is read only to the GPU, the CPU sets it up.
Texture memory has many extra addressing tricks because it is designed for indexing(called texture fetching) and interpolating pixels in a 2D image.
The texture cache has a lower bandwidth than global memory's L1 so it might be better to stick to L1.
Shared
Shared memory is very fast(register speeds). It is shared between threads of each block.
Bank conflicts can slow access down.
It's fastest when all threads read from different banks or all thread of a warp read exactly the same value.
Successive dword(4bytes) reside in different banks. There's 16 banks in comput capability 1.0 and 32 in 2.0
Shared memory is used to enable fast communication between threads in a block.
Register
Registers are the fastest memory on the GPU.
The variables we declare in a kernel will use registers unless we run out or the can't be stored in registers. then local memory will be used.
Register scope is per thread. Unlike CPU, there's thousands of registers in a GPU.
Carefully selecting a few register instead of using 50 per thread can dasily double the number of concurrent blocks the GPU can execute and threrfore increase performance substantially.
Summary